讓我們了解 Ceph 分布式存儲
前言
最近在學習kubernetes過程中,想實現pod數據的持久化。在調研的過程中,發現ceph在最近幾年發展火熱,也有很多案例落地企業。在選型方面,個人更加傾向于社區火熱的項目,GlusterFS、Ceph都在考慮的范圍之內,但是由于GlusterFS只提供對象存儲和文件系統存儲,而Ceph則提供對象存儲、塊存儲以及文件系統存儲。懷著對新事物的向往,果斷選擇Ceph來實現Ceph塊存儲對接kubernetes來實現pod的數據持久化。
一、初始Ceph
1.1了解什么是塊存儲/對象存儲/文件系統存儲?
直接進入主題,ceph目前提供對象存儲(RADOSGW)、塊存儲RDB以及CephFS文件系統這3種功能。對于這3種功能介紹,分別如下:
1.對象存儲,也就是通常意義的鍵值存儲,其接口就是簡單的GET、PUT、DEL和其他擴展,代表主要有Swift、S3以及Gluster等;
2.塊存儲,這種接口通常以QEMUDriver或者KernelModule的方式存在,這種接口需要實現Linux的BlockDevice的接口或者QEMU提供的BlockDriver接口,如Sheepdog,AWS的EBS,青云的云硬盤和阿里云的盤古系統,還有Ceph的RBD(RBD是Ceph面向塊存儲的接口)。在常見的存儲中DAS、SAN提供的也是塊存儲;
3.文件存儲,通常意義是支持POSIX接口,它跟傳統的文件系統如Ext4是一個類型的,但區別在于分布式存儲提供了并行化的能力,如Ceph的CephFS(CephFS是Ceph面向文件存儲的接口),但是有時候又會把GlusterFS,HDFS這種非POSIX接口的類文件存儲接口歸入此類。當然NFS、NAS也是屬于文件系統存儲;
1.2Ceph組件介紹
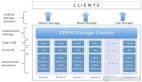
從下面這張圖來簡單學習下,Ceph的架構組件。(提示:本人在學習過程中所繪,如果發現問題歡迎留言,不要噴我喲)
Monitor,負責監視整個集群的運行狀況,信息由維護集群成員的守護程序來提供,各節點之間的狀態、集群配置信息。Cephmonitormap主要包括OSDmap、PGmap、MDSmap和CRUSH等,這些map被統稱為集群Map。cephmonitor不存儲任何數據。下面分別開始介紹這些map的功能:
- Monitormap:包括有關monitor節點端到端的信息,其中包括Ceph集群ID,監控主機名和IP以及端口。并且存儲當前版本信息以及最新更改信息,通過"cephmondump"查看monitormap。
- OSDmap:包括一些常用的信息,如集群ID、創建OSDmap的版本信息和最后修改信息,以及pool相關信息,主要包括pool名字、pool的ID、類型,副本數目以及PGP等,還包括數量、狀態、權重、最新的清潔間隔和OSD主機信息。通過命令"cephosddump"查看。
- PGmap:包括當前PG版本、時間戳、最新的OSDMap的版本信息、空間使用比例,以及接近占滿比例信息,同事,也包括每個PGID、對象數目、狀態、OSD的狀態以及深度清理的詳細信息。通過命令"cephpgdump"可以查看相關狀態。
- CRUSHmap:CRUSHmap包括集群存儲設備信息,故障域層次結構和存儲數據時定義失敗域規則信息。通過命令"cephosdcrushmap"查看。
- MDSmap:MDSMap包括存儲當前MDSmap的版本信息、創建當前的Map的信息、修改時間、數據和元數據POOLID、集群MDS數目和MDS狀態,可通過"cephmdsdump"查看。
OSD,CephOSD是由物理磁盤驅動器、在其之上的Linux文件系統以及CephOSD服務組成。CephOSD將數據以對象的形式存儲到集群中的每個節點的物理磁盤上,完成存儲數據的工作絕大多數是由OSDdaemon進程實現。在構建CephOSD的時候,建議采用SSD磁盤以及xfs文件系統來格式化分區。BTRFS雖然有較好的性能,但是目前不建議使用到生產中,目前建議還是處于圍觀狀態。
Ceph元數據,MDS。ceph塊設備和RDB并不需要MDS,MDS只為CephFS服務。
RADOS,ReliableAutonomicDistributedObjectStore。RADOS是ceph存儲集群的基礎。在ceph中,所有數據都以對象的形式存儲,并且無論什么數據類型,RADOS對象存儲都將負責保存這些對象。RADOS層可以確保數據始終保持一致。
librados,librados庫,為應用程度提供訪問接口。同時也為塊存儲、對象存儲、文件系統提供原生的接口。
ADOS塊設備,它能夠自動精簡配置并可調整大小,而且將數據分散存儲在多個OSD上。
RADOSGW,網關接口,提供對象存儲服務。它使用librgw和librados來實現允許應用程序與Ceph對象存儲建立連接。并且提供S3和Swift兼容的RESTfulAPI接口。
CephFS,Ceph文件系統,與POSIX兼容的文件系統,基于librados封裝原生接口。
