如何解決緩存系統的數據不一致問題
本文轉載自微信公眾號「后端技術指南針」,作者大白。轉載本文請聯系后端技術指南針公眾號。
1緩存系統交互
緩存系統設計是后端開發人員的必備技能,也是實現高并發的重要武器。
對于讀多寫少的場景,我們通常使用內存型數據庫作為緩存,關系型數據庫作為主存儲,從而形成兩層相互依賴的存儲體系。
共識:我們將使用Redis和MySQL作為緩存和主存的實體,展開今天的話題。
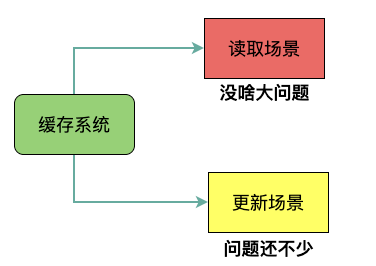
緩存系統的讀取場景和更新場景:
- 讀取時只要之前MySQL和Redis中的數據是一致的,后續只要沒有更新操作就不會有什么問題,同時借助于內存來提高并發能力,這也是我們設計緩存系統的初衷。
- 對于讀多寫少的業務模型,由于操作MySQL和Redis并非天然的原子操作,會造成數據的不一致,需要特殊處理。
讀取過程示意:
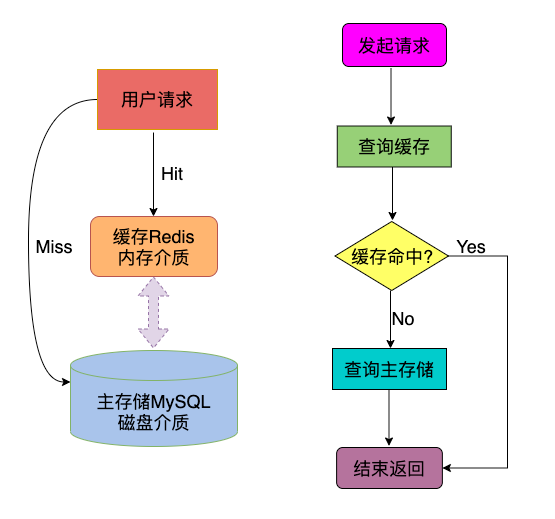
讀取過程:讀請求優先從緩存中獲取數據,拿到后即可返回;如緩存無數據,則從主存儲拿數據,并且將數據更新到緩存中,為后續的讀取請求做鋪墊。
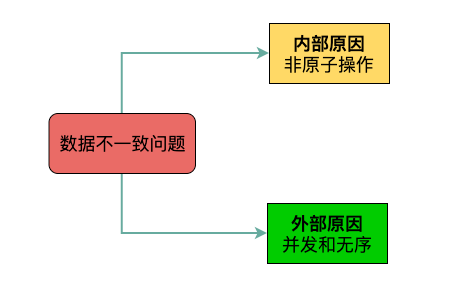
更新過程之所以會出現數據不一致問題,有內外兩大原因:
- 內部原因:Redis和MySQL的更新不是天然的原子操作,非事務性的組合拳。
- 外部原因:實際中的讀寫請求是并發且無序的,可預測性很差,完全不可控。
2數據不一致的感知
我們來看個實際中的例子,進一步了解緩存系統的數據不一致問題。
平時上下班擠地鐵的時候,我們經常會聽網易云,比如我喜歡聽民謠,所有會關注官方發布的一些民謠歌曲榜單,如圖:
歌單是網易云的運營同學配置的,作為用戶我們是無法修改的歌單的內容的,所以這是個非常典型的讀多寫少的場景。
所以假如我是網易云的后端同學,我肯定會把歌單的信息存儲在Redis中,緩存下來提高性能,大概可以是這個樣子:
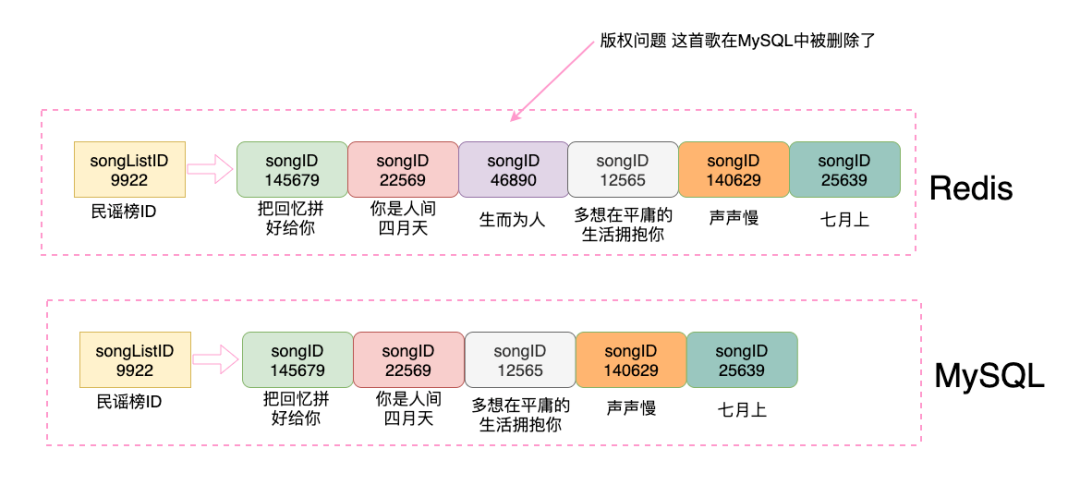
假如因為版權問題,運營刪除了一首歌,此時更新了MySQL,但是Redis中的數據并沒有及時被更新,那么就會有一少部分用戶在歌單中看到本已被刪除的歌曲,點擊時可能無法播放等。
