Java與CPU緩存是如何親密接觸的!
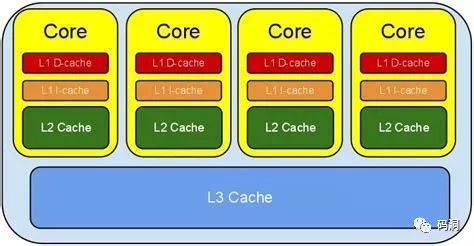
在解釋【偽共享】這個概念之前,我們先來運行一段代碼,小編的電腦上有4個core。

這個程序的邏輯是4個線程共享同一個數組讀寫不同下標的變量。每個線程循環1億次讀寫,也就是+1操作。然后統計4個線程同時跑完總共花的時間。
下面我們來看看在小編的電腦上運行的結果:
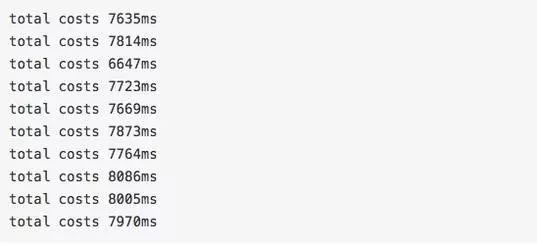
然后我把SharingLong里面的注釋代碼去掉,再跑了一下:

在性能上注釋前后差別高達5比1,為什么會在性能上會產生如此大的差別呢?
這就是本篇要講的主題【偽共享】,英文名叫False Sharing。而SharingLong里面的注釋行一般稱之為【緩存行填充】,英文名叫Cache Line Padding。
首先我們來計算一下SharingLong對象占用的內存空間,我們不考慮64位的情景,Java的對象都有一個2個word的頭部,***個word存儲對象的hashcode和一些特殊的位標志,如GC的分代年齡、偏向鎖標記等,第二個word存儲對象的指針地址,一個word就是32位。然后加上v和6個p變量,總共就是8個long的長度,也就是64字節。
接下來我們要引入CPU緩存的概念。
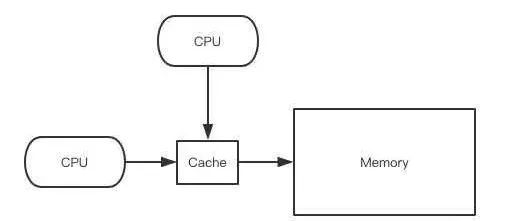
現代的處理器一般都有3級緩存結構,L1、L2和L3,CPU直接訪問主存是一個相對比較慢的操作,所以通過3級緩存來提升訪存性能。我們將3個緩存當成一個整體來看待,它就是CPU緩存。緩存的制造成本非常昂貴,它一般要比主存空間小的多。
CPU在讀主存的時候,會先將主存的一塊數據加載到緩存上,然后在緩存上讀取。當CPU寫主存的時候,它會首先寫緩存,在未來的某個時間點再一次性將緩存的數據全部刷回主存,這樣就可以提高寫操作的性能。因為計算機程序數據操作的局部性,CPU連續的指令傾向于訪問相鄰地址空間的數據,所以后續的讀寫操作有很大的概率可以直接在緩存上拿到數據。如果緩存上不存在,那就再去主存上加載進來。
緩存雖然小,但是也不是太小,CPU在加載主存數據時,如果一次性將整個Cache填滿,但是接下來的指令訪問的數據又不在緩存上,就會導致讀浪費。另外如果只修改了其中幾個字節的數據,但是得回寫整個Cache到內存,這又會導致寫浪費。
所以現代的CPU緩存一般是分行存儲的,最小處理單位是一個行,這個行的長度一般來說就是上文提到的64字節,我們稱之為【緩存行】。

