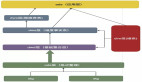
Uber永久定位系統實時數據分析過程實踐!
根據Gartner所言,到2020年,每個智慧城市將使用約13.9億輛聯網汽車,這些汽車配備物聯網傳感器和其他設備。城市中的車輛定位和行為模式分析將有助于優化流量,更好的規劃決策和進行更智能的廣告投放。例如,對GPS汽車數據分析可以允許城市基于實時交通信息來優化交通流量。電信公司正在使用移動電話定位數據,識別和預測城市人口的位置活動趨勢和生存區域。
本文,我們將討論在數據處理管道中使用Spark Structured Streaming對Uber事件數據進行聚類分析,以檢測和可視化用戶位置實踐。(注:本文所用數據并非Uber內部實際用戶數據,文末附具體代碼或者示例獲取渠道)
首先,我們回顧幾個結構化流媒體涉及的概念,然后探討端到端用例:
使用MapR-ES發布/訂閱事件流
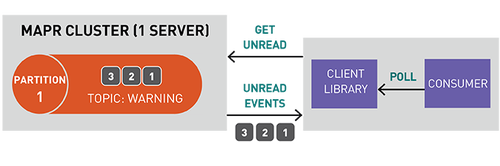
MapR-ES是一個分布式發布/訂閱事件流系統,讓生產者和消費者能夠通過Apache Kafka API以并行和容錯方式實時交換事件。
流表示從生產者到消費者的連續事件序列,其中事件被定義為鍵值對。
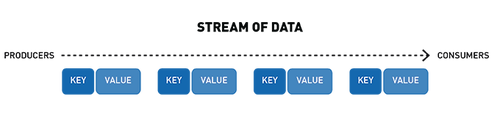
topic是一個邏輯事件流,將事件按類別區分,并將生產者與消費者分離。topic按吞吐量和可伸縮性進行分區,MapR-ES可以擴展到非常高的吞吐量級別,使用普通硬件可以輕松實現每秒傳輸數百萬條消息。
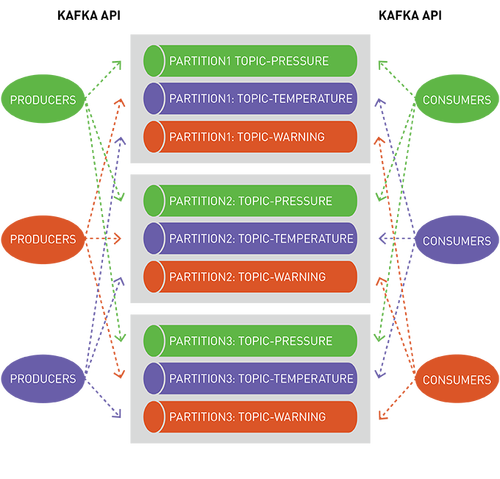
你可以將分區視為事件日志:將新事件附加到末尾,并為其分配一個稱為偏移的順序ID號。
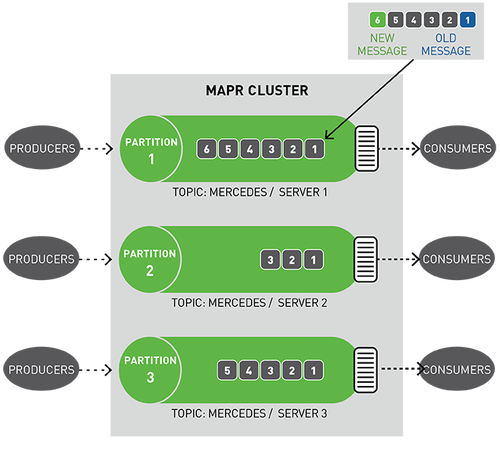
與隊列一樣,事件按接收順序傳遞。
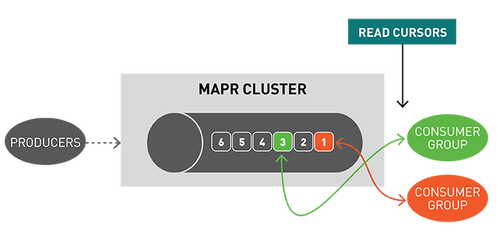
但是,與隊列不同,消息在讀取時不會被刪除,它們保留在其他消費者可用分區。消息一旦發布,就不可變且永久保留。
讀取消息時不刪除消息保證了大規模讀取時的高性能,滿足不同消費者針對不同目的(例如具有多語言持久性的多個視圖)處理相同消息的需求。
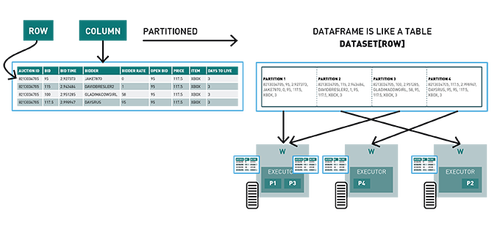
Spark數據集,DataFrame,SQL
Spark數據集是分布在集群多個節點上類對象的分布式集合,可以使用map,flatMap,filter或Spark SQL來操縱數據集。DataFrame是Row對象的數據集,表示包含行和列的數據表。
Spark結構化流
