













Ceph運維告訴你分布式存儲的那些“坑”
過去兩年,我的主要工作都在Hadoop這個技術棧中,而最近有幸接觸到了Ceph。我覺得這是一件很幸運的事,讓我有機會體驗另一種大型分布式存儲解決方案,可以對比出HDFS與Ceph這兩種幾乎完全不同的存儲系統分別有哪些優缺點、適合哪些場景。
對于分布式存儲,尤其是開源的分布式存儲,站在一個SRE的角度,我認為主要為商業公司解決了如下幾個問題:
- 可擴展,滿足業務增長導致的海量數據存儲需求;
- 比商用存儲便宜,大幅降低成本;
- 穩定,可以駕馭,好運維。
總之目標就是:又好用,又便宜,還穩定。但現實似乎并沒有這么美好……

本文將從這三個我認為的根本價值出發,分析我運維Ceph的體會,同時對比中心化的分布式存儲系統,比如HDFS,橫向說一說。
一、可擴展性
Ceph聲稱可以無限擴展,因為它基于CRUSH算法,沒有中心節點。 而事實上,Ceph確實可以無限擴展,但Ceph的無限擴展的過程,并不完全美好。
首先梳理一下Ceph的寫入流程。Ceph的新對象寫入對象,需要經過PG這一層預先定義好的定額Hash分片,然后PG,再經過一次集群所有物理機器硬盤OSD構成的Hash,落到物理磁盤。
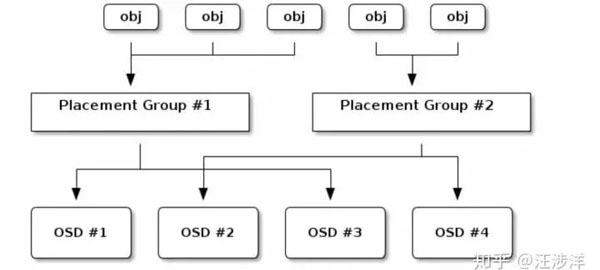
因此,Ceph的所有對象,是先被pre-hash到了一個固定數量的桶(PG)當中,然后根據集群的整體物理架構crushmap,選擇落在具體的機器磁盤上。
這對擴容有什么影響呢?
1.擴容粒度
我給擴容粒度的定義是:一次可以擴容多少臺機器。
Ceph在實踐中,擴容受“容錯域”制約,一次只能擴一個“容錯域”。
容錯域就是:副本隔離級別,即同一個replica的數據,放在不同的磁盤/機器/Rack/機房。
容錯域這個概念,在很多存儲方案里都有,包括HDFS。為什么Ceph會受影響呢?因為Ceph沒有中心化的元數據結點,導致數據放置策略受之影響。
數據放置策略,即一份數據replica,放在哪臺機器,哪塊硬盤。
中心化的,比如HDFS,會記錄每一個文件,下面每一個數據塊的存放位置。這個位置是不會經常變動的,只有在1.文件新創建;2.balancer重平衡;3.有硬盤壞了,中心節點針對損壞硬件上的數據重新放置時才會改變。
而Ceph,因為去中心化,導致容納數據的PG的位置,會根據crushmap的變化而變化。 來了新的機器、硬盤,就要為一些受影響的PG計算新的位置。 基于一致性哈希的技術,在擴容時也要面臨同樣的問題。
因此,Ceph擴容需要PG們調整。正因為這個調整,導致Ceph受“容錯域”制約。
例如:有一個PG,是3副本,Ceph集群有一個配置是PG要向外提供正常服務,至少有2個完整的副本。而當這個數據pool的容錯域是host時,同時擴容2臺機器,一些PG就有可能把3副本中的2個都映射到2臺新機器上去。而這2個副本都是新副本,都沒有完整的最新數據。剩下的一個副本,無法滿足老機器至少有完整的2副本的要求,也就不能提供正常讀寫服務了。
這就會導致這個PG里的所有對象,停止對外服務。
作為admin,當然可以把配置降低,把數據pool的min_size下降為1。但這種配置,即使在正常情況下,因為磁盤故障,都有可能丟失數據,因此一般不會這樣設置。
那在擴容時,一次只擴容一臺機器時,是不是就安全了呢?
