58速運(yùn)架構(gòu)實(shí)戰(zhàn):拆分服務(wù)與DB,突破“中心化”瓶頸
很高興有這次機(jī)會,跟大家分享一下我們 58 速運(yùn)微信小程序的事件。我是后端平臺的負(fù)責(zé)人,從 2017 年底開始負(fù)責(zé)我們 58 速運(yùn)的微信小程序的開發(fā)工作。
本次分享主要從以下幾個方面來進(jìn)行:
- 58 速運(yùn)模式
- 小程序的意義
- 小程序架構(gòu)實(shí)戰(zhàn)
- 總結(jié)
58 速運(yùn)模式
58 速運(yùn)是覆蓋中國及東南亞地區(qū)的同城貨運(yùn)平臺,2018 年開始了全新的速運(yùn) 2.0 時代:
速運(yùn)模式
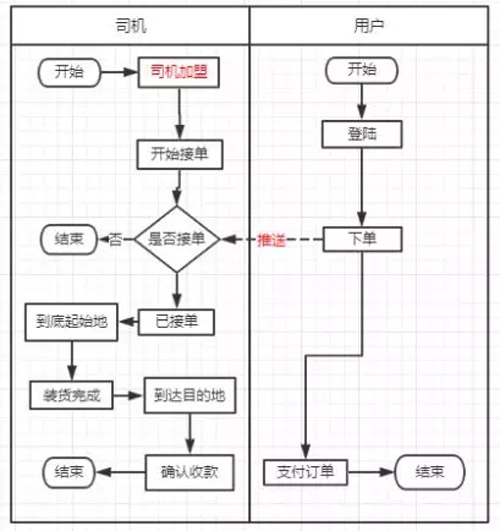
司機(jī)通過司機(jī)加盟的流程加入到我們,登錄司機(jī)端 APP,就可以開始接單了;而用戶通過 APP 或者是用戶端的 H5 登錄上去,可以跟司機(jī)下單,我們的推送系統(tǒng)經(jīng)過一系列的算法,推送給附近的司機(jī),然后司機(jī)搶單,到達(dá)目的地,將賬單發(fā)送給用戶,用戶確定定單、收款,這個過程就結(jié)束了。
小程序的意義
那么問題來了,有了我們司機(jī)端的 APP 和用戶端,為什么還要做微信小程序呢,它對我們的 58 速運(yùn)究竟有什么意義呢?
首先來解釋一下什么是速運(yùn)的 2.0。
在舊的 1.0 時代,司機(jī)只能通過加盟接單,并且想要成功接單還需要一系列的審核流程,因?yàn)槲覀円WC服務(wù)質(zhì)量,之后再登錄我們的 APP 才能完成。
我們對司機(jī)有一系列的審核、管理工作。用戶登錄我們的 APP 以后,只能給我們的平臺司機(jī)下單。
速運(yùn) 2.0 就是要把這個中心化的過程打破,要做去中心化的過程。
司機(jī)只要登錄了司機(jī)端的微信小程序就能夠接單,不用加盟;用戶登錄微信小程序,就能給所有的司機(jī)下單,不管這個司機(jī)是否在我們的平臺注冊過。
小程序的架構(gòu)實(shí)戰(zhàn)
現(xiàn)有架構(gòu)
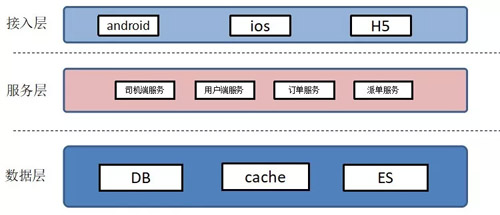
這是現(xiàn)有的架構(gòu),如上圖:
- 接入層有安卓、iOS、H5;
- 服務(wù)層就是司機(jī)端服務(wù)、用戶端服務(wù),定單服務(wù)、派單服務(wù);
- 數(shù)據(jù)層比如說 ES、DB 等等。
可以看到,我們的服務(wù)層都是一個個大而全的系統(tǒng),業(yè)務(wù)發(fā)展的過程中,前期的業(yè)務(wù)功能并不復(fù)雜,一個系統(tǒng)一個服務(wù)就能夠滿足我們所有的業(yè)務(wù)現(xiàn)狀,而且開發(fā)起來也比較快。
當(dāng)我們的業(yè)務(wù)達(dá)到了一定的量級之后,這一個大而全的服務(wù)就會阻礙我們業(yè)務(wù)的發(fā)展,我們很多的團(tuán)隊(duì)在維護(hù)一個服務(wù),就會出現(xiàn)很多的問題。
比如說我們開發(fā)的過程中就會有上線沖突;當(dāng)業(yè)務(wù)達(dá)到一定的量級之后,DB 壓力也很大。我們現(xiàn)在正在進(jìn)行的一項(xiàng)工作就是對服務(wù)和 DB 的一個拆分。
小程序功能
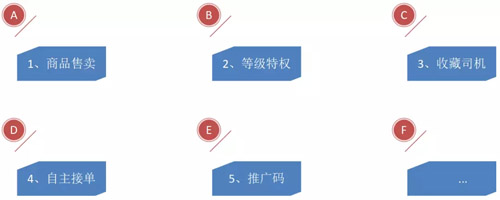
架構(gòu)肯定是為業(yè)務(wù)而設(shè)計(jì)的,那么我們的小程序有哪些功能?
對于用戶來說,首先就是有一個會員商品的售賣;其次,用戶只要購買了我們的會員商品,就會有一些會員等級;此外還有收藏司機(jī)的功能、用推廣碼下單的功能,如果用戶掃描了這個碼,就可以直接給司機(jī)下單。
那么針對司機(jī)來說有哪些功能?就是登錄了微信小程序后會有一個二維碼,司機(jī)可以自主接單。
面對這些功能,我們的思路是:
- 避免大而全,我們就要對這些功能進(jìn)行一個個的拆分,拆分成一個個的服務(wù);
- 從簡單的開始著手,逐步進(jìn)行細(xì)化的過程;
- 微服務(wù)的架構(gòu),方便后續(xù)的拓展和維護(hù)。
會員服務(wù)和用戶等級
來分析一下會員服務(wù)和用戶等級。為什么把它們兩個一塊兒說?因?yàn)樗鼈兊暮诵墓δ茳c(diǎn)比較相似:
- 會員服務(wù)就是買了會員商品后會有的等級和特權(quán);
- 而如果用戶一個月下單數(shù)達(dá)到一定的階段,就會有用戶的等級和特權(quán)。
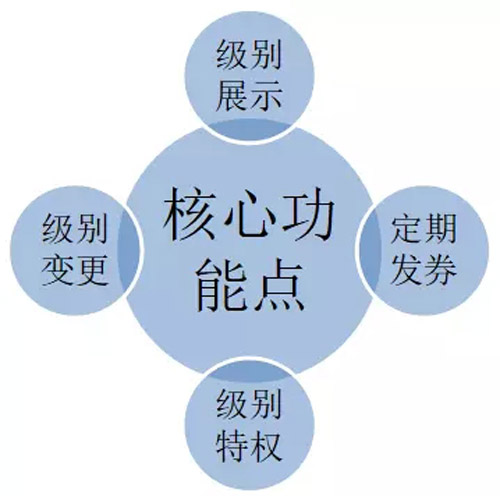
它們的核心功能點(diǎn)就是級別的展示、授權(quán)以及定期的發(fā)券。

