數據庫主從不一致,怎么解?
作者:58沈劍
在聊數據庫與緩存一致性問題之前,先聊聊數據庫主庫與從庫的一致性問題。下面,我們一起來看。
在聊數據庫與緩存一致性問題之前,先聊聊數據庫主庫與從庫的一致性問題。
問:常見的數據庫集群架構如何?
答:一主多從,主從同步,讀寫分離。
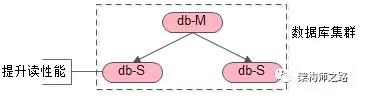
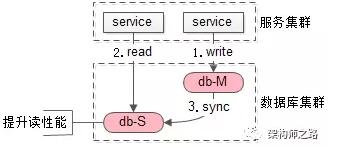
如上圖:
- 一個主庫提供寫服務
- 多個從庫提供讀服務,可以增加從庫提升讀性能
- 主從之間同步數據
畫外音:任何方案不要忘了本心,加從庫的本心,是提升讀性能。
問:為什么會出現不一致?
答:主從同步有時延,這個時延期間讀從庫,可能讀到不一致的數據。
如上圖:
- 服務發起了一個寫請求
- 服務又發起了一個讀請求,此時同步未完成,讀到一個不一致的臟數據
- 數據庫主從同步***才完成
畫外音:任何數據冗余,必將引發一致性問題。
問:如何避免這種主從延時導致的不一致?
答:常見的方法有這么幾種。
方案一:忽略
任何脫離業務的架構設計都是耍流氓,絕大部分業務,例如:百度搜索,淘寶訂單,QQ消息,58帖子都允許短時間不一致。
畫外音:如果業務能接受,最推崇此法。
如果業務能夠接受,別把系統架構搞得太復雜。
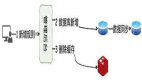
方案二:強制讀主
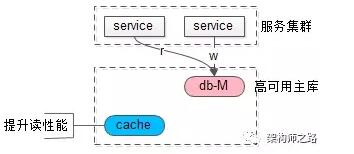
如上圖:
- 使用一個高可用主庫提供數據庫服務
- 讀和寫都落到主庫上
- 采用緩存來提升系統讀性能
這是很常見的微服務架構,可以避免數據庫主從一致性問題。
方案三:選擇性讀主
強制讀主過于粗暴,畢竟只有少量寫請求,很短時間,可能讀取到臟數據。
有沒有可能實現,只有這一段時間,可能讀到從庫臟數據的讀請求讀主,平時讀從呢?
可以利用一個緩存記錄必須讀主的數據。
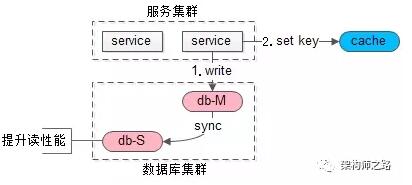
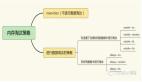
如上圖,當寫請求發生時:
- 寫主庫
- 將哪個庫,哪個表,哪個主鍵三個信息拼裝一個key設置到cache里,這條記錄的超時時間,設置為“主從同步時延”
畫外音:key的格式為“db:table:PK”,假設主從延時為1s,這個key的cache超時時間也為1s。
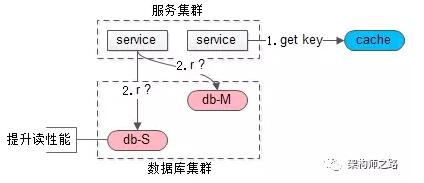
如上圖,當讀請求發生時:
這是要讀哪個庫,哪個表,哪個主鍵的數據呢,也將這三個信息拼裝一個key,到cache里去查詢,如果,
- cache里有這個key,說明1s內剛發生過寫請求,數據庫主從同步可能還沒有完成,此時就應該去主庫查詢
- cache里沒有這個key,說明最近沒有發生過寫請求,此時就可以去從庫查詢
以此,保證讀到的一定不是不一致的臟數據。
總結
數據庫主庫和從庫不一致,常見有這么幾種優化方案:
- 業務可以接受,系統不優化
- 強制讀主,高可用主庫,用緩存提高讀性能
- 在cache里記錄哪些記錄發生過寫請求,來路由讀主還是讀從
文字很短,不能解決所有問題,但希望能給大家一些啟示。
【本文為51CTO專欄作者“58沈劍”原創稿件,轉載請聯系原作者】

責任編輯:趙寧寧
來源:
51CTO專欄