畫外音:這就是緩存和主存儲的數據不一致的現象,當然具體網易云是咋實現的,咱也不清楚,上述的場景純屬作者腦補來說明不一致問題的直觀實例。
3理性看待不一致問題
數據一致性可以說是分布式系統中必然存在的問題,數據一致性可以分為:
- 強一致性:時時刻刻保持一致。
- 最終一致性:允許短暫的不一致,但是最后還是一致的。
要實現緩存和主存儲的強一致性,需要借助于復雜的分布式一致性協議等,倒不如不用緩存,畢竟緩存的優勢還是讀多寫少的場景。
畫外音:緩存并不是什么萬金油,對于寫多讀少的場景,或許并不是適合用緩存。
工程和學術是有區別的,因此我們后續的問題都是圍繞最終一致性展開的,因為這才是有意義的問題。
進而我們將問題轉化為:
研究重點:在保證數據最終一致性的前提下,如何把數據不一致帶來的影響降低到業務可接受的范圍內?
4更新還是刪除是個問題
當MySQL被更新時,我們如何處理Redis呢?
- 直接將key淘汰掉,是否再次被加載由后續讀請求決定。
- 直接update發生變化的key,相當于幫后面的請求做了加載的操作。
可以明確一點刪除操作直接操作就行(簡單明了),但是更新操作可能涉及的處理步驟更多,也就是update可能比delete更復雜。
另外,我們需要盡量保證Redis中的數據都是熱數據,update每次都會使得數據駐留在Redis中,或許這是沒有必要的,因為這些可能是冷數據,至于要加載哪些數據,還是交給后面的請求比較合適,各司其職。
綜上,我們更傾向于將delete作為通用的選擇,因此后續都是基于淘汰緩存來展開的。
5如何解決不一致問題
Redis和MySQL的數據不一致產生的根源是業務需要進行更新(寫入)操作。
先操作Redis 還是 先操作MySQL是個問題,操作時序不同產生的影響也不同。
尺有所短,寸有所長,說到底是一種權衡,哪一種組合產生的負面影響對業務最小,就傾向于哪種方案。
緩存系統的數據不一致問題,是個經典的問題,因此肯定有很多解決問題的套路,所以讓我們帶著分析和思考去看看,各個方案的利弊。
思路一:設置緩存過期時間
當向Redis寫入一條數據時,同時設置過期時間x秒,業務不同過期時間不同。
過期時間到達時Redis就會刪掉這條數據,后續讀請求Redis出現Cache Miss,進而讀取MySQL,然后把數據寫到Redis。
如果發生更新操作時,只操作MySQL,那么Redis中的數據更新就只是依賴于過期時間來保底,淘汰后再被加載就是新數據了。