這樣就能保證所有PG都至少在老機器有2個完整的副本了。可是,即使是擴容一臺機器,也還要面臨擴容時老機器中有硬盤壞掉,導致PG的完整副本又下降為1的極端情況發生。
雖然PG有可能不能服務,但數據的持久性是沒有問題的。國內AT的云,服務可靠性都沒有做得特別高,做到像持久性那樣3個9、4個9。雖然我不確定這兩朵大云里的對象存儲是不是使用的Ceph,但只要是基于類似CRUSH算法,或者一致性哈希等類似的去中心化技術實現的對象存儲,應該都會面對部分數據暫時不可服務的情況。
我們拋開最極端的情況,即假設在擴容時,以一個“容錯域”加入機器時,暫時沒有磁盤損壞。那么有沒有辦法可以提升擴容粒度呢?
辦法是,在開始規劃Ceph集群時,設定好更大層次的“容錯域”,比如Rack。 可以是真實的Rack,即使沒有也可以是邏輯的Rack。這樣擴容時,可以擴一個邏輯“容錯域”,就可以打破擴一臺機器的限制,擴一整個Rack,至少有好幾臺機器。
Tips:這里我沒有講為什么擴容粒度小是個不好的事。其實在很多公司,數據的日均增長量是很有可能大于一臺機器的存儲容量的。這就會造成擴容速度趕不上寫入速度的尷尬局面。這對于開始沒有設計好,圖快速deploy而架設的集群,在后期是一個不小的傷害。
2.擴容時crushmap的改變
Ceph是根據crushmap去放置PG的物理位置的,倘若在擴容進行了一半時,又有硬盤壞掉了,那Ceph的crushmap就會改變,Ceph又會重新進行PG的re-hash,很多PG的位置又會重新計算。如果運氣比較差,很可能一臺機器的擴容進度被迫進行了很久才回到穩定的狀態。
這個crushmap改變導致的Ceph重平衡,不單單在擴容時,幾乎在任何時候,對一個大的存儲集群都有些頭疼。在建立一個新集群時,硬盤都比較新,因此故障率并不高。但是在運行了2-3年的大存儲集群,壞盤真的是一個稀松平常的事情,1000臺規模的集群一天壞個2-3塊盤很正常。crushmap經常變動,對Ceph內部不穩定,影響真的很大。隨之而來,可能是整體IO的下降(磁盤IO被反復的rebalance占滿),甚至是某些數據暫時不可用。
所以總的來說,Ceph的擴容是有那么一丁點不痛快的。Ceph確實提供了無限的擴展能力,但擴容過程并不平滑,也不完全可控。crushmap的設計,達到了很好的去中心化效果,但也給集群大了之后的不穩定埋下了一個坑。
而對比中心化元數據的HDFS,在擴容時幾乎無限制,你可以撒歡地擴容。老數據的搬遷,重平衡都會由單獨的job來處理,處理也很高效。它采用了滿節點和空節點兩兩配對的方式,從老節點移動足夠的數據,填滿新機器即可。中心化元數據在擴容&重平衡時,反而變成了一個優點。
3.擴容到一定量級后,PG數量需調整
如上文的Ceph數據寫入流程圖所示,Ceph對象的最小放置單位是PG,PG又會被放在硬盤上,PG理論上肯定是越大越好。因為這樣數據的分片隨機性更好,更能掩蓋偽隨機造成的單塊盤容量偏差過大問題。但PG數量在現實中不是越大越好的,它要受限于硬件,如CPU、內存、網絡。 因此我們在規劃PG數時,不會盲目調大,一般社區也是建議200pg / osd。
假設我們現在有10臺機器,每臺一塊硬盤一共10塊盤,有1024個PG,PG都是單副本,那么每個盤會存100個PG。此時這個設置非常健康,但當我們集群擴容到1000臺機器,每臺硬盤就只放一個PG了,這會導致偽隨機造成的不平衡現象放大。因此,admin就要面臨調整PG數量,這就帶來了問題。
