













謹防5個陷阱!數據科學家新手快速上道秘訣
在數據科學家入門階段,你不可避免會踩到一些雷區。這篇文章介紹了 Sébastien Foucaud 博士總結的新手數據科學家最容易犯的 5 個錯誤。博士已經有 20 多年帶領學術界和應用行業年輕數據科學家的經驗,可以幫讀者朋友少走些彎路,為你的實際工作提供一些指導和幫助。話不多說,上清單!

1. 熱衷于 Kaggle 競賽
資料來源:kaggle.com
參加 Kaggle 競賽可以鍛煉你的數據科學職業技能。如果你懂決策樹和神經網絡那再好不過了。但實話告訴你吧,數據科學家的實際工作中用不著創建那么多的模型。請記住,一般情況下,你將花費 80%的時間對數據進行預處理,只有剩下的 20%用于構建模型。
數據科學家工作時間分布
參加 Kaggle 競賽在很多方面都會對你很有幫助。但是,參加競賽的時候,通常數據會被完美地清理干凈,所以你可以花很多時間去調整模型。而在現實工作中很少出現這種情況,你必須從不同格式和命名的不同來源收集數據。
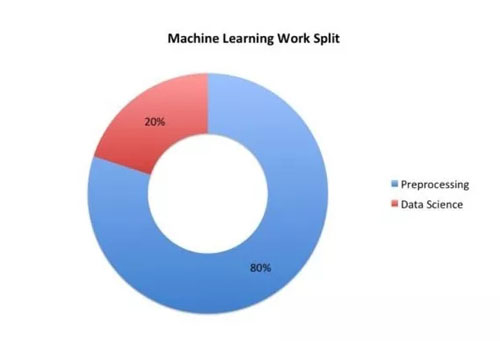
不要害怕臟活累活,一定要好好練習數據預處理技能,因為它將占據你 80%的工作時間。比如爬取圖像或從 API 收集這些圖像數據;從 Genius 收集歌詞數據等。準備好解決特定問題所需的數據,然后將其輸入你的筆記本并訓練機器學習生命周期。精通數據預處理無疑將幫助你成為真正的數據科學家,并對你的公司產生直接影響。
2. 神經網絡是“萬能金丹”
深度學習模型在計算機視覺或自然語言處理領域優于其他機器學習模型。但他們也有明顯的缺點。
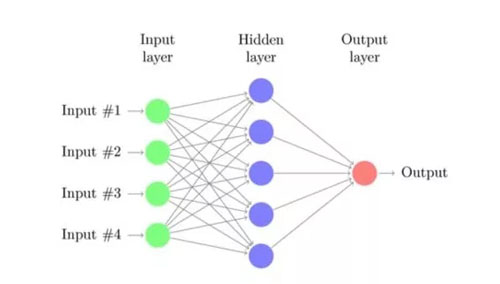
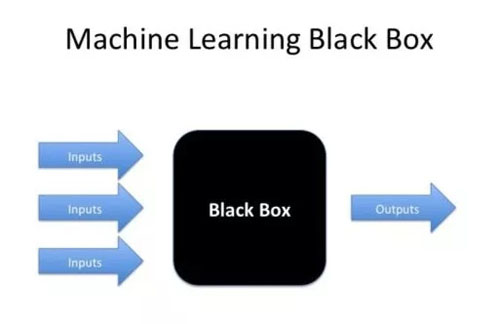
神經網絡對數據十分依賴。如果樣本較少,通常用決策樹或邏輯回歸模型結果會更好。神經網絡還是一個黑匣子。眾所周知,它們難以解釋和說明。如果產品所有者或管理者開始質疑模型的輸出,你必須能夠解釋清楚模型的原理。這對于傳統模型來說更容易一點。
正如 James Le 在這篇優秀文章中所說(https://towardsdatascience.com/a-tour-of-the-top-10-algorithms-for-machine-learning-newbies-dde4edffae11 ),我們有很多很棒的統計學習模型。自學這些知識,了解它們的優缺點,并根據用例的條件應用這些模型。除非你在計算機視覺或自然語音識別專業領域工作,否則很有可能傳統機器學習算法才是最好用的模型。你很快就會發現,最簡單的模型,如 Logistic 回歸,才是最好用的模型。
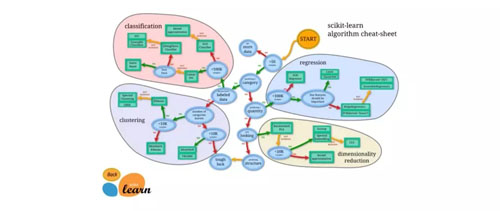
來源: scikit-learn.org 算法備忘單
3. 機器學習是產品
機器學習在過去的十年中都被過度炒作,太多的創業公司吹噓機器學習能夠解決任何存在的問題。