簡單說下CRUSH,ControlledReplicationUnderScalableHashing,它表示數據存儲的分布式選擇算法,ceph的高性能/高可用就是采用這種算法實現。CRUSH算法取代了在元數據表中為每個客戶端請求進行查找,它通過計算系統中數據應該被寫入或讀出的位置。CRUSH能夠感知基礎架構,能夠理解基礎設施各個部件之間的關系。并且CRUSH保存數據的多個副本,這樣即使一個故障域的幾個組件都出現故障,數據依然可用。CRUSH算是使得ceph實現了自我管理和自我修復。
RADOS分布式存儲相較于傳統分布式存儲的優勢在于:
1.將文件映射到object后,利用ClusterMap通過CRUSH計算而不是查找表方式定位文件數據存儲到存儲設備的具體位置。優化了傳統文件到塊的映射和BlockMAp的管理。
2.RADOS充分利用OSD的智能特點,將部分任務授權給OSD,最大程度地實現可擴展。
二、安裝Ceph
2.1環境準備
##環境說明
主機IP功能
ceph-node01192.168.58.128 deploy、mon*1、osd*3
ceph-node02192.168.58.129 mon*1、osd*3
ceph-node03192.168.58.130 mon*1、osd*3
##準備yum源
- cd /etc/yum.repos.d/ && sudo mkdir bak
- sudo mv *.repo bak/
- sudo wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
- sudo wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
- sudo sed -i '/aliyuncs/d' /etc/yum.repos.d/CentOS-Base.repo
- sudo sed -i '/aliyuncs/d' /etc/yum.repos.d/epel.repo
- sudo sed -i 's/$releasever/7/g' /etc/yum.repos.d/CentOS-Base.repo
##添加Ceph源
- sudo cat <<EOF > /etc/yum.repos.d/ceph.repo
- [Ceph]
- name=Ceph packages for x86_64
- baseurl=https://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/
- enabled=1
- gpgcheck=1
- type=rpm-md
- gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
- [Ceph-noarch]
- name=Ceph noarch packages
- baseurl=https://mirrors.aliyun.com/ceph/rpm-jewel/el7/noarch/
- enabled=1
- gpgcheck=1
- type=rpm-md
- gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
- [ceph-source]
- name=Ceph source packages
- baseurl=https://mirrors.aliyun.com/ceph/rpm-jewel/el7/SRPMS/
- enabled=1
- gpgcheck=1
- type=rpm-md
- gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
- EOF
##配置免密鑰(略)
提示:如果使用普通用戶進行安裝,請授予用戶相關權限,如下:
a.將yangsheng用戶加入到sudo權限(yangshengALL=(ALL)NOPASSWD:ALL)
b.將/etc/sudoers中的“Defaultsrequiretty”注釋
2.2開始安裝
##安裝部署工具(在192.168.58.128執行如下操作)
- yum makecache
- yum -y install ceph-deploy
- ceph-deploy --version
- 1.5.39
##初始化monitor
- mkdir ceph-cluster && cd ceph-cluster
- ceph-deploy new ceph-node01 ceph-node02 ceph-node03
根據自己的IP配置向ceph.conf中添加public_network,并稍微增大mon之間時差允許范圍(默認為0.05s,現改為2s):
- # change default replica 3 to 2
- osd pool default size = 2
- public network = 192.168.58.0/24
- cluster network = 192.168.58.0/24
##安裝ceph
- ceph-deployinstallceph-node01ceph-node02ceph-node03
##開始部署monitor
- ceph-deploy mon create-initial
- [root@ceph-node01 ceph]# ls
