WOT張阜興:知乎容器平臺演進及與大數據融合實踐
原創【51CTO.com原創稿件】2018年5月18-19日,由51CTO主辦的全球軟件與運維技術峰會在北京召開。來自全球企業的技術精英匯聚北京,暢談軟件技術前沿,共同探索運維技術的新邊界。而在本次大會上,除了眾星云集的主論壇環節,12場分論壇更是各具特色,在19日下午的“開源與容器技術”分論壇上,來自知乎計算平臺負責人張阜興發表了題為“知乎容器平臺演進及與大數據融合實踐”的精彩演講。

知乎計算平臺負責人張阜興演講
知乎計算平臺負責人張阜興碩士畢業于中科院計算所,在加入知乎之前,先后在搜狐研究院和雅虎北京研發中心從事分布式存儲以及云平臺相關的開發工作,現在在知乎計算平臺主要負責容器,流量負載均衡,以及大數據基礎組件相關的工作。在此次的演講中,張阜興主要從三個方面進行講解,包括知乎容器平臺演進、實踐過程中在生產環境里踩過的坑,以及在容器技術和大數據應用所做的一些融合實踐。
知乎容器平臺演進的歷程
在演講的開始,張阜興為大家介紹了知乎容器平臺演進的歷程。知乎容器平臺的演進歷程大致可以分成三個階段,2015年9月,知乎的容器平臺正式在生產環境中上線應用;2016年5月,知乎90%的業務遷移到容器平臺;目前,除了業務容器外,包括像HBase、Kafka多個基礎組件也采用容器部署,總的物理節點數達到了兩千多,容器數達到了三萬多。

演進過程中,張阜興總結了三個要點:
***是從Mesos到Kubernetes,這樣一個技術選型的變化;
第二是從單集群到多集群混合云的架構調整;
第三是從滾動部署到部署發布分離這樣的一種使用上的優化。
張阜興首先分享了從Mesos到Kubernetes技術選型的思考,知乎是在2015年開始在生產環境中使用容器平臺,那時Kubernetes剛剛發布,還不成熟。所以知乎選用了Mesos技術方案,Mesos的優勢是非常穩定,并且架構設計中,Master的負載比較輕,單集群可以容納的容器規模比較大,據官方介紹可以單集群容納五萬個節點。劣勢是需要單獨開發一套Framework,會帶來較高的使用成本。
Kubernetes的優勢是社區強大,功能完善,使用成本較低。但是由于他把所有的狀態都放在etcd中存取,所以單集群的所能容納節點規模沒有Mesos那么大。官方說法是現在etcd升級到V3版本之后,現在可以到五千個節點。
第二個架構上的變化是從單集群到混合云的架構,為什么要做這個呢,在生產環境中也是實際所需。***我們需要做灰度集群,也就是對于Mesos或者是對于Kubernetes做任何參數的變更,一定需要在灰度集群上去先做驗證,然后才能在生產環境中大規模的實踐。第二點是對單機群容量進行擴容,第三點是容忍單集群故障,采用混合云的架構因為公有云的集群池比較大,這樣可以大大提升彈性資源池的大小,抵抗突發擴容情況。
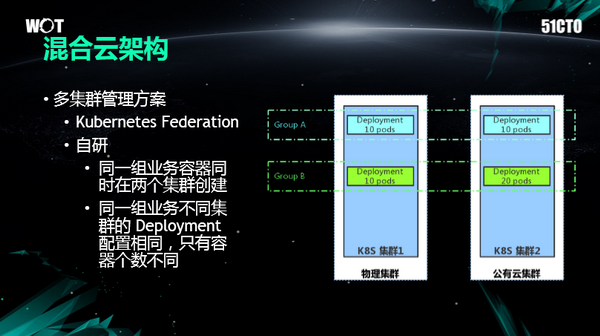
在混合云架構的實現過程中,知乎也調研了像Kubernetes的Federation這些方案,首先是Kubernetes的Federation方案現在官方還不推薦在生產環境中運行。第二,由于在部署和管理上有很多的問題,所以我們采用的是自研的管理方案,大致的原理就是我們的每一組業務容器會同時在多個集群上去創建Deployment,這些Deployment的配置,比如說像容器版本,或者CPU內存資源的配置都是完全相同的,唯一的不同只不過是容器數量會根據不同集群的大小做出調整。
另一個變化是從滾動部署的模式切換成了部署和發布分離的模式。這里先給出我們對部署和發布的定義,我們可以看一個典型的服務上線流程,包括了內網,金絲雀,生產環境三個發布階段,在每個階段都需要觀察驗證指標是否正常以便決定是繼續上線還是回滾,如果采用Deployment的滾動部署,可以實現每次升級部分容器,升級過程中服務不中斷,消耗的瞬時***資源較小,但是滾動部署不能控制進度暫停,導致不能和多個發布階段對應。如果每個階段采用獨立的 k8s Deployment,會導致部署速度慢,而且由于滾動過程中舊容器即銷毀了,如果要回滾,需要重新部署,回滾速度慢。為此,我們將部署和發布階段進行了分離,服務上線時,就后臺啟動一組新版本容器實例,當實例數滿足發布的條件時,就發布部分實例接收外部流量,在外部流量驗證過程中,后臺還可以并行的繼續部署新容器實例,從而使得用戶感知不到容器實例部署的時間,實現秒級部署。同時在發布過程中,舊容器實例只是不再對外可見,但實例依然保留一段時間,這樣如果發布過程有問題,可以立即切換,秒級回滾。
在容器的使用模式上,知乎引入了持久化存儲去對應著做一些支持。在容器是使用模式上我們從最初的無狀態web應用,到在容器中使用持久化存儲,來實現一些有狀態服務的容器化部署,如可以基于Hostpath,用Daemonset方式在每個節點上啟動consul agent,因為Deamon Set保證每個節點上只啟動一個pod,不會存在 hostpath 沖突的情況。基于 local volume 可以進行本地磁盤調度管理,實現 kafka broker 的部署,這個在后面介紹 kafka 方案時再想細介紹。另外有基于 Fuse 將 分布式文件系統映射到容器中,目前主要應用于業務數據讀取的場景。
另外一個使用模式是容器網絡,我們在Kubernetes的方案上,選用的是Underlay IP網絡,我們所采用的模式是容器的IP和物理機的IP是完全對等的。這樣互聯簡單,由于不存在overlay的封包解包處理,性能幾乎無損耗,另外 IP 模式下,可以方便的定位網絡連接的來源,故障定位更容易。在具體的實踐過程中,我們給每一臺機器一個固定網絡IP段,然后通過CNI插件IPAM去負責容器IP的分配和釋放。
維護容器平臺過程中所采過的那些坑
張阜興在容器平臺的生產環境和建立中有著豐富的經驗,也踩過不少技術的“坑”。在此次的WOT峰會上,他把過去經歷過的比較典型的技術故障、技術陷阱與大家分享,寶貴的“踩坑經”讓來賓受益匪淺。

