作者 | 王路
編輯 | 王瑞平
本文整理自知乎云原生架構負責人王路在WOT2023大會上的主題分享,更多精彩內容及現場PPT,請關注51CTO技術棧公眾號,發消息【WOT2023PPT】即可直接領取。
日前,在51CTO主辦的WOT全球技術創新大會上,王路帶來了主題演講《知乎云原生的架構實踐》,為大眾呈現出全新視角。
云原生是一種新興的軟件架構和開發模式,它旨在實現高度可擴展、可靠和可持續的應用程序部署與管理。它的核心理念是將應用程序設計為可運行于云計算環境中的微服務,并采用容器化、自動化管理和彈性伸縮等技術手段來優化應用程序的開發、交付和運維過程。主要特點包括:容器化、微服務架構、自動化運維、持續交付、彈性伸縮等。
文章摘選自王路WOT期間演講的精彩內容,主要講述了知乎云原生架構演進的歷程和云原生架構的實踐。
云原生的出現使軟件開發人員能夠更好地利用云計算、容器技術和自動化運維等先進的技術手段,構建出高效、可靠和可擴展的應用程序。它為企業提供了更靈活、高效的應用交付和管理方式,也推動了云計算和微服務架構的發展。
與此同時,云原生也帶來了一系列的挑戰和變革,需要組織和開發團隊進行相應的技術轉型和組織變革,以適應云原生時代的發展需求。
王路2016年加入知乎,目前擔任公司內部云原生團隊負責人,負責知乎內部在線基礎設施原生架構的建設工作,并親歷了知乎云原生架構演進和實踐的全過程。
1、重新認識云原生:架構演進
云原生就像一個筐,什么東西都可以裝進去,但又很難解釋清云原生究竟是什么。王路以云原生架構演進為切入點,重新解讀了云原生的概念。現在簡單了解一下云原生架構的演進歷程:
 圖片
圖片
如圖所示,業務的演變經歷了從單體架構到SOA架構再到微服務架構。基礎設施則經歷了從物理機到虛擬機再到容器的演進過程。最終,雙劍合璧,云原生時代終于到來!
而伴隨著云原生的出現,業務架構和基礎架構的聯系也比以往更密切了。具體表現在:基礎架構能夠更細致地解決業務問題,真正關注業務痛點而不是基礎設施問題。
 圖片
圖片
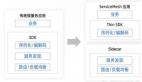
云原生計算基金會官方對于云原生技術棧的定義包括以下幾個部分:一、容器;二、不可變基礎設施;三、聲明式API;四、服務網格,最后一個是微服務。
其中,微服務屬于業務架構,其它4個屬于基礎架構。在實踐過程中,需要將幾個技術圍繞微服務劃分成幾個方向,比如,微服務部署、調度以及編排。
另一個比較重要的方向則是微服務的流量管理能力,既包括服務網格,也包含消息隊列。并且,服務網格只處理東西向流量管理問題,其實還有南北向流量管理問題。
這些方向最終都需要落地到業務或者使業務受益于云原生基礎設施,為此,必須提供DevOps平臺,使業務受益于云原生架構。
2、越早改變,成本越低:知乎云原生架構的演進歷程
知乎進行云原生改造時間較早,2014和2015年開始在業務方面進行微服務改造以及容器化。演進歷程大概分以下幾個階段:
2016年,知乎完成了全部業務的容器化。當時,知乎的流量和規模較小,改造成本也相對較低。
 圖片
圖片
2016年,知乎完成全部業務的容器化,當時用的是Mesos加自研framework的組合形式。服務發現、注冊還有通信用的是注冊中心HAproxy。
該階段過后過渡到下一階段。2018-2019年,Mesos被替換成了Kubernetes,還將中間件容器化,主要是將HAProxy和卡夫卡都進行了容器化。
下一個階段是2021年,最大的改變是引入了Service Mesh,部分替換掉原來的注冊中心+HAProxy服務的發現和注冊方式。另一個比較大的變化是數據庫已完成容器化,主要是TIDB和Redis。
如今,知乎主要變成了私有云狀態,相當于云建設主要由自己進行;但是,該能力已轉移至公有云,并提供了更大資源的彈性能力。另一塊比較大的變化就是離在線混部,目前,已獲得階段性進展。
以上就是知乎云原生架構全部的演進歷程。
3、基本架構:調度編排和Kubernetes的流量管理
上圖是簡單的云原生架構圖,相對來講比較簡單。從下向上主要是物理機、虛擬化層,上面則是調度編排層,再往上還構建出了Kubernetes的核心基礎服務。
 圖片
圖片
比如,流量管理主要是服務網格、服務網關和消息隊列,而對應的服務網格則是東西向的流量管理。
而微服務網關則是南北向的流量管理,消息隊列是異步流量管理。中間件有一部分和流量管理重合,比如,Kafka和Pulsar,可能承載了部分流量管理、消息隊列的能力,還有TIDB和Redis也都承載于Kubernetes之上。
重點是調度編排層、Kubernetes、流量管理以及可觀測、建設在基礎設施之上的平臺應用,比如,部署平臺、服務網格平臺、網關平臺還有可觀測平臺。
4、知乎云原生架構實踐:調度編排Kubernetes
知乎在云原生實踐過程中針對調度編排Kubernetes有哪些實踐經驗呢?