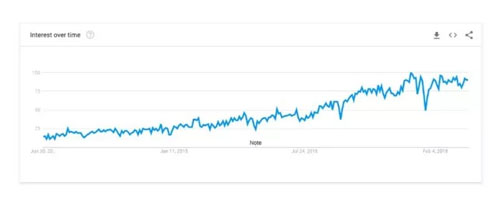
來源:過去 5 年 Google 機器學習趨勢
機器學習本身不應該是產品。機器學習是創建滿足客戶需求的產品的強有力的工具。在客戶接收精準商品推薦方面,機器學習可以有所幫助。如果客戶需要準確識別圖像中的對象,機器學習也有用。企業通過向用戶展示有價值的廣告而獲益,機器學習同樣可以提供幫助。
作為數據科學家,你所制定的項目需要以客戶的目標為主要優先事項。只有這樣,你才能評估機器學習是否會幫到客戶。
4. 混淆因果關系
大約 90%的數據是在過去幾年中涌現的。隨著大數據的出現,機器學習從業者能夠接觸到大量廣泛的數據。有了這么多要評估的數據,學習模型發現隨機相關性的概率隨之增加。
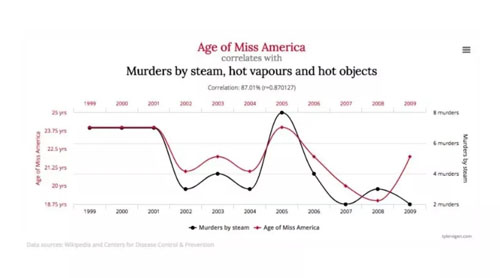
資料來源:http://www.tylervigen.com/spurious-correlations
上面的圖片顯示了美國小姐的年齡以及由蒸汽、熱蒸氣和發熱物體導致的謀殺的總數。基于這些數據,算法將學習到美國小姐的年齡與特定物體導致的謀殺數量之間會互相影響的關系模型。然而,兩個數據點實際上毫無關系,并且這兩個變量對彼此都絕對沒有任何可預測的影響。
在發現數據之間的關系時,將你的領域知識應用進去。這可能是相關性還是因果關系?回答這些問題是根據數據采取行動的關鍵。
5. 優化錯誤的參數
開發機器學習模型有一個敏捷的生命周期。首先,你要定義你的想法和關鍵參數。其次,你需要創建一個結果的原型。第三,你不斷優化參數,直到你對它感到滿意。
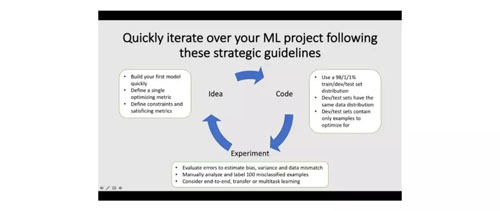
在構建機器學習模型時,請記住要手動進行錯誤分析。雖然這個過程乏味并耗力,但它會幫助你在接下來的迭代中有效地改進模型。請參閱吳恩達的深度學習專項課程,以獲得更多優化模型的技巧。
https://www.coursera.org/learn/machine-learning-projectshttps://towardsdatascience.com/structuring-your-machine-learning-project-course-summary-in-1-picture-and-22-nuggets-of-wisdom-95b051a6c9dd
要點總結
- 練習數據管理技能
- 研究不同模型的優缺點
- 盡可能簡化模型
- 檢查你結論中的因果關系和相關性
- 優化最有用的參數
年輕數據科學家為公司創造了巨大的價值。他們剛剛學完在線課程,可以立刻為公司提供幫助。他們很多人通常是自學成才,因為很少有大學提供數據科學課程和學位,因此他們對此表現出巨大的決心和好奇心。他們對自己選擇的領域充滿熱情,并渴望了解更多信息。但是,在熱情滿滿的時候也不要盲目學習,謹防以上數據科學家新手會掉落的陷阱,會幫你少走很多彎路。