- ceph.bootstrap-mds.keyring ceph.bootstrap-osd.keyring ceph.client.admin.keyring ceph-deploy-ceph.log rbdmap
- ceph.bootstrap-mgr.keyring ceph.bootstrap-rgw.keyring ceph.conf ceph.mon.keyring
查看集群狀態
- [root@ceph-node01 ceph]# ceph -s
- cluster b5108a6c-7e3d-4295-88fa-88dc825be3ba
- health HEALTH_ERR
- no osds
- monmap e1: 3 mons at {ceph-node01=192.168.58.128:6789/0,ceph-node02=192.168.58.129:6789/0,ceph-node03=192.168.58.130:6789/0}
- election epoch 6, quorum 0,1,2 ceph-node01,ceph-node02,ceph-node03
- osdmap e1: 0 osds: 0 up, 0 in
- flags sortbitwise,require_jewel_osds
- pgmap v2: 64 pgs, 1 pools, 0 bytes data, 0 objects
- 0 kB used, 0 kB / 0 kB avail
- 64 creating
提示:Monitor創建成功后,檢查集群的狀態,此時集群狀態并不處于健康狀態。
##開始部署OSD
- ### 列出節點所有磁盤信息
- ceph-deploy disk list ceph-node01 ceph-node02 ceph-node03
- ### 清除磁盤分區和內容
- ceph-deploy disk zap ceph-node01:sdb ceph-node02:sdb ceph-node03:sdb
- ### 分區格式化并激活
- ceph-deploy osd create ceph-node01:sdb ceph-node02:sdb ceph-node03:sdb
- ceph-deploy osd activate ceph-node01:sdb ceph-node02:sdb ceph-node03:sdb
此時,再次查看集群狀態
- [root@ceph-node01 ceph-cluster]# ceph -s
- cluster 86fb7c8b-9ad1-4eaf-a24c-0d2d9f36ab29
- health HEALTH_OK
- monmap e2: 3 mons at {ceph-node01=192.168.58.128:6789/0,ceph-node02=192.168.58.129:6789/0,ceph-node03=192.168.58.130:6789/0}
- election epoch 6, quorum 0,1,2 ceph-node01,ceph-node02,ceph-node03
- osdmap e15: 3 osds: 3 up, 3 in
- flags sortbitwise,require_jewel_osds
- pgmap v32: 64 pgs, 1 pools, 0 bytes data, 0 objects
- 100 MB used, 45946 MB / 46046 MB avail
- 64 active+clean
2.3清理環境
如果之前部署失敗了,不必刪除ceph客戶端,或者重新搭建虛擬機,只需要在每個節點上執行如下指令即可將環境清理至剛安裝完ceph客戶端時的狀態!強烈建議在舊集群上搭建之前清理干凈環境,否則會發生各種異常情況。
- sudo ps aux|grep ceph | grep -v "grep"| awk '{print $2}'|xargs kill -9
- sudo ps -ef|grep ceph
- sudo umount /var/lib/ceph/osd/*
- sudo rm -rf /var/lib/ceph/osd/*
- sudo rm -rf /var/lib/ceph/mon/*
- sudo rm -rf /var/lib/ceph/mds/*
- sudo rm -rf /var/lib/ceph/bootstrap-mds/*
- sudo rm -rf /var/lib/ceph/bootstrap-osd/*
- sudo rm -rf /var/lib/ceph/bootstrap-rgw/*
- sudo rm -rf /var/lib/ceph/tmp/*
- sudo rm -rf /etc/ceph/*
- sudo rm -rf /var/run/ceph/*
三、配置客戶端
3.1安裝客戶端
- ssh-copy-id 192.168.58.131
- ceph-deploy install 192.168.58.131
將Ceph配置文件復制到192.168.58.131。