首先是 Web 層,還有服務(wù)層。有升級就有降級,針對降級,我們使用的是定時任務(wù)來處理。
如果你單機(jī)部署,那這臺機(jī)器掛了怎么辦?如果是部署多臺,那同時跑了怎么辦?
我們有一個自研的基于 ZK 的調(diào)度平臺,在跑的時候,首先會出一個臨時節(jié)點(diǎn),說明自己在跑,當(dāng)機(jī)器掛掉之后,節(jié)點(diǎn)就消失;另一個到達(dá)時間節(jié)點(diǎn)的時候,就會在另外的一個機(jī)器上面跑,保證一個時間點(diǎn)只能有一個機(jī)器在跑這個 Job。
我們的用戶等級升級是要求比較高的,比如說用戶買了一個商品,立馬就希望等級升上去。我們使用了一個消息隊(duì)列,保證我們收到消息之后,立馬把用戶的等級升上去。
還有定時發(fā)券的場景,我們使用了延時消息,我們在用戶發(fā)券之后去判斷是否還需要發(fā)券,如果還需要的話,就接著發(fā)一個延時消息。
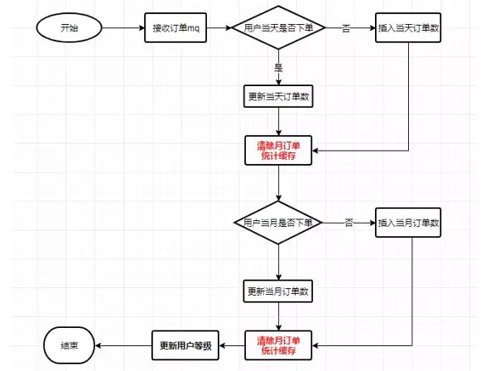
用戶等級服務(wù)的核心功能點(diǎn)之一,是根據(jù)用戶當(dāng)月的訂單數(shù)來實(shí)時地更新用戶等級。
一般情況下,統(tǒng)計(jì)當(dāng)月的訂單數(shù),都是使用定時任務(wù)每隔一段時間去計(jì)算。但是,因?yàn)槲覀儗?shí)時性要求較高,這樣做并不合適。
所以我們使用了接收訂單完成的 MQ 來實(shí)時進(jìn)行計(jì)算。我們的做法是,先根據(jù) MQ 實(shí)時更新每天的訂單數(shù),保證每天的訂單數(shù)可查,同時更新每月的訂單數(shù)。
通常情況下,在更新當(dāng)月的訂單數(shù)之前或者是之后,只需要清除一次緩存就行了,但是我們清除了兩次,為什么?
用戶訪問了自己的用戶等級,可能會出現(xiàn)一種情況就是用戶看到的這個數(shù)據(jù)并不對,數(shù)據(jù)不一致。使用雙緩存清除法能解決這個問題。流程如下圖所示:
商品服務(wù)