結構化流是一種基于Spark SQL引擎的可擴展、可容錯的流處理引擎。通過Structured Streaming,你可以將發布到Kafka的數據視為無界DataFrame,并使用與批處理相同的DataFrame,Dataset和SQL API處理此數據。
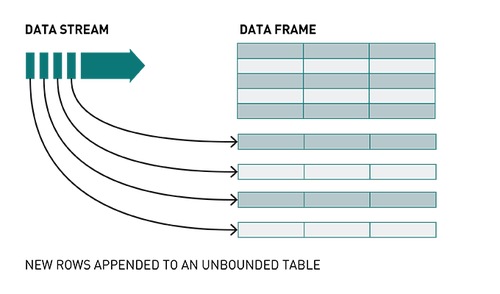
隨著流數據的不斷傳播,Spark SQL引擎會逐步持續處理并更新最終結果。
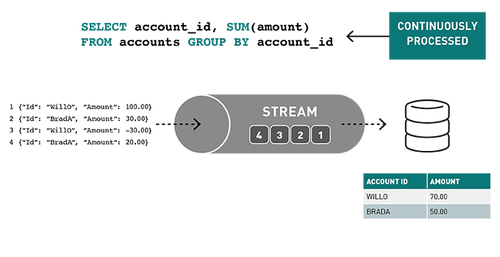
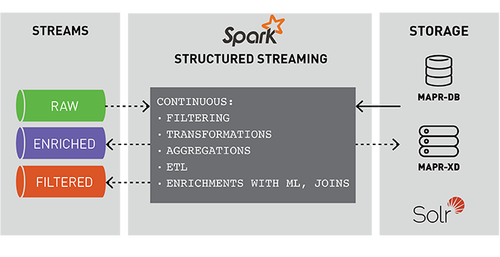
事件的流處理對實時ETL、過濾、轉換、創建計數器、聚合、關聯值、豐富其他數據源或機器學習、持久化文件或數據庫以及發布到管道的不同topic非常有用。
Spark結構化流示例代碼
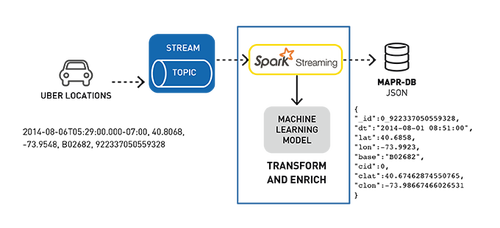
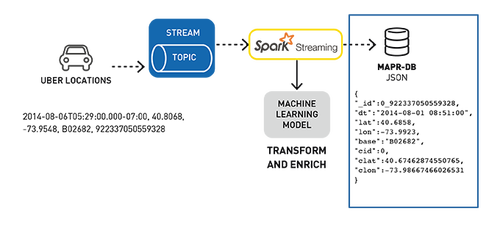
下面是Uber事件數據聚類分析用例的數據處理管道,用于檢測位置。
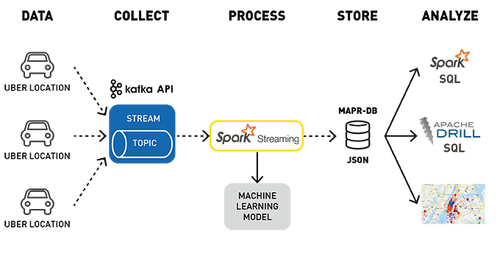
使用Kafka API將行車位置數據發布到MapR-ES topic
訂閱該topic的Spark Streaming應用程序:
- 輸入Uber行車數據流;
- 使用已部署的機器學習模型、集群ID和位置豐富行程數據;
在MapR-DB JSON中存儲轉換和豐富數據。
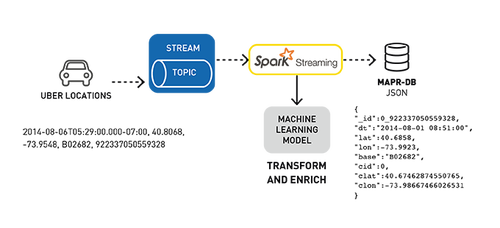
用例數據示例
示例數據集是Uber旅行數據,傳入數據是CSV格式,下面顯示了一個示例,topic依次為:
日期/時間,緯度,經度,位置(base),反向時間戳
2014-08-06T05:29:00.000-07:00,40.7276,-74.0033,B02682,9223370505593280605
我們使用集群ID和位置豐富此數據,然后將其轉換為以下JSON對象:
- {
- "_id":0_922337050559328,
- "dt":"2014-08-01 08:51:00",
- "lat":40.6858,
- "lon":-73.9923,
- "base":"B02682",
- "cid":0,
- "clat":40.67462874550765,
- "clon":-73.98667466026531
- }
加載K-Means模型
Spark KMeansModel類用于加載k-means模型,該模型安裝在歷史uber行程數據上,然后保存到MapR-XD集群。接下來,創建集群中心ID和位置數據集,以便稍后與Uber旅行位置連接。

