好未來 x DorisDB:全新實時數倉實踐,深入釋放實時數據價值
好未來(NYSE:TAL)是一家以智慧教育和開放平臺為主體,以素質教育和課外輔導為載體,在全球范圍內服務公辦教育,助力民辦教育,探索未來教育新模式的科技教育公司。截至2020年11月底,好未來在102個城市建立起990個教學點,業務范圍覆蓋全國331個地級市以及海外20多個國家和地區。
隨著業務的發展,實時數據的分析需求日益增多,尤其在營銷推薦、歸因分析、業務輔助決策等場景下,實時數據分析所帶來的效益提升是離線數據所不能比擬的。在這些業務場景的驅動下,好未來選擇了DorisDB來支撐實時數據的分析應用。實現了數據秒級查詢響應能力,構建了一個統一&快速&高效&靈活的實時數倉。
“作者:王岳 好未來數據科學組負責人,專注于數倉建設、數據分析、算法等領域研究。”
一、業務背景
1.業務場景分類
在教育場景下,根據數據時效性劃分,數據分析處理可分為離線和實時兩大部分:
(1)離線
離線數據以8大數據域(日志、營銷、交易、服務、教學、內容、學習、畫像)建設為主,主要處理核心歷史數據,解決“業務運營、分析師、算法”等海量數據多維度分析和挖掘等,采用批處理的方式定時計算。
(2)實時
實時數據分析處理,主要包括由埋點產生的各種日志數據,數據量大,以結構化或半結構化類型為主;另外還包括由業務交易產生的業務數據,通常使用數據庫的Binlog獲取。
實時數據分析的需求越來越多,特別是在營銷簽單業務和在讀學員是否續報等場景,需要實時數據來助力業務營銷付費和續費目標達成。當目標沒完成時,業務運營需要對數據進行多維度分析,找到原因,并快速做出決策調整等管理動作。
2.業務痛點
T+1的離線數據分析已經無法滿足業務對時效性的需求,我們希望建設實時數倉來支持業務實時數據分析場景,解決如下痛點:
·市場:想通過廣告頁投放策略,洞悉PV、UV等流量數據,如果出現異常,可快速分析和優化。但之前因為各種因素我們無法提供實時數據,對于業務來說T+1數據時效性滯后,參考價值有限。
·銷售:通過分析意向用戶跟進和簽單數據,根據當日銷售目標,及時發現還有哪些管理動作需要優化。但目前是提供滯后數據,每日簽多少單都通過人來統計,分析也是通過歷史數據,分析效果很差。
·在讀學員續報:實時觀測哪些學員續報了,老師需要做哪些續報動作。
·課堂行為分析:分析課堂實時互動行為、答題行為等,階段評測報告、課堂質量等。
·算法模型:實時更新模型需要的特征數據,更準時的預測模型效果。
3.實時數倉目標
數據團隊要提供靈活&豐富的分鐘級的實時數據,并要保證數據的豐富性&準確性&及時性等。
(1)豐富性
沿用離線數倉建模好的數據維度和指標,保證離線能用到的,實時也能用到。
(2)準確性
