Redis的主從庫如何實現數據一致?
之前我們詳細了解了 Redis 的持久化機制,包括 AOF 和 RDB,它們能在宕機發生時,盡量少丟失數據,確保可靠性。然而,如果只有一個 Redis 實例在運行,它在恢復數據期間將無法服務新的數據請求,這是一個可用性上的問題。
那么,Redis所謂的高可靠性意味著什么呢?它涵蓋兩個重要方面:數據不輕易丟失和服務不容易中斷。AOF和RDB確保了前者,但對于后者,Redis的解決方法是增加冗余副本,將數據保存在多個Redis實例上。即使其中一個實例發生故障且需要一段時間來恢復,其他實例仍能繼續提供服務,不會影響業務的正常運行。
然而,多個實例存儲相同的數據引發了一個新的問題:如何保持這些數據副本的一致性?難道需要將數據讀寫操作同時傳遞給所有實例嗎?
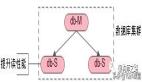
Redis采用主從庫的模式來確保數據副本的一致性。這種模式允許主庫(master)處理寫操作和主動廣播數據變更給從庫(slave),而從庫則主要用于讀操作。這種讀寫分離的方法有助于保持數據的一致性,同時提高了性能和可用性。
讀操作:主庫、從庫都可以接收;
寫操作:首先到主庫執行,然后,主庫將寫操作同步給從庫。
 Redis主從庫和讀寫分離
Redis主從庫和讀寫分離
那么,為什么要采用讀寫分離的方式呢?
你可以設想一下,如果在上圖中,不管是主庫還是從庫,都能接收客戶端的寫操作,那么,一個直接的問題就是:如果客戶端對同一個數據(例如 k1)前后修改了三次,每一次的修改請求都發送到不同的實例上,在不同的實例上執行,那么,這個數據在這三個實例上的副本就不一致了(分別是 v1、v2 和 v3)。在讀取這個數據的時候,就可能讀取到舊的值。
如果我們堅持要保持這個數據在三個實例上一致,那么就需要引入諸如加鎖、實例間協商是否完成修改等一系列復雜操作。這些額外的操作會帶來巨大的性能和復雜性開銷,通常是難以接受的。
然而,一旦采用主從庫模式并啟用讀寫分離,數據的修改操作只會在主庫上進行。主庫獲得最新數據后,會將其同步給從庫。這樣,主從庫之間的數據就能保持一致。
你可能會想知道,主從庫同步是一次性傳輸所有數據,還是分批次同步?如果主從庫之間的網絡連接斷開了,數據如何保持一致?在這節課中,我將與你分享主從庫同步的工作原理,以及如何應對網絡中斷等風險的解決方案。
好的,首先,讓我們來了解主從庫之間的首次同步是如何進行的,這是 Redis 實例建立主從庫模式后的初始步驟。
主從庫間如何進行第一次同步?
當我們啟動多個 Redis 實例的時候,它們相互之間就可以通過 replicaof(Redis 5.0 之前使用 slaveof)命令形成主庫和從庫的關系,之后會按照三個階段完成數據的第一次同步。
例如,現在有實例 1(ip:172.16.19.3)和實例 2(ip:172.16.19.5),我們在實例 2 上執行以下這個命令后,實例 2 就變成了實例 1 的從庫,并從實例 1 上復制數據:
replicaof 172.16.19.3 6379
接下來,我們就要學習主從庫間數據第一次同步的三個階段了。你可以先看一下下面這張圖,有個整體感知,接下來我再具體介紹。
 主從庫第一次同步的流程
主從庫第一次同步的流程
第一階段是主從庫間建立連接、協商同步的過程,主要是為全量復制做準備。在這一步,從庫和主庫建立起連接,并告訴主庫即將進行同步,主庫確認回復后,主從庫間就可以開始同步了。
具體來說,從庫給主庫發送 psync 命令,表示要進行數據同步,主庫根據這個命令的參數來啟動復制。psync 命令包含了主庫的 runID 和復制進度 offset 兩個參數。
runID,是每個 Redis 實例啟動時都會自動生成的一個隨機 ID,用來唯一標記這個實例。當從庫和主庫第一次復制時,因為不知道主庫的 runID,所以將 runID 設為“?”。