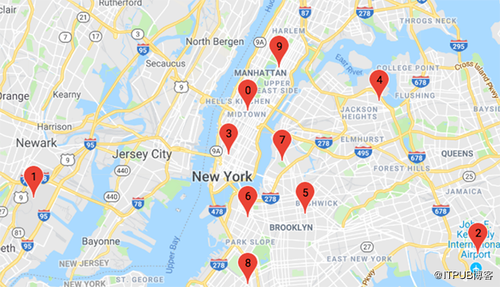
集群中心下方顯示在Zeppelin notebook中的Google地圖上:
從Kafka的topic中讀取數據
為了從Kafka讀取,我們必須首先指定流格式,topic和偏移選項。有關配置參數的詳細信息,請參閱MapR Streams文檔。

這將返回具有以下架構的DataFrame:

下一步是將二進制值列解析并轉換為Uber對象的數據集。
將消息值解析為Uber對象的數據集
Scala Uber案例類定義與CSV記錄對應的架構,parseUber函數將逗號分隔值字符串解析為Uber對象。

在下面的代碼中,我們使用parseUber函數注冊一個用戶自定義函數(UDF)來反序列化消息值字符串。我們在帶有df1列值的String Cast的select表達式中使用UDF,該值返回Uber對象的DataFrame。

使用集群中心ID和位置豐富的Uber對象數據集
VectorAssembler用于轉換并返回一個新的DataFrame,其中包含向量列中的緯度和經度要素列。


k-means模型用于通過模型轉換方法從特征中獲取聚類,該方法返回具有聚類ID(標記為預測)的DataFrame。生成的數據集與先前創建的集群中心數據集(ccdf)連接,以創建UberC對象的數據集,其中包含與集群中心ID和位置相結合的行程信息。