調PG,基本也就意味著整個集群會進入一種嚴重不正常的狀態。幾乎50%的對象,涉及到調整后的PG都需要重新放置物理位置,這會引起服務質量的嚴重下降。
雖然調整PG不是一個經常性的事件,但在一個大型存儲,隨著發展,不可避免會經歷這個大考。
二、比商用存儲便宜
我們所說的和商業存儲比較,一般就是和EMC、IBM這類硬件軟件存儲解決方案廠家,或者云解決方案Aliyun、AWS之類的對比。
自己建設機房,當然在硬件單價上更為便宜,但需要考慮綜合成本,包括:1.硬件成本;2.自養運維人員成本;3.服務質量由一般向好慢慢收斂。
人的成本這種玄學的問題,我就不談了,本文只談Ceph在硬件成本這塊有什么有趣的地方。講道理,自己建機房,硬件成本應該是毫無疑問的便宜,那么Ceph在這里有什么特殊呢?
問題在于,集群可靠利用率。
集群可靠利用率,即整個集群在容量達到某個水平時不可對外服務,或者說不能保持高可用的服務。
打個比方,我們的手機閃存/電腦硬盤,是不是到99%了還能正常工作? 當然,因為是本地存儲嘛。對于云解決方案,也天然就沒有這個問題了。
對于商用存儲解決方案,比如EMC的Isilon分布式文件系統,存儲容量達到甚至98-99%,仍能對外提供服務。
對于HDFS,在95%以下,存儲也能很好地對外提供服務。跑在HDFS上的Hadoop Job,會因為沒辦法寫入本地而掛掉。
而對于Ceph,在這一塊表現得并不好。根據經驗,在集群整體使用率達到70%后,就有可能進入不穩定的狀態。
這是為什么呢?問題在于,去中心化帶來的tradeoff。
Ceph是去中心化的分布式解決方案,對象的元數據是分布在各臺物理機上的。因此所有對象,是被“偽隨機”地分配到各個磁盤上的。偽隨機不能保證所有磁盤的完全均勻分配,不能降低很多大對象同時落在一塊盤上的概率(我理解加入一層PG,又使PG多replica,是可以讓磁盤的方差變小的),因此總有一些磁盤的使用率會高出均值。
在集群整體使用率不高時,都沒有問題。而在使用率達到70%后,就需要管理員介入了。因為方差大的盤,很有可能會觸及95%這條紅線。admin開始調低容量過高磁盤的reweight,但如果在這一批磁盤被調整reweight沒有結束時,又有一些磁盤被寫滿了,那管理員就必須被迫在Ceph沒有達到穩定狀態前,又一次reweight過高的磁盤。 這就導致了crushmap的再一次變更,從而導致Ceph離穩定狀態越來越遠。而此時擴容又不及時的話,更是雪上加霜。
而且之前的crushmap的中間狀態,也會導致一些PG遷移了一半,這些“不完整的”PG并不會被馬上刪除,這給本來就緊張的磁盤空間又加重了負擔。
有同學可能會好奇,一塊磁盤滿了,Ceph為什么就不可用了。Ceph還真的就是這樣設計的,因為Ceph沒法保證新的對象是否落在空盤而不落在滿盤,所以Ceph選擇在有盤滿了時,就拒絕服務。
在我咨詢了一些同事和業界同行后,基本上大家的Ceph集群都是在達到50%使用率時,就要開始準備擴容了。這其實是挺不省錢的,因為必須空置一大批機器的存儲資源。并且未來集群的規模越大,空置效應就會放得越大,意味著浪費的錢/電費越多。