offset,此時設為 -1,表示第一次復制。
主庫收到 psync 命令后,會用 FULLRESYNC 響應命令帶上兩個參數:主庫 runID 和主庫目前的復制進度 offset,返回給從庫。從庫收到響應后,會記錄下這兩個參數。
這里有個地方需要注意,FULLRESYNC 響應表示第一次復制采用的全量復制,也就是說,主庫會把當前所有的數據都復制給從庫。
在第二階段,主庫將所有數據同步給從庫。從庫收到數據后,在本地完成數據加載。這個過程依賴于內存快照生成的 RDB 文件。
具體而言,主庫首先執行 bgsave 命令,生成 RDB 文件,然后將這個文件發送給從庫。一旦從庫接收到 RDB 文件,它會首先清空當前數據庫,然后加載這個 RDB 文件。這是因為在從庫通過 replicaof 命令開始和主庫同步之前,可能已經存在其他數據。為了確保新數據的一致性,從庫必須清空當前數據庫。
在主庫將數據同步給從庫的過程中,主庫不會被阻塞,繼續正常處理請求。這是非常重要的,因為阻塞主庫將導致 Redis 服務中斷。然而,需要注意的是,這些請求中的寫操作并沒有記錄到剛剛生成的 RDB 文件中。為了確保主從庫的數據一致性,主庫會在內存中使用專門的復制緩沖區,記錄在生成 RDB 文件后接收到的所有寫操作。
最后,我們來到第三個階段,主庫將第二階段執行期間接收的新寫命令發送給從庫。具體來說,一旦主庫完成 RDB 文件的發送,它會將此刻復制緩沖區中的修改操作發送給從庫。從庫將再次執行這些操作,從而實現主從庫的數據同步。這三個階段將主庫和從庫的數據保持一致。
主從級聯模式分擔全量復制時的主庫壓力
通過分析主從庫間第一次數據同步的過程,你可以看到,一次全量復制中,對于主庫來說,需要完成兩個耗時的操作:生成 RDB 文件和傳輸 RDB 文件。
如果從庫數量很多,而且都要和主庫進行全量復制的話,就會導致主庫忙于 fork 子進程生成 RDB 文件,進行數據全量同步。fork 這個操作會阻塞主線程處理正常請求,從而導致主庫響應應用程序的請求速度變慢。此外,傳輸 RDB 文件也會占用主庫的網絡帶寬,同樣會給主庫的資源使用帶來壓力。那么,有沒有好的解決方法可以分擔主庫壓力呢?
其實是有的,這就是“主 - 從 - 從”模式。
在剛才介紹的主從庫模式中,所有的從庫都是和主庫連接,所有的全量復制也都是和主庫進行的。現在,我們可以通過“主 - 從 - 從”模式將主庫生成 RDB 和傳輸 RDB 的壓力,以級聯的方式分散到從庫上。
簡單來說,我們在部署主從集群的時候,可以手動選擇一個從庫(比如選擇內存資源配置較高的從庫),用于級聯其他的從庫。然后,我們可以再選擇一些從庫(例如三分之一的從庫),在這些從庫上執行如下命令,讓它們和剛才所選的從庫,建立起主從關系。
replicaof 所選從庫的IP 6379
這樣一來,這些從庫就會知道,在進行同步時,不用再和主庫進行交互了,只要和級聯的從庫進行寫操作同步就行了,這就可以減輕主庫上的壓力,如下圖所示:
 級聯的“主-從-從”模式
級聯的“主-從-從”模式
好了,到這里,我們了解了主從庫間通過全量復制實現數據同步的過程,以及通過“主 - 從 - 從”模式分擔主庫壓力的方式。那么,一旦主從庫完成了全量復制,它們之間就會一直維護一個網絡連接,主庫會通過這個連接將后續陸續收到的命令操作再同步給從庫,這個過程也稱為基于長連接的命令傳播,可以避免頻繁建立連接的開銷。
聽上去好像很簡單,但不可忽視的是,這個過程中存在著風險點,最常見的就是網絡斷連或阻塞。如果網絡斷連,主從庫之間就無法進行命令傳播了,從庫的數據自然也就沒辦法和主庫保持一致了,客戶端就可能從從庫讀到舊數據。
接下來,我們就來聊聊網絡斷連后的解決辦法。
主從庫間網絡斷了怎么辦?
