













厲害了!用不到20行的Python代碼構建一個對象檢測模型
原創【51CTO.com原創稿件】當一張圖片顯示在眼前時,我們的大腦會馬上會識別出圖片里面所含的對象。另一方面,我們需要花費大量的時間和訓練數據才能讓機器識別這些對象。
不過鑒于硬件和深度學習方面最近的進步,這個計算機視覺領域變得容易和直觀了許多。
以下面這張圖片為例,該系統能夠識別圖片中的不同對象,準確度極高。

圖 1
現在對象檢測技術在各行各業已迅速得到了采用。它幫助自動駕駛汽車安全地行駛,在擁擠的場所發現暴力行為,協助球隊分析和制作選秀報告,確保制造零件得到適當的質量控制,不一而足。
這些僅僅是對象探測技術強大功能的幾個應用!在本文中我們將了解對象檢測是什么,看看可用來在該領域解決問題的幾種不同方法。
然后我們將深入研究使用 Python 構建我們自己的對象檢測系統。看完本文后,你將掌握足夠的知識,克服不同的對象檢測難題!
注意:本教程假設你了解了深度學習的基礎知識,之前已解決了簡單的圖像處理問題。
如果你還沒有或需要惡補一下,建議先閱讀下列文章:
- 《深度學習的基礎:從人工神經網絡開始》
- 《面向計算機視覺的深度學習:卷積神經網絡簡介》
- 《教程:使用Keras優化神經網絡(附有圖像識別案例研究)》
對象檢測是什么?
在我們開始構建最先進的模型之前,先了解一下對象檢測是什么。我們不妨假設為自動駕駛汽車構建一個行人檢測系統。
假設你開的汽車捕捉到如下圖這樣的圖像,你會如何描述這個圖像?

圖 2
該圖像實際上描繪了我們的汽車駛近廣場,幾個人在我們的車前方橫過馬路。
由于交通標志看不清楚,汽車的行人檢測系統應準確識別人們行走的位置,以便能避開他們。
那么,汽車的系統該怎樣確保避免行人呢?它能做的就是用邊界框將這些人圈出來,那樣系統就能準確識別圖像中行人的位置,然后相應地決定走哪條路,以免發生任何意外。

圖 3
我們做對象檢測有兩方面的目標:
- 識別圖像中的所有對象及其位置
- 過濾掉關注的對象
解決對象檢測問題的不同方法
我們已知道陳述的問題是什么,那么可以用哪種方法(或哪幾種方法)來解決問題呢?
在本節中我們將介紹可用于檢測圖像中對象的幾種技術。先從最簡單的方法開始介紹,然后逐漸深入。
方法 1:樸素方法(分治法)
我們可以采取的最簡單方法就是將圖像分解成四個部分:

圖 4:左上角

圖 5:右上角

圖 6:左下角

圖 7:右下角
下一步是將這每一個部分都饋送給圖像分類器。其輸出結果就是圖像的某部分有沒有行人。如果有行人,就在原始圖像中標記這個圖像塊(patch)。
輸出結果會像這樣:

圖 8
這是值得先試一下的好方法,但我們尋求的是一種準確性和精確性極高的系統。
它需要識別整個對象(或本文中的行人),因為僅僅定位對象的某些部分可能導致災難性的結果。
方法 2:增加分解數量
前一個系統做得很好,但我們還能做些什么?我們可以大幅增加輸入到系統的圖像塊的數量,以此改進該系統。
輸出結果應該是這樣:

圖 9
最終這有利也有弊。當然,我們的解決方案看起來比樸素方法好一點,但存在太多大同小異的邊界框。這是個問題,我們需要一種更結構化的方法來解決問題。
方法 3:執行結構化分解
為了以一種更結構化的方式構建對象檢測系統,我們可以遵照下列步驟:
第 1 步:將圖像分解成 10x10 網格,如下圖所示:

圖 10
第 2 步:為每個圖像塊定義質心(centroid)。
第 3 步:對于每個質心,取高度和縱橫比不一的三個不同的圖像塊,如下圖所示:
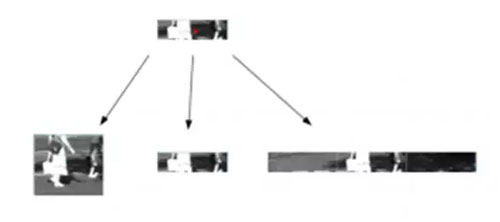
圖 11
第 4 步:讓創建的所有圖像塊過一遍圖像分類器,進行預測。
那么最終的輸出結果怎樣?當然更結構化一點、更規范化一點,請看下面:

圖 12
但我們可以進一步改進這方面!下面介紹獲得更好結果的另一種方法。
方法 4:提高效率
我們看到的前一種方法在很大程度上可以接受,但我們可以構建比它更高效一點的系統。
對此你有何建議?我首先想到的就是優化。如果我們考慮采用方法 3,可以做兩件事來改善模型。
增加網格大小
我們可以將網格大小增加到 20,而不是選擇 10。