- ceph-deploy config push 192.168.58.131
3.2新建用戶密鑰
客戶機需要ceph秘鑰去訪問ceph集群。ceph創建了一個默認的用戶client.admin,它有足夠的權限去訪問ceph集群。但是不建議把client.admin共享到所有其他的客戶端節點。這里我用分開的秘鑰新建一個用戶(client.rdb)去訪問特定的存儲池。
- cephauthget-or-createclient.rbdmon'allowr'osd'allowclass-readobject_prefixrbd_children,allowrwxpool=rbd'
為192.168.58.131上的client.rbd用戶添加秘鑰
- cephauthget-or-createclient.rbd|ssh192.168.58.131tee/etc/ceph/ceph.client.rbd.keyring
到客戶端(192.168.58.131)檢查集群健康狀態
- [root@localhost ~]# cat /etc/ceph/ceph.client.rbd.keyring >> /etc/ceph/keyring
- [root@localhost ~]# ceph -s --name client.rbd
- cluster 86fb7c8b-9ad1-4eaf-a24c-0d2d9f36ab29
- health HEALTH_OK
- monmap e2: 3 mons at {ceph-node01=192.168.58.128:6789/0,ceph-node02=192.168.58.129:6789/0,ceph-node03=192.168.58.130:6789/0}
- election epoch 6, quorum 0,1,2 ceph-node01,ceph-node02,ceph-node03
- osdmap e15: 3 osds: 3 up, 3 in
- flags sortbitwise,require_jewel_osds
- pgmap v32: 64 pgs, 1 pools, 0 bytes data, 0 objects
- 100 MB used, 45946 MB / 46046 MB avail
- 64 active+clean
3.3創建塊設備
- rbd create foo --size 4096 --name client.rbd # 創建一個 4096MB 大小的RADOS塊設備
- rbd create rbd01 --size 10240 --name client.rbd # 創建一個 10240MB 大小的RADOS塊設備
映射塊設備
- [root@localhost ceph]# rbd create rbd02 --size 10240 --image-feature layering --name client.rbd
- [root@localhost ceph]# rbd map --image rbd02 --name client.rbd /dev/rdb02
- /dev/rbd0
提示:在映射塊設備的時候,發生了如下錯誤。
- [root@localhost ceph]# rbd map --image rbd01 --name client.rbd /dev/rdb01
- rbd: sysfs write failed
- RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable".
- In some cases useful info is found in syslog - try "dmesg | tail" or so.
- rbd: map failed: (6) No such device or address
解決該辦法有多種方式,分別如下所示:
1.在創建的過程中加入如下參數"--image-featurelayering"也解決該問題。
2.手動disable掉相關參數,如下所示:
- rbdfeaturedisablefooexclusive-lock,object-map,fast-diff,deep-flatten
3.在每個ceph節點的配置文件中,加入該配置項"rbd_default_features=1"。
3.4檢查被映射的塊設備
- [root@localhost ceph]# rbd showmapped --name client.rbd
- id pool image snap device
- 0 rbd rbd02 - /dev/rbd0
創建并掛載該設備
- fdisk -l /dev/rbd0
- mkfs.xfs /dev/rbd0
- mkdir /mnt/ceph-disk1
- mount /dev/rbd1 /mnt/ceph-disk1
驗證
- [root@localhost ceph]# df -h /mnt/ceph-disk1/
- 文件系統 容量 已用 可用 已用% 掛載點
- /dev/rbd0 10G 33M 10G 1% /mnt/ceph-disk1
一個ceph塊設備就創建完成。