而很多傳統的中心化的分布式存儲系統,由于寫入時可以由主控節點選擇相對空閑的機器進行寫入,因此不會存在某些磁盤滿了,導致整個集群不可寫入的問題。也正是如此,才可以做到整體寫入到95%了,仍然保持可用性。
我沒有真正核算過這種效應帶來的成本waste,但至少看上去是有點不夠完美的。
打個比方,當我預估有50pb的存儲時,需要300臺物理機了,我居然要提前采購好另外200-300臺物理機,還不能馬上用上,還要插上電。
因此Ceph也并不一定會很便宜,去中心化的分布式存儲也并沒有那么美好。
但中心化的危害,似乎又是沒有爭議的問題(單點問題、中心節點擴展性問題等等 ),因此分布式里真的沒有銀彈,只有tradeoff。
還有一種辦法,就是Ceph的集群按整個pool來擴容,一個pool滿了,就不擴容了,開新的pool,新的對象只準寫新的pool,老的pool的對象可以刪除,可以讀取。 這乍看之下是一個很棒的解決方案,但仔細想想,這和HDFS的federation,和MySQL的分庫分表,做前端的大Hash,似乎沒有區別。
這也就談不上是“無限擴容”了,而且還需要寫一個前面的路由層。
三、穩定,可駕馭,好運維
這個穩定好運維,基本就看團隊的硬實力了。對開源軟件是否熟悉,是否有經驗,真的會有很大不同。
同時,這還受開源社區文檔質量的影響。Ceph的開源社區還是不錯的,Red Hat收購并主導了Ceph之后,重新整理了Red Hat版本的Ceph文檔,我認為讀起來邏輯感更強。
在公司內積累自己的運維文檔也很關鍵。一個新手很可能會犯很多錯誤,導致事故發生。但對于公司,踩了一次的坑,就盡量不要再踩第二次了。這對公司的技術積累管理、技術文檔管理、核心人才流失管理,都產生了一些挑戰。
我在Ceph運維中,曾遇到一個棘手的問題。即Ceph集群達到了80%后,經常有磁盤變滿,然后管理員就要介入,調低過高磁盤的reweight。而在這臺磁盤使用量沒降下來之前,又有更多的磁盤被寫滿了,管理員就又要介入,又調整reweight,Ceph至此就再也沒有進入過穩定狀態了,管理員還必須時時刻刻盯著集群。這導致了極大的運維投入,所以像這種事情一定要避免,這對運維人員的士氣是很大的傷害。
那么,是否應該在早期進行容量預警,啟動采購流程呢?
可是這樣做,又回到了資源浪費的問題上。
此外,Ceph的對象是沒有last_access_time這種元數據的,因此Ceph對象的冷/熱之分,需要二次開發,做額外的工作。集群大了之后,如何清理垃圾數據、如何歸檔冷數據,也帶來了不小的挑戰。
總結思考
1、Ceph確實有無限擴容的能力,但需要良好的初始規劃,擴容過程也并不完美。中心化造就了擴容的上限是單臺master結點的物理極限,造就了無限擴容的理論基礎,但實際擴容時,服務質量會受嚴重制約。
2、Ceph有些浪費硬件,成本核算時要考慮更多。
3、Ceph本身的去中心化設計犧牲了不少元數據,比如lastacesstime,這給未來數據治理帶來了壓力,也需要更強的團隊來運維和二次開發。積累運維經驗,積累運維團隊,是駕馭好開源分布式存儲的核心。對手隨著時間越來越強大,應對的運維團隊也需要越來越好,才能讓生產關系匹配生產力的要求。
4、技術本身沒有絕對的好壞,不同的技術是用來解決不同問題的。但在場景下,技術是有好壞的。因為在場景下,你有了立場,就有了亟待解決的問題的優先級,也就一定能按優先級選擇出最適合你的技術。