 圖片
圖片
上圖涵蓋了知乎的全部業務。如果這個架構出現任何問題,影響的將是知乎整體業務。而Kubernetes在這個架構圖里處于一個承上啟下的位置,是整個云原生架構的基石。
如果Kubernetes出了任何問題,影響幾乎是災難性的,因此,穩定性至關重要。
接下來,列舉兩個Kubernetes穩定性建設核心經驗:第一個是控制集群規模;第二個是保護好API server。
首先,控制集群規模對于Kubernetes集群管理來講有兩個主要方向:第一個是超大規模集群;另一個是多個小規模集群。
從知乎的角度看來,維護超大規模集群需要付出巨額的成本,比如,運維成本。而運維3個規模相對較小的集群和維護大集群的運維成本相對來說更低,因為,大規模集群面臨的性能問題較多。其次是研發成本,如果運維一萬家節點或五千家節點以上,可能需要付出研發成本和對原生組件進行改造。
另一個比較關鍵的點是故障的影響。業務如果完全放置于大集群,故障發生時的爆炸半徑也是極大的。但是,如果分散在多個集群之中,即使某個集群完全崩潰,影響也微乎其微,而不是災難性的。
從知乎的實踐經驗來看,多個小規模Kubernetes集群更實用,而不是大規模的超大集群。
 圖片
圖片
但是,如果使用多集群,可能需要解決如下問題:第一個是進行多集群應如何劃分;第二個是多集群之間資源需要如何調度;第三個是多集群間如何進行服務發現和通信。
在維護API server穩定性方面。知乎發生過幾次相關故障,比如,將異常流量“打掛”后會直接導致“血崩”。此時,需要復用內部網關能力,進行七層限流,可以限制異常流量,將關鍵組件流量保護住,使Apiserver能夠快速恢復。
5、流量管理實踐:服務網格、消息隊列、網關
流量管理主要包含3個組件:服務網格、消息隊列、網關。
首先解釋下一個關鍵問題,在流量管理的過程中為什么要將東西向流量管理、異步流量管理以及南北向流量管理放在一起呢?
第一,隨著業務發展,微服務之間的通信變得越來越復雜。對此提出過很多的治理能力需求,比如,自動配置限流能力和熔斷能力等。
第二,現有方案改造,其實就是HAProxy+注冊中心方式。理論上來說,你完全可以基于HA進行一整套治理能力的改進,但是研發成本較高。
第三,服務網格方案istio,提供了豐富的標準化流量治理能力。這相當于滿足業務需求或業務對基礎架構能力的需求。
 圖片
圖片
從架構方面來看,性能上的優化或遇到的最大性能挑戰是推送性能。istiod需要將所有配置都推送到Sidecar上。這既需要配置方面的優化,也需要架構上的優化。
現在,知乎自研了一整套限流組件,提供了本地限流能力,包括:全球限流能力,也遇到了負載均衡問題。
實踐證明,中心化負載均衡效果較好,但是,當切換到Mesh或sidecar模式,每個sidecar和每個客戶端都缺乏全局負載信息,使負載效果在某些業務方面就變得極差。
知乎也針對這些方面做出過一些改進。如果缺少全局信息,就需要將sidecar提上去,然后將一組實例當作單獨的負載均衡集群,實現較為均衡的效果。該方案與之前的HAProxy最大的區別是它可以完整獲取現有istiod的治理能力。
6、可觀測實踐:Metric、Logging、Tracing
在可觀測上實踐方面,知乎的底層統一使用Victorial Metrics作為存儲系統,而上層都是以Promesql格式進行存儲的,既提供了原生的Promesql格式查詢,也提供了自研的組件。
 圖:可觀測指標系統
圖:可觀測指標系統
可觀測性比較簡單,Filebeat是收集端,存儲是自研的,搜索依賴于存儲,全量日志則是通過Flink落地HDFS。
Tracing統一使用Open Telemetry收集端。ClickHouse則用于存儲和查詢。性能相對來說可以滿足需求。
7、寫在最后:時刻關注業務需求和穩定性
基礎架構要時刻關注業務架構的需求。架構升級一定為業務服務,而不是升級。你需要考慮架構升級有沒有給業務帶來好處,或者業務開發效率和穩定性是否因為架構升級變得更好。另外一點,架構升級的時機要好。
此外,穩定性永遠是第一位的。如果保障不了穩定性,所有的架構升級都是空中樓閣。
未來,知乎會更多關注多云多活和離在線混部,繼續在全時離在線混部上投入,實現全時混部,并且,Serverless也是未來的發展方向。