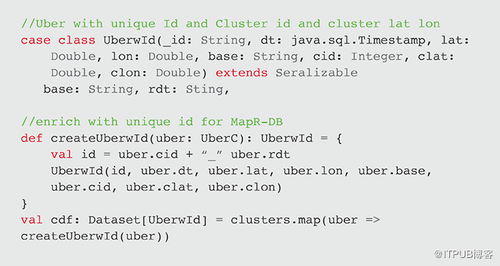
最后的數據集轉換是將唯一ID添加到對象以存儲在MapR-DB JSON中。createUberwId函數創建一個唯一的ID,包含集群ID和反向時間戳。由于MapR-DB按id對行進行分區和排序,因此行將按簇的ID新舊時間進行排序。 此函數與map一起使用以創建UberwId對象的數據集。
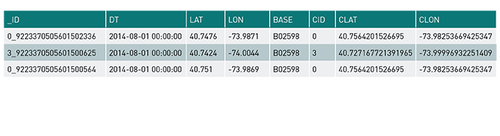
接下來,為了進行調試,我們可以開始接收數據并將數據作為內存表存儲在內存中,然后進行查詢。

以下是來自 %sqlselect * from uber limit 10 的示例輸出:
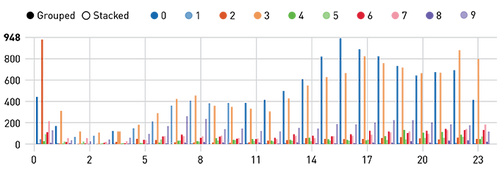
現在我們可以查詢流數據,詢問哪段時間和集群內的搭乘次數最多?(輸出顯示在Zeppelin notebook中)
- %sql
SELECT hour(uber.dt) as hr,cid, count(cid) as ct FROM uber group By hour(uber.dt), cid
Spark Streaming寫入MapR-DB
用于Apache Spark的MapR-DB連接器使用戶可以將MapR-DB用作Spark結構化流或Spark Streaming的接收器。
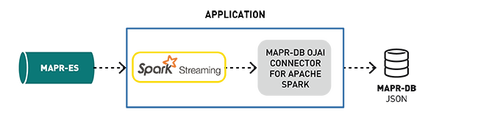
當你處理大量流數據時,其中一個挑戰是存儲位置。對于此應用程序,可以選擇MapR-DB JSON(一種高性能NoSQL數據庫),因為它具有JSON的可伸縮性和靈活易用性。
JSON模式的靈活性
MapR-DB支持JSON文檔作為本機數據存儲。MapR-DB使用JSON文檔輕松存儲,查詢和構建應用程序。Spark連接器可以輕松地在JSON數據和MapR-DB之間構建實時或批處理管道,并在管道中利用Spark。

使用MapR-DB,表按集群的鍵范圍自動分區,提供可擴展行和快速讀寫能力。在此用例中,行鍵_id由集群ID和反向時間戳組成,因此表將自動分區,并按最新的集群ID進行排序。
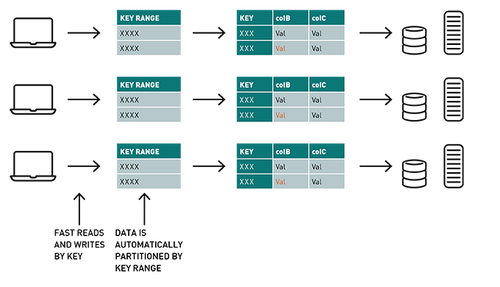
Spark MapR-DB Connector利用Spark DataSource API。連接器體系結構在每個Spark Executor中都有一個連接對象,允許使用MapR-DB(分區)進行分布式并行寫入,讀取或掃描。
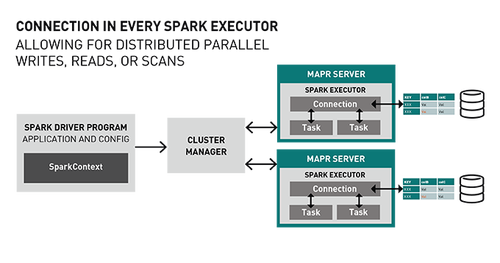
寫入MapR-DB接收器
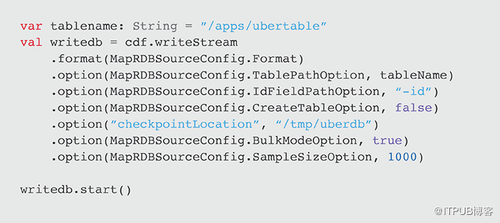
要將Spark Stream寫入MapR-DB,請使用tablePath,idFieldPath,createTable,bulkMode和sampleSize參數指定格式。以下示例將cdf DataFrame寫到MapR-DB并啟動流。
使用Spark SQL查詢MapR-DB JSON
Spark MapR-DB Connector允許用戶使用Spark數據集在MapR-DB之上執行復雜的SQL查詢和更新,同時應用投影和過濾器下推,自定義分區和數據位置等關鍵技術。
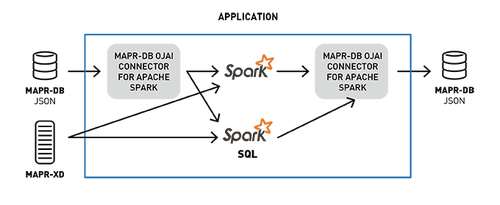
將數據從MapR-DB加載到Spark數據集中
要將MapR-DB JSON表中的數據加載到Apache Spark數據集,我們可在SparkSession對象上調用loadFromMapRDB方法,提供tableName,schema和case類。這將返回UberwId對象的數據集:


使用Spark SQL探索和查詢Uber數據
現在,我們可以查詢連續流入MapR-DB的數據,使用Spark DataFrames特定于域的語言或使用Spark SQL來詢問。
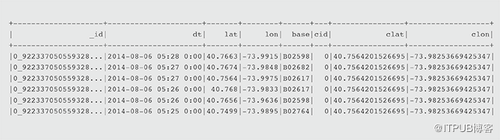
顯示第一行(注意行如何按_id分區和排序,_id由集群ID和反向時間戳組成,反向時間戳首先排序最近的行)。
- df.show
每個集群發生多少次搭乘?
- df.groupBy("cid").count().orderBy(desc( "count")).show

或者使用Spark SQL:
- %sql SELECT COUNT(cid), cid FROM uber GROUP BY cid ORDER BY COUNT(cid) DESC
使用Zeppelin notebook中的Angular和Google Maps腳本,我們可以在地圖上顯示集群中心標記和最新的5000個旅行的位置,如下可看出最受歡迎的位置,比如位于曼哈頓的0、3、9。
集群0最高搭乘次數出現在哪個小時?
- df.filter($"\_id" <= "1")
- .select(hour($"dt").alias("hour"), $"cid")
- .groupBy("hour","cid").agg(count("cid")
- .alias("count"))show
一天中的哪個小時和哪個集群的搭乘次數最多?
- %sql SELECT hour(uber.dt), cid, count(cid) FROM uber GROUP BY hour(uber.dt), cid
按日期時間顯示uber行程的集群計數
- %sql select cid, dt, count(cid) as count from uber group by dt, cid order by dt, cid limit 100
總結
本文涉及的知識點有Spark結構化流應用程序中的Spark Machine Learning模型、Spark結構化流與MapR-ES使用Kafka API攝取消息、SparkStructured Streaming持久化保存到MapR-DB,以持續快速地進行SQL分析等。此外,上述討論過的用例體系結構所有組件都可與MapR數據平臺在同一集群上運行。
代碼:
你可以從此處下載代碼和數據以運行這些示例:https://github.com/caroljmcdonald/mapr-spark-structuredstreaming-uber
機器學習notebook的Zeppelin查看器:https://www.zepl.com/viewer/github/caroljmcdonald/mapr-spark-structuredstreaming-uber/blob/master/notebooks/SparkUberML.json
Spark結構化流notebook的Zeppelin查看器:https://www.zepl.com/viewer/github/caroljmcdonald/mapr-spark-structuredstreaming-uber/blob/master/notebooks/SparkUberStructuredStreaming.json
SparkSQL notebook的Zenpelin查看器:https://www.zepl.com/viewer/github/caroljmcdonald/mapr-spark-structuredstreaming-uber/blob/master/notebooks/SparkUberSQLMapR-DB.json
此代碼包含在MapR 6.0.1沙箱上運行的說明,這是一個獨立的VM以及教程和演示應用程序,可讓用戶快速使用MapR和Spark。