會員商品服務(wù)的典型場景有四種:
- 讀多寫少;
- 商品不可變;
- 針對單個的商品和用戶是有一個限購的條件的;
- 商品有可能會有一些庫存的限制。
比如說我就想賣 100 個,針對這個場景我們能不能很簡單的一個 Web、一個服務(wù)加上存儲就搞得定呢?如果商品賣出去了,緩存是不是就失效了?
我們?nèi)绾伪WC商品緩存的時效性?如果我的庫存這一塊兒出現(xiàn)了問題,那是不是商品會受到影響?比如說庫存導(dǎo)致我們的服務(wù)掛了,那商品直接看不到……

針對這些問題,我們處理的方式:
- 首先就是將這個可變的數(shù)據(jù)隔離,將商品服務(wù)不做成一個服務(wù);
- 針對消息一經(jīng)發(fā)布不可變,而且訪問量很大的問題,可以通過加緩存來緩解壓力;
- 至于怎么保持庫存的一致性,就是用 CAS 樂觀鎖來保證庫存服務(wù)的效率。
司機(jī)的 GPS 服務(wù)
我們是一個同城貨運(yùn)平臺,大部分的場景是用戶下單,司機(jī)接單。我們有 100 萬的注冊司機(jī),要保證司機(jī)實(shí)時的 GPS 位置準(zhǔn)確,2 秒鐘上傳一次 GPS,這個請求量是特別大的。
但 GPS 的服務(wù)對我們的實(shí)時性的要求又非常高,所以 MySQL 的壓力非常大,如果再上一個層次,MySQL 肯定扛不住;如果放在緩存里面,又有另外的問題,也就是緩存無法搜索的情況;還有怎么樣提高處理效率的問題。
針對這幾個問題,我們的做法:
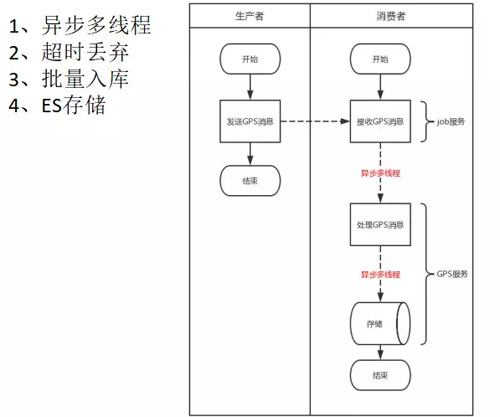
使用了生產(chǎn)者消費(fèi)者模式,生產(chǎn)者發(fā)送 MQ 給消費(fèi)者,消費(fèi)者本身是一個 Job。接到消息后,先進(jìn)行時效性的判斷,如果超時,直接丟棄。
如果沒有超時,異步調(diào)用 GPS 服務(wù)。GPS 服務(wù)接到調(diào)用后,先放到一個隊(duì)列里面,然后后臺有一個線程,批量地進(jìn)行 ES 的存儲。
訂單服務(wù)