陷阱之一:K8S events
在一個月黑風高的夜半,我們的K8S etcd 突然間全部不能訪問了,通過調查,原因就是K8S events 默認存儲方式帶來的性能問題。K8S默認會把集群發生的任何事件變化全部記錄到etcd里。K8S events默認配置了一個過期策略,每過一段時間,這個events就會回收,釋放etcd的存儲空間,這樣聽起來是很合理,但是在etcd對TTL的實現里面,每次去遍歷查找非常低效,隨著集群規模變大,集群上面頻繁的去發布部署變更,導致了events 越來越多,etcd負載越來越大,直至etcd崩掉,整個K8S集群就崩掉了。
K8S其實也意識到這個問題,所以為用戶提供了一個配置,可以把events記錄到一個單獨的etcd集群里。此外,我們可以在晚低峰的時候,把整個event的etcd清空,相當于我們自己去實現過期清理的策略。

陷阱之二:K8S Eviction
第二個坑是K8S Eviction,這個坑是直接把所有生產環境中的Pods全部給刪掉了。它的產生首先是API server要去配置高可用,但是即使配置了高可用,也會有很小的概率會掛掉。如果沒有及時去處理,例如API server宕機超過五分鐘,這些集群的Node都和它失聯了,會觸發控制節點將所有 pod 殺掉驅逐出集群。在1.5版本之后,官方已經增加了一個配置,就是-unhealthy-zone-threshold,例如當超過30%的Node處于一個失聯狀態的時候,這時候集群會禁止Controller Manager的驅逐策略,當遇到大規模異常時,防止對集群容器進行誤驅逐。
另一個是容器端口泄露問題,在使用端口映射的模式時,經常在發現有容器啟動時報port is already allocated,說這個端口已經被使用了。我們通過分析 Docker Daemon代碼,在 Docker Daemon 分配端口到記錄這個端口到內部的持久化存儲這個過程不是原子的,在這個中間如果Docker Daemon重啟了,只會根據存儲的端口記錄去恢復,所以它就遺忘掉了之前分配的端口。找到這個原因之后,我們向官方提出了對應的解決方案。