實時指標的構建需要可以保證數據完整性和準確性。所有指標開發按照指標定義文檔,線上使用DQC平臺來監控數據準確性,實時發送異常數據等。
(3)及時性
要保證數據的“新鮮”度,線上實時產生的業務數據和日志數據,要能及時地被用于數據分析,提升一線人員或業務的反饋速度。
二、實時數倉技術架構演進
實時數倉的探索過程中,我們先后經歷了如下幾個階段:
·2018年~2019年,基于Hive框架下的小時級任務方案;
·2019年,基于Flink+Kudu的實時計算方案;
·2020年至今,基于DorisDB的實時數倉技術架構。
1.基于Hive
在原有天級延遲的離線數據處理任務基礎上,開發小時級延遲的數據處理鏈路,將核心數據按小時同步到Hive數倉中,每小時調度一次DAG任務,實現小時級任務計算。任務DAG示意圖如下所示:
(1)優點:
·離線和小時級任務各自獨立
·代碼邏輯復用性高,減少開發成本
·可以使用離線數據覆蓋小時級數據,進行數據修復
(2)缺點:
·小時級數據的延遲性還是很高,已無法滿足業務對數據時效性的要求
·MapReduce不適合分鐘級頻次的任務調度,主要是MapReduce任務啟動慢,另外會過高的頻次會產生很多小文件,影響HDFS的穩定性,以及SQL on Hadoop系統的查詢速度
·批量數據處理每次運行對資源要求高,尤其是當凌晨Hadoop資源緊張時,任務經常無法得到調度,延遲嚴重
2.基于Flink+Kudu
為了解決上面基于MapReduce小時級任務的問題,我們采用了流式處理系統Flink和支持增量更新的存儲系統Kudu。
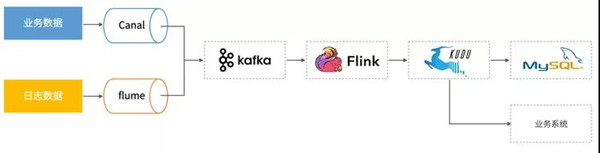
如上圖所示,實時的日志數據通過Flume采集到Kafka,實時的業務數據通過canal實時同步數據庫的binlog再轉發到Kafka中,Flink再實時消費Kafka中的數據寫入Kudu中。
在使用Flink+Kudu的實踐中,我們遇到了如下幾個問題:
·Flink基于stream語義,做復雜指標計算非常復雜,門檻高,開發效率不高,數據倉庫更多使用批處理SQL
·Kudu+Impala聚合查詢效率不高,查詢響應時間不能滿足業務多維分析要求
·使用Kudu需要依賴Impala、Hive等整個Hadoop組件,維護成本太高
·Kudu社區不活躍,遇到問題很難找到相關解決方案,使用過程中遇到過宕機等各類疑難問題
3.基于DorisDB
基于上面方案的問題,我們開始對實時數倉進行調研,包括DorisDB、ClickHouse、Kylin等系統,考慮到查詢性能、社區發展、運維成本等多種因素,我們最后選擇DorisDB作為我們的實時數倉,各系統的對比總結如下:
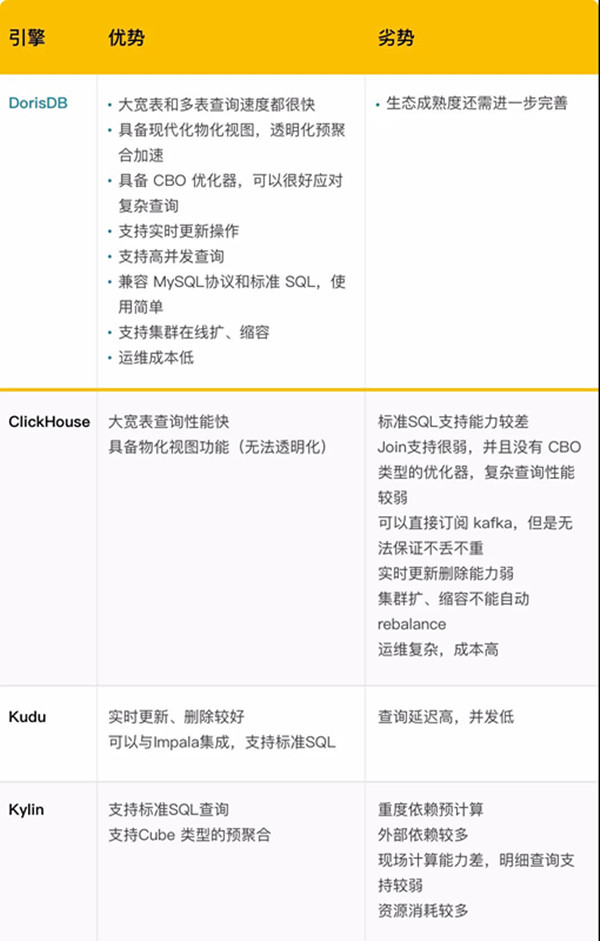