現(xiàn)狀:
我們碰到的問題,主要是老訂單因?yàn)闃I(yè)務(wù)的發(fā)展對我們的小程序已經(jīng)不太適用;老訂單的服務(wù)根據(jù)前臺的業(yè)務(wù)進(jìn)行了一個分表的處理,后臺是一個單表,我們后臺的單表查詢會非常的慢。
前后臺是采用了 canal 的方式同步的,最大的時候前后臺訂單有 6 個小時的同步,目前訂單已經(jīng)是 40 萬的數(shù)據(jù)了。之前前臺的訂單服務(wù)、后臺的訂單服務(wù)包括訂單的 ES 服務(wù),很多人在調(diào)用的時候其實(shí)根本不知道調(diào)用哪些服務(wù)。
我們的思路,第一,訂單服務(wù)要統(tǒng)一成一個;第二,我們要采用分庫的方式來實(shí)現(xiàn)。
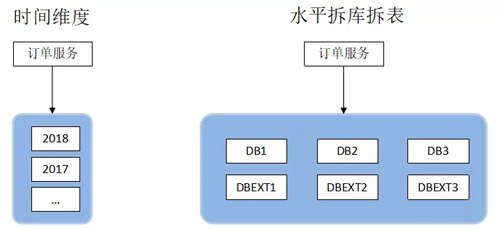
一般有水平拆分和垂直拆分:
第一想到的就是能不能把我們的數(shù)據(jù)進(jìn)行一個隔離,比如說按照時間段做一個垂直的,2017 年的放一個庫,2018 年的放一個庫。
第二,水平的拆庫拆表。首先用戶肯定要查詢自己的訂單列表的,司機(jī)也需要查詢,然后大部分的場景其實(shí)是司機(jī)的查看訂單詳情,還有我們公司自己的后臺的運(yùn)營人員,有一些復(fù)雜的查詢。
那么如何確定我們的分庫方案?

按照時間緯度的優(yōu)點(diǎn)是訂單分到最新時間段的庫,直接查就行了,缺點(diǎn)在于如何確定時間緯度,一個月、一個季度或者是一兩年。
還有一個問題就是說,如果確定了時間緯度之后,訂單還有大的增長怎么辦?我們的庫是提前建好還是動態(tài)申請,資源上面也要權(quán)衡。

水平拆分,訂單如果再有一個上升的階段,就直接橫向擴(kuò)展了。我們也要解決跨庫查詢,也需要訂閱方案。
我們 85% 的查詢是根據(jù)訂單的 ID 來查詢的,比如說大部分的司機(jī)搶單,查看訂單詳情;用戶下單查看詳情之類的。
接下來會有 10% 的用戶查看自己的 ID,我到底下了哪些單,或者是歷史的訂單是什么樣子的。
還有 4% 是根據(jù)司機(jī)的場景來查詢,只是偶爾空閑的時候他才會查自己今天搶多少單,最后只有 1% 的后臺復(fù)雜查詢,所以可以往后考慮。
如果需要滿足 85% 的場景,根據(jù)用戶 ID 來取模行不行?但是問題是司機(jī) ID 的列表查詢怎么來解決呢?方案就是索引表。