陷阱之三 :Docker NAT
還有一個坑是Docker NAT網絡遇到的。大家如果看了我貼的系統配置,對于網絡數據包的亂序的處理太過嚴格。如果容器中進程訪問阿里云等公網的一些圖片服務,在公網這種網絡比較差的時候,如果亂序包超過了TCP的滑動窗口,這時候系統的這個配置會把這個網絡連接給reset掉。把這個配置關掉之后就可以解決這個問題了。
在容器平臺和大數據組建融合上的嘗試
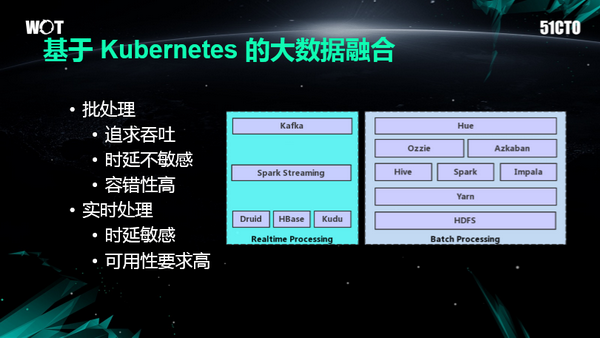
在大數據場景下其實主要有兩條處理路徑,如圖,左邊這一條是實時處理的,右邊的是批處理的。因為出發點不一樣,所以導致這些組件的設計思想有很大的不同,批處理因為主要是做這種ETL任務,所以說他主要是做那種數據倉庫的構建,追求的是吞吐率,對于時延是不敏感的。
但是實時處理是對時延是比較敏感的,里面的任何節點的掛掉,都會導致數據落地的延遲,以及數據展示不可用。所以說,像實時處理,他的組件所運行的這些機器的負載就不能特別高。
我們在大數據生產環境維護過程中,經常遇到的一些問題,比如說某一個業務做了一些變更,他寫入Kafka的流量突然大了很多,這時候把Kafka集訓整個的負載都給打高了,如果打的太高,可能整個集群就崩掉了,會使生產環境受到影響。
怎么去做對應的治理呢?基本的思路時去按業務方給他們做集群的劃分,集群的隔離。我們把集群劃分開了,帶來了另外一個問題,我們由原來的一套集群變成了幾十套集群,這么多集群我們怎么去統一的配置管理和部署。這個成本是很高的,我們用了K8s的模板,因為他可以很方便的一鍵搭建出多種相同的運行環境。
另外一個引發的問題是每一個業務方使用的量是不一樣的,有的業務方使用量比較大,有的業務方使用量比較小,如果使用量比較小的,比如說只有幾十個kbs,也需要維護一個高可用的集群,如果配備三臺機器,這樣就帶來了大量的資源浪費,我們的解決方案就是用容器來實現更細粒度的資源分配和配置。
大數據平臺的管理方面,我們踐行了Devops的思想,這意味著我們是平臺方而非運維方,我們定位自己為工具的開發者,日常運維操作,包括創建集群、重啟、擴容,都通過PaaS平臺交由業務方自主式的去完成。這樣的好處,首先是減少了溝通的成本,公司越來越大之后,這種業務方之間的溝通特別復雜。第二方便了業務方,比如說發現他需要擴容,可以直接在這個平臺上自己獨立的操作完成,減輕了日常工作負擔,也讓我們能夠更加專注于技術本身,專注于更好的如何把這個平臺和把底層的技術做的更好。
在大數據平臺上,我們還提供了豐富的監控指標,這個也是Devops實踐中我們必須理解的一環。因為業務本身對于像Kafka或者是對于HBase這種系統的理解是比較淺的,我們如何把我們積累的這些集群的理解和經驗,傳達給業務方,我們通過監控指標把這些指標完全暴露給業務方,希望把Kafka集群變成一個白盒,而不是一個黑盒,這樣業務方在發生故障的時候,直接在指標系統上就能看到各種各樣的異常,然后配合,比如說我們給他定制的一些報警閾值,他就能及時的自己去做一些處理。
總結而言,我們在容器和大數據融合上面的思路,首先我們要按業務方去做集群的隔離,第二是我們用K8S去做多集群的管理部署,然后用Docker去做資源的隔離和細粒度的分配和監控,以及在管理運維上我們踐行Devops這種理念,然后讓平臺方更加專注于工具開發本身,而不是限于瑣碎的運維操作不能自拔。
對于后續的展望,一方面是希望將更多的基礎設計組件,全部挪到K8S上,另外在這些組件之上,提供PaaS平臺,為業務方提供更好更方便更穩定的服務,最終的一個理想是將我們數據中心的資源統一的交給K8S去做調度管理,實現DCOS。
本次WOT峰會講師演講稿件由51CTO采編整理,如欲了解更多,敬請登錄www.ekrvqnd.cn進行查看。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】