我們也深入考慮過ClickHouse,對于教育場景,一個學員要關聯的數據維度多,包括課堂、服務、訂單、教研等。在每個主題我們都會建設靈活且易用的星型數據模型。當業務想進行個性化自助分析時,僅需要關聯相關表即可。但如果直接構建明細大寬表,隨著業務不斷調整,經常需要重構開發。這種情況下,ClickHouse的join能力弱,無法滿足需求,而DorisDB強悍的Join能力,就成了我們應對業務變化的利器。而且DorisDB支持CBO(基于成本統計的優化器),具備復雜查詢的優化能力,從而可以快速的進行復雜實時微批處理任務,可以幫助我們更好的進行實時指標構建。
最終選擇DorisDB的原因:
·使用DorisDB可以讓我們像開發離線Hive任務一樣進行實時數倉的開發,避免了復雜的Flink stream語義,同時也能在功能上對齊離線指標,保證指標豐富性的基礎上完成指標定義口徑的一致,并且可以保證分鐘級的數據可見性。
·大寬表和星型模型的查詢性能都很好,可以靈活高效的滿足各類業務分析要求。
·DorisDB簡單易用,運維管理成本低。
三、基于DorisDB的實時數倉架構
1.系統搭建
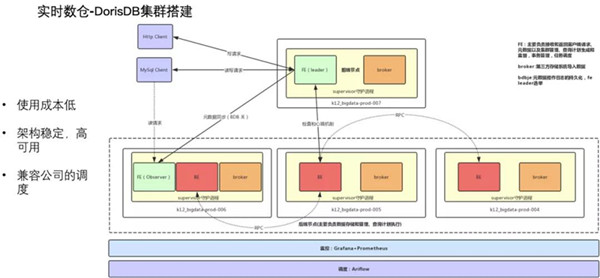
整個系統,除了DorisDB集群之外,我們還搭建了下面兩個配套系統
·調度:使用Airflow,進行DAG任務調度
·監控:使用grafana+prometheus,采集DorisDB信息并進行實時監控
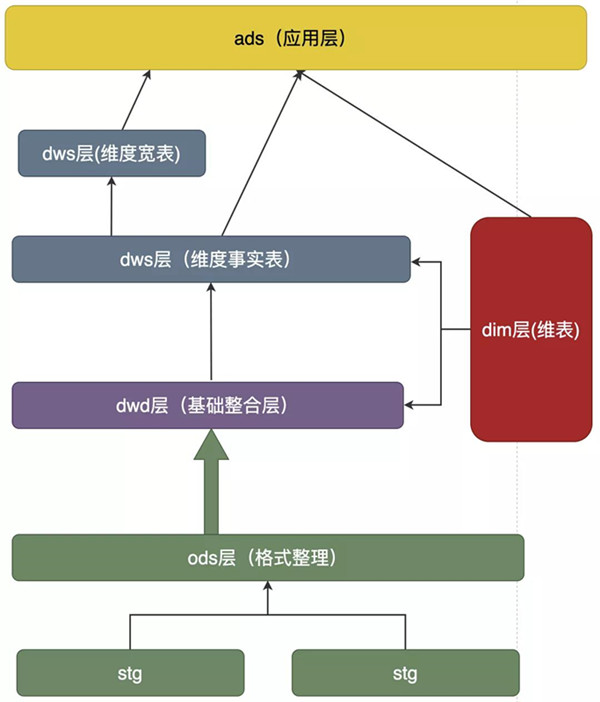
2.實時數倉總體架構
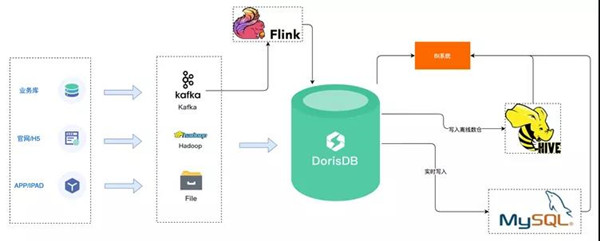
基于DorisDB的實時數倉總體架構,主要包括下面三個部分:
(1)數據源:業務數據(使用Flink實時同步mysql的binlog日志,寫入到Kafka)、日志數據(包括H5小程序、APP、直播ipad客戶端等埋點采集的各類日志數據,通過Flume寫入到Kafka中)
(2)數據存儲:
·采用DorisDB的Routine Load直接消費Kafka中的日志和業務數據
·使用DorisDB的Broker Load將Hadoop中的DWD、DWS、ADS等數據導入到DorisDB中
·對于Flink等流式處理下系統,使用DorisDB的Stream Load方式實時將數據導入DorisDB
(3)數據應用:
·使用DataX可以將DorisDB數據導出到MySQL中
·使用DorisDB的Export可以將DorisDB中的數據導出到HDFS中
·DorisDB完全兼容Mysql協議,BI或業務系統可以使用Mysql Connector直接連接DorisDB進行使用