我需要查詢?nèi)蝿?wù),根據(jù)業(yè)務(wù)和訂單 ID 來建立索引表,就可以查到所有的訂單,然后能確定每一個庫,就能搞定場景。
但是我們的數(shù)據(jù)量達(dá)到一定的階段,索引表也需要分庫怎么辦?這樣所有的用戶的東西都在一個庫里面,查詢用戶列表的時候就不用分庫了,這樣解決了我們 10% 的問題,那 80% 多的問題怎么解決?就是基因法。

根據(jù)用戶 ID 得到的數(shù)字,其實(shí)就是我們的分庫基因,大家都知道 Java 里面是 64 位的數(shù)字,前 40 位用做一個時間,這個時間并不是說我們直接調(diào)用系統(tǒng)的當(dāng)前時間,而是拿 2018 年,拿一個固定的起始時間。
比如說 2018 年 1 月 1 號,再用當(dāng)前的時間減去起始時間的毫秒數(shù),得到的時間左移 23 位,放到我們的 40 位的位置。
接下來的是我們的機(jī)器位,為什么會這樣呢?因?yàn)槲覀兊?ID 生成器不可能是在單機(jī)上面用的,是在多個機(jī)器上面用。
接下來的是我們的分庫基因,還有自動的序列,是為了保證同一毫秒生成的 ID 不會有重復(fù)。
比如說同一秒內(nèi)支持的 ID 生成是 6 萬多個,如果不夠用怎么辦?將時間的秒數(shù)量再加一就可以了。
ID 生成搞定了,怎么根據(jù)這個生成找到我們所在的庫?下面這個其實(shí)就是一個反向的過程,能確定到我們的一個庫。
解決了 95% 的場景,剩下的怎么搞?使用 ES 就行了。
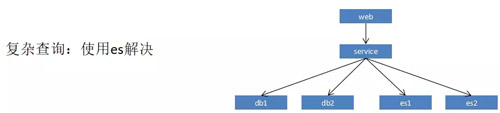
因?yàn)樗緳C(jī)不會實(shí)時的去查看自己的訂單,運(yùn)維人員對訂單的實(shí)時性要求也并不高,所以說直接使用 ES 就行了,最后我們的訂單服務(wù)就是這個樣子。
做一個總結(jié),就是按照用戶的緯度來分布,訂單 ID 使用 Snowflake 算法生成,訂單中記錄分庫因子,然后復(fù)雜查詢使用 ES 來解決。
老舊服務(wù)的兼容
這樣的話訂單服務(wù)并沒有完,我們還有老舊的服務(wù)必須做一個兼容:

針對訂單的寫,我們是做了一個雙寫,寫了新訂單之后,會去同步寫一次老訂單;針對訂單的讀,我們是先查詢新訂單,如果查不到,會在老訂單里面查一遍再返回客戶端;我們對歷史數(shù)據(jù)也有一套完整的遷移方案。
推送服務(wù)的改造
微信小程序還涉及到了推送服務(wù)的兩個方面的改造:
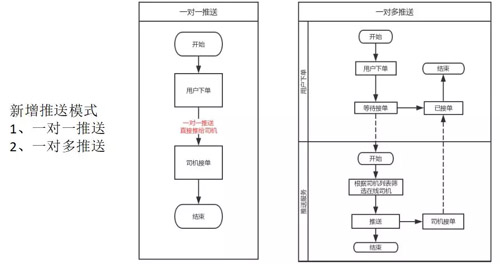
因?yàn)槲覀冃略隽藘煞N推送模式:
- 一對一的推送,相對來說比較簡單,下單的時候,如果用戶選擇的是一對一推送的,比如說用戶只選了一個司機(jī),我們就默認(rèn)司機(jī)就是中單了,不管這個司機(jī)在不在線,如果能推給司機(jī)就推給他,如果不能推給他,就給他發(fā)一個短信。
- 一對多的推送,省去了推送的算法,用戶選擇多個司機(jī),然后我們的系統(tǒng)根據(jù)用戶篩選的司機(jī),挑選出在線的列表,然后全部推送給那些司機(jī),直到司機(jī)又搶單就結(jié)束了。
這是我們改造之后的一個微信小程序的總體架構(gòu)圖:
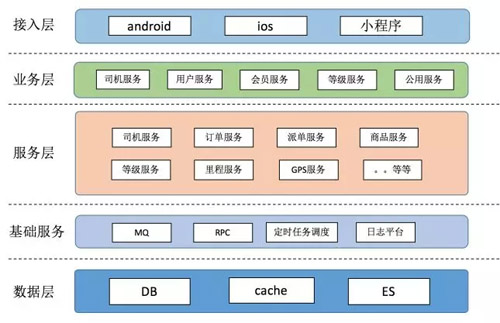
我們分了接入層、業(yè)務(wù)層、服務(wù)層、基礎(chǔ)服務(wù)、數(shù)據(jù)層。接入層就是對每一個服務(wù)做了一個劃分,進(jìn)行了一層業(yè)務(wù)的評定之類的,反饋給我們的接入層。
我們的程序想要上線,首先要接入我們的服務(wù)治理平臺:
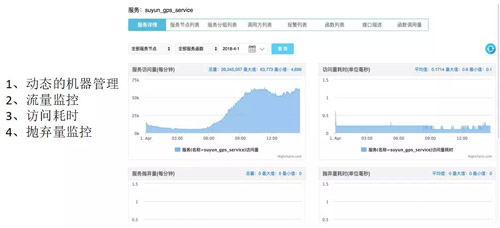
我們的服務(wù)治理平臺會提供一些功能:
- 動態(tài)機(jī)器的管理,比如說我們的業(yè)務(wù)撐不住了,可以通過這個加一點(diǎn)機(jī)器;
- 對整個服務(wù)的流量的監(jiān)控;
- 訪問耗時的監(jiān)控;
- 還有我們的拋棄量監(jiān)控。
接下來就是接入我們的監(jiān)控平臺,會有針對的關(guān)鍵字監(jiān)控,也有 URL 的監(jiān)控,針對不同的監(jiān)控有一些監(jiān)控的策略。
最后就是接入我們的 Dtrack 調(diào)用鏈,可以知道整個服務(wù)之間的調(diào)用關(guān)系:

如果服務(wù)的量級上來了,那么我們可能自己都不知道是調(diào)用了哪個服務(wù),它的層次關(guān)系靠人已經(jīng)分不清了。如果接入調(diào)用鏈的話,會打印出一個服務(wù)的清晰的調(diào)用關(guān)系。

- 它給我們提供了全局跟蹤,比如說調(diào)用了哪些服務(wù),耗時有多少;
- 哪個服務(wù)有問題的,會立馬有一個異常的報警;
- 針對服務(wù)之間會有清晰調(diào)用結(jié)構(gòu);
- 對整個服務(wù)也會有一個效果監(jiān)測。
它的技術(shù)點(diǎn)在哪兒:

我們在框架里面提供了插件,每一次調(diào)用的時候,就會形成 traceid,通過框架傳遞下去,每調(diào)用一個服務(wù),它的 ID 會 +1。將這些調(diào)用關(guān)系通過日志打印出來,通過 Flume 采集之后展現(xiàn)出來就行了。
總結(jié)
最后總結(jié)一下,準(zhǔn)確的理解需求很重要,架構(gòu)是為業(yè)務(wù)服務(wù)的;碰到一個大的需求,對需求進(jìn)行拆分,由簡單到復(fù)雜的拆分;根據(jù)業(yè)務(wù)需求進(jìn)行合適的技術(shù)選型,任何脫離業(yè)務(wù)的架構(gòu)設(shè)計(jì)都是耍流氓,監(jiān)控特別的重要,謝謝大家。
張凱,58 速運(yùn)后端平臺部負(fù)責(zé)人。7 年開發(fā)經(jīng)驗(yàn),涉及 CRM、微信錢包、卡券系統(tǒng)等;參與 58 到家錢包入口的優(yōu)化拆分改版,保證了系統(tǒng)平穩(wěn)過渡;參與 58 大促,保證了大促期間卡券系統(tǒng)的穩(wěn)定運(yùn)行。現(xiàn)在負(fù)責(zé)后端平臺的開發(fā)工作。