在Redis 2.8之前,主從復制中若出現網絡閃斷,從庫將不得不重新執行一次繁重的全量復制操作,這勢必造成巨大的開銷。
不過,Redis自2.8版本開始,出現網絡斷連時,主從庫采用一種稱為"增量復制"的方式來繼續同步。從名字中我們可以猜測,它與全量復制有所不同:全量復制同步所有數據,而增量復制僅將主庫在網絡斷連期間接收到的命令同步給從庫。
那么,在增量復制過程中,主從庫是如何確保同步的呢?關鍵在于repl_backlog_buffer這個緩沖區。現在,我們來詳細看看它如何在增量命令同步中發揮作用。
當主從庫出現斷連后,主庫會將在此期間接收到的寫操作命令記錄在復制緩沖區(replication buffer)中,并同時寫入repl_backlog_buffer這個緩沖區。
repl_backlog_buffer 是一個環形緩沖區,主庫會記錄自己寫到的位置,從庫則會記錄自己已經讀到的位置。
一開始,主庫和從庫的寫讀位置是相同的,可以看作它們的初始位置。隨著主庫接收新的寫操作,主庫在緩沖區中的寫位置會逐漸偏離起始位置。通常,我們使用偏移量來度量這個偏移距離,對于主庫,這個偏移量就是master_repl_offset。隨著主庫接收的新寫操作增多,這個偏移量也會逐漸增加。
同樣的,從庫在復制完寫操作命令后,其在緩沖區中的讀位置也開始逐漸偏離初始位置。此時,從庫已經復制的偏移量slave_repl_offset也在不斷增加。在正常情況下,這兩個偏移量基本上是相等的。
 Redis repl_backlog_buffer的使用
Redis repl_backlog_buffer的使用
主從庫的連接恢復之后,從庫首先會給主庫發送 psync 命令,并把自己當前的 slave_repl_offset 發給主庫,主庫會判斷自己的 master_repl_offset 和 slave_repl_offset 之間的差距。
在網絡斷連階段,主庫可能會收到新的寫操作命令,所以,一般來說,master_repl_offset 會大于 slave_repl_offset。此時,主庫只用把 master_repl_offset 和 slave_repl_offset 之間的命令操作同步給從庫就行。
就像剛剛示意圖的中間部分,主庫和從庫之間相差了 put d e 和 put d f 兩個操作,在增量復制時,主庫只需要把它們同步給從庫,就行了。
說到這里,我們再借助一張圖,回顧下增量復制的流程。
 Redis增量復制流程
Redis增量復制流程
不過,有一個地方我要強調一下,因為 repl_backlog_buffer 是一個環形緩沖區,所以在緩沖區寫滿后,主庫會繼續寫入,此時,就會覆蓋掉之前寫入的操作。如果從庫的讀取速度比較慢,就有可能導致從庫還未讀取的操作被主庫新寫的操作覆蓋了,這會導致主從庫間的數據不一致。
因此,我們要想辦法避免這一情況,一般而言,我們可以調整 repl_backlog_size 這個參數。這個參數和所需的緩沖空間大小有關。緩沖空間的計算公式是:緩沖空間大小 = 主庫寫入命令速度 * 操作大小 - 主從庫間網絡傳輸命令速度 * 操作大小。在實際應用中,考慮到可能存在一些突發的請求壓力,我們通常需要把這個緩沖空間擴大一倍,即 repl_backlog_size = 緩沖空間大小 * 2,這也就是 repl_backlog_size 的最終值。
舉個例子,如果主庫每秒寫入 2000 個操作,每個操作的大小為 2KB,網絡每秒能傳輸 1000 個操作,那么,有 1000 個操作需要緩沖起來,這就至少需要 2MB 的緩沖空間。否則,新寫的命令就會覆蓋掉舊操作了。為了應對可能的突發壓力,我們最終把 repl_backlog_size 設為 4MB。
這樣一來,增量復制時主從庫的數據不一致風險就降低了。不過,如果并發請求量非常大,連兩倍的緩沖空間都存不下新操作請求的話,此時,主從庫數據仍然可能不一致。
針對這種情況,一方面,你可以根據 Redis 所在服務器的內存資源再適當增加 repl_backlog_size 值,比如說設置成緩沖空間大小的 4 倍,另一方面,你可以考慮使用切片集群來分擔單個主庫的請求壓力。關于切片集群,我會在第 9 講具體介紹。
小結
我們一同深入研究了Redis的主從復制同步原理,總結來說,主要有三種同步模式:全量復制、基于長連接的命令傳播,以及增量復制。
全量復制雖然可能耗費時間,但對于從庫來說,在進行首次同步時,全量復制是不可避免的。因此,這里給出一個小建議:一個Redis實例的數據庫不應過于龐大,最好將其保持在幾GB的規模。這有助于減少RDB文件的生成、傳輸和重新加載所帶來的成本。此外,為了減輕主庫的同步壓力,以及避免多個從庫同時進行全量復制,可以采用"主-從-從"級聯同步模式。
長連接復制是主從復制在正常運行時采用的常規同步方式。在這個階段,主庫和從庫之間通過命令傳播來保持同步。然而,如果在此過程中出現了網絡斷連,增量復制就變得至關重要。我特別提醒注意repl_backlog_size配置參數。如果它設置得太小,在增量復制時,可能導致從庫的同步進度跟不上主庫,最終導致從庫需要重新進行全量復制。通過增大這個參數的值,可以降低從庫在網絡斷連時重新進行全量復制的風險。
然而,采用主從復制模式中的讀寫分離雖然能夠避免多個實例同時寫入引發的數據不一致問題,但仍然面臨主庫故障的潛在風險。如果主庫出現故障,從庫將如何應對?數據是否能夠保持一致?Redis是否能夠正常提供服務?在接下來的兩節課中,我們將深入探討在主庫故障后如何確保服務的可靠性。