3.實時數倉數據處理流程
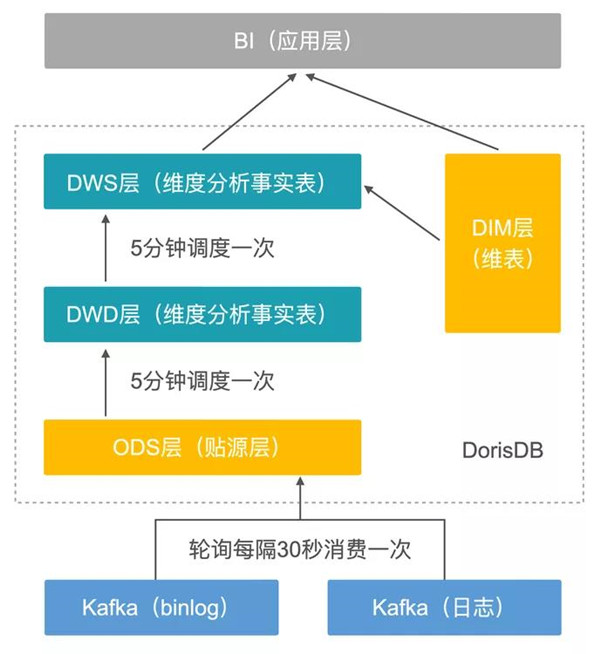
在實時數倉內部,也是按照傳統離線數倉的方式,對數據處理進行分層處理:
·ODS層,設置DorisDB的Routine Load間隔30秒消費一次Kafka數,寫入到ODS表中
·DWD層,按業務分析的需要建模DWD表,通過Airflow間隔5分鐘,將ODS表中過去5分鐘的增量數據寫入到DWD表中
·DWS層,對DWD表中的維度進行輕度或中度匯總,可以加快上層查詢速度
·BI層,通過自研的一個指標定義工具,分析人員可以快速的基于DWS構建報表,也可以衍生出一些復合指標進行二次加工。分析師也可以將取數口徑中的SQL做臨時修改,生成一個復雜跨主題查詢SQL,來應對一些Adhoc需求場景。
四、DorisDB實時數倉具體應用
在好未來,為保證課堂上課數據、訂單數據的實時分析要求,使用DorisDB支撐了課堂、訂單等分析業務。下面以課堂、訂單場景為例,從數據同步、數據加工等幾個步驟拆解DorisDB在好未來應用場景的落地方案。
1.實時數據同步
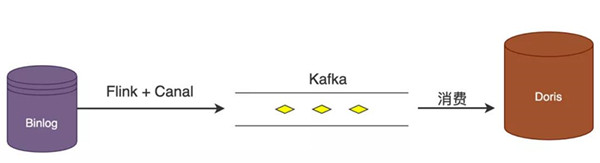
在好未來,采用flink采集業務庫的binlog數據,然后寫入到kafka中,DorisDB只需要消費kafka對應的topic數據即可,整體流程如下圖:
2.實時數倉數據處理
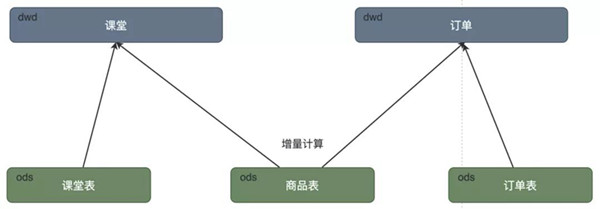
DorisDB內部的實時數據加工處理主要有如下操作:
·縮短計算鏈路的長度,實時部分最多計算2層。dwd或dws層
·增量計算,采用DorisDB的UNIQUE KEY模型,相當于(insert+update),因此只計算增量部分即可
·采用時間分區,多副本策略。既為了數據安全,又能避免鎖表
·離線表結構與實時表結構,保持一樣,這樣就可以用離線修復T+1數據
3.DAG任務調度
為了使DorisDB能在airflow上執行,我們封裝了airflow調用DorisDB執行sql的算子,以便DorisDB的加工邏輯在airflow上被定時調度。
DorisDB任務執行狀態的檢查,由于不像T+1,只需要判斷昨天任務是否執行就行了,實時檢查需要滿足以下條件:
·檢查輪詢間隔,需要根據不同的調度間隔,適當調整
·檢查輪詢總時長,不能超過(調度間隔時長-10秒)
·檢查的范圍,最小需要大于調度間隔,最大小于2倍的調度間隔
根據以上的實時調度檢查條件,我們封裝了基于DorisDB的實時調度的任務檢查airflow算子,方便使用。
4.實時數據生產預警
為了監控DorisDB的實時數據生產情況,我們設置了三種預警:
(1)檢查DorisDB消費Kafka的任務,是否停掉了,如果停掉自動重啟,重啟3次依然失敗,再發通知,人為干預
(2)檢查常規任務的執行,如果執行報錯,就發通知。
(3)檢查數據源與DorisDB實時數倉ods層表,schema的對比,如果出現schema變更,就發通知人為干預。這樣我們就能在白天實時了解schema的變更情況,不必要等到調度報錯才發現,而且不影響線上數據產出。
五、DorisDB使用效果
1.提升業務收益
DorisDB在眾多場景給業務帶來了直接收益,尤其是DorisDB的實時數據與算法模型相結合的場景。比如教育的獲客、轉化、用戶續報等業務,之前模型需要特征數據都是前一天的,所以模型也相對滯后。而我們通過大量數據分析得出結論:是當日行為和跟進數據,是最有價值的特征數據,這樣模型效果較好。特別是意向用戶識別模型,成為線索當天的歷史積累數據的特征和前一天的歷史積累數據的特征,分別訓練模型后,線上實際預測效果相差2-3個百分點,AUC 0.752和AUC 0.721的差別,所以,當天的特征模型效果特別明顯。
2.降低使用成本
·用簡單的SQL語義替代Stream語義完成實時數倉的開發,大大降低了開發的復雜度和時間成本,同時能夠保證和離線指標的一致性。
·結合使用寬表模型和星型模型,寬表和物化視圖可以保證報表性能和并發能力,星型模型可以保證系統的查詢靈活性,在一套系統中滿足不同場景的分析需求。另外,明細表查詢我們通過DorisDB外表的方式暴露查詢,提升了查詢的速度,大大降低了業務方的成本。DorisDB的分布式Join能力非常強,原來一些需要查詢多個Index在從內存中計算的邏輯可以直接下推到DorisDB中,降低了原有方案的復雜度,提升了查詢服務的穩定性,加快了響應時間。
·BI報表遷移成本低,我們前期BI可視化是基于Mysql構建的,某些看板不斷優化和豐富需求后,加上多維度靈活條件篩選,每次加載超級慢,業務無法接受,當同樣數據同步到DorisDB上后,我們僅需要修改數據源鏈接信息,SQL邏輯不用修改(這個超級爽,遷移成本超級低),查詢性能直接提升10倍以上。
·運維成本低,相對其他大數據組件來說,DorisDB只需要部署一種即可滿足各類數據分析需求,不需要其他軟件輔助,而且部署運維簡單。
未來展望
DorisDB作為新一代MPP數據庫的引領者,當前在多種場景下性能都非常優秀,幫助我們非常好的重構了實時數倉。目前DorisDB高效的支持了實時指標的計算,以及業務方在實時場景下的數據靈活探查和多維分析需求。DorisDB在集團內部各個業務線的應用越來越多,我們也將推動實時和離線數據分析進行統一,為業務分析提供更好的支撐。后繼我們將分享更多DorisDB的成功實踐。最后,感謝鼎石科技的大力支持!