畫外音:這種方案是最簡單的,如果業務對短時間不一致問題并不在意,設置過期時間的方案就足夠了,沒有必要搞太復雜。
思路二:先淘汰緩存&再更新主存
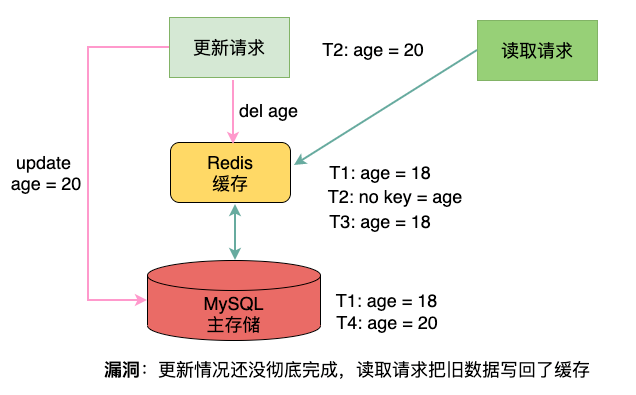
進行更新操作時,為了防止其他線程讀到緩存中的舊數據,干脆淘汰掉,然后把數據更新到主存儲,后續的請求再次讀取時觸發Cache Miss,從而讀取MySQL再將新數據更新到Redis。
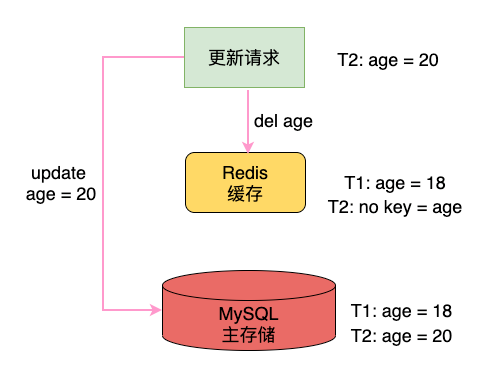
- 在T1時刻:Redis和MySQL對于age的值都是18,二者一致;
- 在T2時刻:有更新請求需要設置age=20,此時Redis中就沒有age這個數據了;在完成Redis淘汰后,進行MySQL數據更新age=20;
這個方案聽著還不錯的樣子,但是讀寫請求都是并發的,先后順序完全無法預測,甚至后發出的請求先處理完成,也是很常見的。
可見一個明顯的漏洞:在淘汰Redis的數據完成后,更新MySQL完成之前,這個時間段內如果有新的讀請求過來,發現Cache Miss了,就會把舊數據重新寫到Redis中,再次造成不一致,并且毫無察覺后續讀的都是舊數據。
畫外音:這個方案其實不能說完全沒有用,但是至少不完美吧。
思路三:先更新主存&再淘汰緩存
進行更新操作時,先更新MySQL,成功之后,淘汰緩存,后續讀取請求時觸發Cache Miss再將新數據回寫Redis。
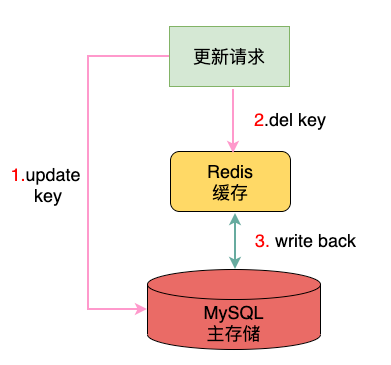
這種模式在更新MySQL和淘汰Redis這段時間內,請求讀取的還是Redis的舊數據,不過等MySQL更新完成,就可以立刻恢復一致,影響相對比較小。
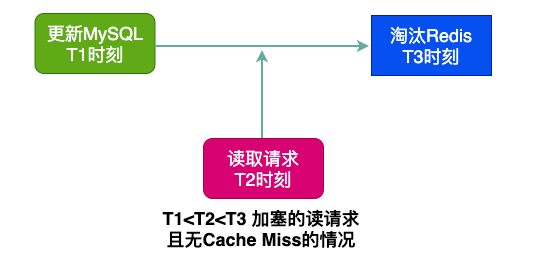
上述是在緩存中有數據的情況,也就是T2時刻的讀請求沒有觸發Cache Miss,也就不會更新緩存,因此問題不大。
但是,假如T2時刻讀取的數據在緩存沒有,那么觸發Cache Miss后會產生回寫,假如這個回寫動作是在T4時刻完成,那么寫入的還是老數據,如圖:
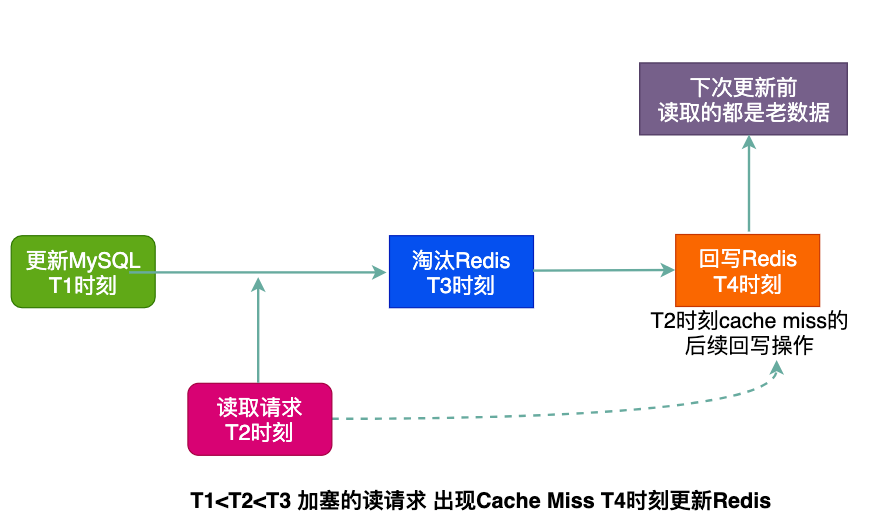
這種情況確實有問題,但是真是太巧了吧,分析一下:
- 事件A:淘汰Redis前來了一個讀請求;
- 事件B:T2時刻的讀請求觸發了Cache Miss;
- 事件C:回寫Redis發生在淘汰緩存之后;
那么發生問題的概率就是P(A)*P(B)*P(C),從實際考慮這種綜合事件發生的概率非常低,因為寫操作遠慢于讀操作,也就是圖上的T4事件大概率是發生在T3事件之前的。
畫外音:先更新MySQL再淘汰Redis的方案,雖然存在小概率不一致問題,但是總體來說工程上是可用的,比如非要說寫完MySQL掛了,Redis就沒淘汰,這種情況只能說確實有問題。
思路四:延時雙刪(淘汰)
前面提到的思路二和思路三都只有一次Redis淘汰操作,這里要說的延時雙刪本質上是思路二和思路三的結合:

說實話個人覺得,這個方案有點堆操作的感覺,而且設置延時的目的是為了避免思路三的小概率問題,延時設置多久不好確定,二來延時降低了并發性能,同時前置的刪除緩存操作起到的作用并不大。
這個方案倒是透露出一種思想:多刪幾次,可能一致性更有保證,那確實如此,但是命中率也就低了,命中率和一致性看來也是一對矛盾。
畫外音:這個方案也不是說不行,其實有點麻煩,并且在復雜高并發場景中反而影響性能,要是一般的場景或許也能用起來。
思路五:異步更新緩存
既然直接操作MySQL和Redis都多少存在一些問題,那么能不能引入中間層來解決問題呢?
把MySQL的更新操作完成后不直接操作Redis,而是把這個操作命令(消息)扔到一個中間層,然后由Redis自己來消費更新數據,這是一種解耦的異步方案。
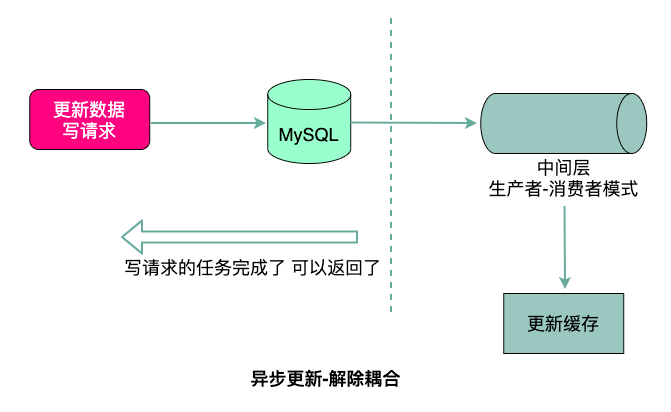
單純為了更新緩存引入中間件確實有些復雜,但是像MySQL提供了binlog的同步機制,此時Redis就作為Slave進行主從同步,實現數據的更新,成本也還可以接受。
畫外音:引入中間層思想真是萬金油啊!
6 總結一下
本文主要介紹了以下幾個關鍵內容:
- 緩存系統適用的場景:讀多寫少。
- 緩存系統的讀寫基本交互過程,讀很簡單,寫有點復雜。
- 緩存系統寫時的不一致問題有內外兩個因素:外部讀寫的并發無序性和內部操作非原子性。
- 使用緩存系統,我們就需要接受最終一致性的前提,否則不建議用緩存。
- 解決緩存數據不一致的思路有很多,或多或少都有不足,具體用哪種,需要根據實際業務場景,沒有哪種方案是普遍適用的。