SharingLong對象中v的值是volatile類型的,意味著CPU要保證v變量在不同線程之間的讀寫可見行。當CPU對v變量進行修改的時候會將數據立即回寫至主存并將相應的緩存行置為失效。這樣后續對v變量進行的讀寫操作都需要重新從內存中加載緩存行,這樣就保證了其它線程讀到的數據是***的。
這點跟我們平常在Java基礎教科書里提到的有點不一樣。教科書里面為了便于新手理解,不會提及緩存,一般只會說volatile變量直接讀寫內存。
如果內存里有兩個volatile變量在相鄰的地址,兩個cpu分別對v1和v2進行讀和寫操作,會發生什么情況呢?首先我們分解執行動作。圖中的h表示對象頭。
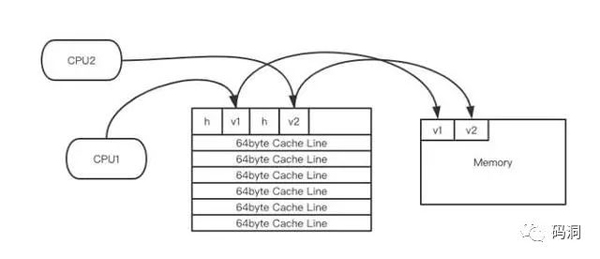
1、CPU1對v1進行讀操作,將內存里的v1加載到緩存行里。
2、CPU2對v2進行讀操作,將內存里的v2加載到緩存行里。
3、CPU1對v1進行寫操作,將緩存里的v1修改,然后回寫到主存再將緩存行置為失效。
4、CPU2對v2進行寫操作,將緩存里的v2修改,然后回寫到主存再將緩存行置為失效。
步驟1肯定先于步驟3,步驟2肯定先于步驟4。它們發生的順序可能是 1->2->3->4 ,相當于兩個CPU交疊運行,步驟1加載緩存行,步驟2發現數據就在緩存行里還是***的,就省去了加載緩存行操作了,這時讀操作做到了【共享】。緊接著步驟3正常進行寫操作,然后步驟4來了,CPU2發現緩存行失效了,所以還得重新加載緩存行,然后再回寫到主存再將緩存行置為失效。這里就發生了重復加載緩存行的現象,也即【寫競爭】。如果不是volatile變量,步驟3的寫操作是不會立即回寫內存的,緩存行也就不會立即置為失效,這個時候步驟4來了CPU可以直接對緩存進行寫操作,而不會出現浪費現象。我們稱這種現象為【偽共享】,就是說這兩個變量雖然共享同一個緩存行,但是它們之間會發生寫競爭。
如果順序是1->3->2->4,步驟1和步驟3的讀操作這時就沒能實現共享,還是會有浪費。
當系統的線程數越多時,寫競爭越激烈,這種浪費就越多。
現在我們能明白為什么去掉注釋后,程序會變慢,因為存在寫競爭現象,數組中相鄰的SharingLong.v共享了同一個緩存行。
那加上p1~p6這6個變量的意義是什么呢?我們看圖。
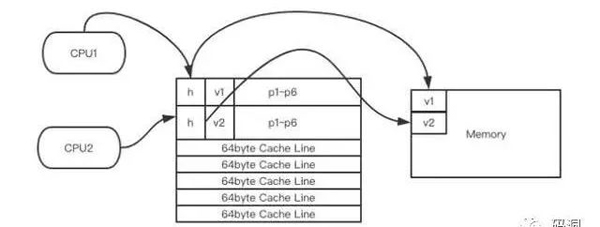
我們發現加上6個long變量后,v1和v2將分別占用自己的緩存行,互不干擾,所以寫競爭也就不存在了,效率自然就提升了。
不過缺點也是有的,就是緩存的利用率降低了,一個緩存行的空間才使用了1/4。這就是典型的空間換時間的場景。
例子中我們使用了volatile變量,那如果改成普通變量呢?我們運行一下,結果如下。

相當驚人,耗時上居然少了3個量級,這就是volatile在性能上的代價。普通變量不需要保證線程之間的讀寫的可見性,CPU對緩存修改后不需要立即回寫內存,不存在寫操作緩存穿透現象。而讀操作也不需要總是重新從內存加載,那這個效率幾乎完全就是緩存訪問的效率,而對volatile變量的讀寫操作則接近內存訪問的效率,差距自然如此明顯。
你也許會問,知道這些有什么蛋用!
確是沒什么蛋用,因為在現實世界,大部分操作都涉及到IO操作。根據水桶效應,其它環節優化到了***,也無法提升整體的質量。
但是也不完全所有的應用都是IO操作型的,有一些場景下那是純粹的內存操作。那么對于純內存操作來說,理解【偽共享】知識可以幫你從性能上提升幾倍甚至是幾個數量級。
著名的disruptor框架正是使用了緩存行填充技術,才使得它的環形數組隊列能如此高效。看wiki上的性能報告,disruptor的RingBuffer相比Java內置的ArrayBlockingQueue在OPS上高出近一個數量級,在隊列延遲上則低了接近3個數量級。