圖 13
使用高度和縱橫比不一的更多圖像塊,而不是三個圖像塊
在這里,我們可以讓一個錨點(anchor)對應 9 個圖像塊,即 3 個高度不一的方形圖像塊和 6 個高度不一的垂直和水平矩形圖像塊。這將給我們帶來縱橫比不一的圖像塊。
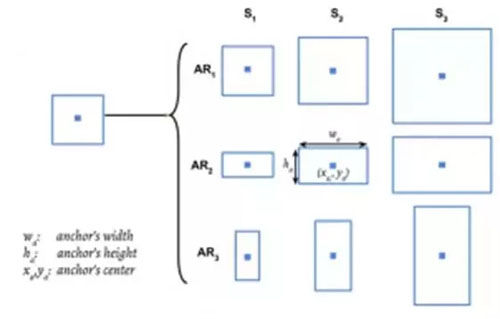
圖 14
這同樣有其優缺點。當然,這兩種方法都可以幫助我們更精細化。但它會再次生成不得不過一遍圖像分類器模型的眾多圖像塊。
我們能做的是,取用選擇性的圖像塊,而不是取用所有圖像塊。比如我們可以構建一個中間分類器,試著預測某圖像塊實際上有沒有背景,即可能含有一個對象。這將大大減少圖像分類器模型所看到的圖像塊。
我們能做的另一種優化就是減少表明“同一結果”的預測。不妨再以方法 3 的輸出結果為例:

圖 15
如你所見,兩個邊界框預測基本上是同一個人。我們可以選擇其中任何一個。
所以為了做預測,我們考慮“表明同一結果”的所有邊界框,然后選擇最有可能檢測到人的那個邊界框。
到目前為止,所有這些優化都給了我們效果相當不錯的預測。我們幾乎穩操勝券,但你猜到少了什么嗎?當然是少了深度學習!
方法 5:使用深度學習
使用深度學習用于特征選擇并構建端到端方法,深度學習在對象檢測領域大有潛力。我們可以在哪里利用深度學習來解決我們的問題?如何利用?
我在下面列出了幾種方法:
- 我們可以讓原始圖像過一遍神經網絡以減少維數,而不是取用來自原始圖像的圖像塊。
- 我們還可以使用神經網絡來建議選擇性的圖像塊。
- 我們可以強化深度學習算法,讓預測盡可能接近原始邊界框。這將確保算法給出更嚴謹、更精細的邊界框預測。
現在我們可以采用單個深度神經網絡模型來嘗試自行解決所有問題,而不是訓練不同的神經網絡來解決每一個問題。
這么做的優點是,神經網絡每個較小的部分將有助于優化同一個神經網絡的其他部分。這將幫助我們共同訓練整個深度模型。
輸出結果將帶來目前為止我們看到的所有方法中最佳的性能,有點類似于下圖。我們在下一節將看到如何使用 Python 來構建這個模型。

圖 16
如何使用 ImageAI 庫構建對象檢測模型?
我們已知道了對象檢測是什么、解決這個問題的最佳方法,現在不妨構建自己的對象檢測系統!
我們將使用 ImageAI(https://github.com/OlafenwaMoses/ImageAI),這個 Python 庫支持面向計算機視覺任務的最先進的機器學習算法。
運行對象檢測模型來獲得預測很簡單。我們不必操心復雜的安裝腳本即可入手,甚至不需要 GPU 來生成預測!我們將使用這個 ImageAI 庫來獲得在上面方法 5 中看到的輸出預測。
強烈建議你遵循下面的代碼(在你自己的機器上),因為這讓你能夠從本節獲得盡可能多的知識。
請注意,你在構建對象檢測模型之前需要設置好系統。一旦你在本地系統中安裝了 Anaconda,就可以開始執行下列步驟。
第 1 步:使用 Python 版本 3.6 創建 Anaconda 環境。
- conda create -n retinanet python=3.6 anaconda
第 2 步:激活該環境,安裝必要的程序包。
- source activate retinanet
- conda install tensorflow numpy scipy opencv pillow matplotlib h5py keras
第 3 步:隨后安裝 ImageAI 庫。
- pip install https://github.com/OlafenwaMoses/ImageAI/releases/download/2.0.1/imageai-2.0.1-py3-none-any.whl
第 4 步:現在下載生成預測所需要的預訓練模型。該模型基于 RetinaNet。
點擊鏈接即可下載:RetinaNet 預訓練模型(https://github.com/OlafenwaMoses/ImageAI/releases/download/1.0/resnet50_coco_best_v2.0.1.h5)。
第 5 步:將下載的文件復制到當前的工作文件夾。
第6 步:從該鏈接(https://s3-ap-south-1.amazonaws.com/av-blog-media/wp-content/uploads/2018/06/I1_2009_09_08_drive_0012_001351-768x223.png)下載圖像,將圖像命名為 image.png。
第 7 步:打開 jupyter 筆記本(在終端中輸入 jupyter notebook),運行下列代碼:
- from imageai.Detection import ObjectDetection
- import os
- execution_path = os.getcwd()
- detector = ObjectDetection()
- detector.setModelTypeAsRetinaNet()
- detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h5"))
- detector.loadModel()
- custom_objects = detector.CustomObjects(person=True, car=False)
- detections = detector.detectCustomObjectsFromImage(input_image=os.path.join(execution_path , "image.png"), output_image_path=os.path.join(execution_path , "image_new.png"), custom_objects=custom_objects, minimum_percentage_probability=65)
- for eachObject in detections:
- print(eachObject["name"] + " : " + eachObject["percentage_probability"] )
- print("--------------------------------")
這將創建一個名為 image_new.png 的修改后的圖像文件,文件含有圖像的邊界框。
第 8 步:想打印輸出圖像,請使用下列代碼:
- fromIPython.display import Image
- Image("image_new.png")

恭喜!你已自行構建了檢測行人的對象檢測模型。瞧瞧有多棒?
結束語
在本文中我們了解了對象檢測是什么以及構建對象檢測模型背后的機理。我們還了解了如何使用 ImageAI 庫來構建檢測行人的這個對象檢測模型。
只要稍稍改一下代碼,你就很容易改變模型,克服自己的對象檢測難題。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】




















