Flink 在訊飛 AI 營銷業務的實時數據分析實踐
- 業務簡介
- 數倉演進
- 場景實踐
- 未來展望
01業務簡介

構建實時數據分析平臺是為了更好的解決業務對更高數據時效性的需求,先簡單介紹一下業務流程。
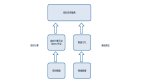
從日常的場景說起,當我們打開手機 APP 時,常會看到廣告。在這樣一個場景中,涉及到了兩個比較重要的角色。一是手機 APP,即流量方;另一個是投廣告的廣告主,如支付寶、京東會投放電商廣告。廣告主購買流量方的流量投廣告就產生了交易。
訊飛構建了一個流量交易平臺,流量交易平臺主要的職能是聚合下游流量,上游再對接廣告主,從而幫助廣告主和流量方在平臺上進行交易。訊飛還構建了投放平臺,這個平臺更側重于服務廣告主,幫助廣告主投放廣告,優化廣告效果。
在上述的業務流程圖中,APP 與平臺交互時會向平臺發起請求,然后平臺會下發廣告,用戶隨后才能看到廣告。用戶看到廣告的這個動作稱之為一次曝光,APP 會把這次曝光行為上報給平臺。如果用戶點擊了廣告,那么 APP 也會上報點擊行為。
廣告在產生之后發生了很多行為,可以將廣告的整個過程稱為廣告的一次生命周期,不僅限于圖中的請求、曝光、點擊這三次行為,后面可能還有下單、購買等。

在這樣一個業務流程中,業務的核心訴求是什么呢?在廣告的生命周期中有請求、曝光和點擊等各種行為,這些行為會產生對應的業務日志。那么就需要從日志生成數據供業務側分析,從日志到分析的過程中就引入了數倉構建、數倉分層,數據呈現的時效性就帶來了實時數據倉庫的發展。
02數倉演進

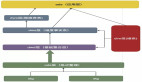
上圖是一個典型的數倉分層框架,最底層是 ODS 數據,包括業務日志流、OLTP 數據庫、第三方文檔數據。經過 ETL 將 ODS 層的數據清洗成業務模型,也就是 DWD 層。

最初是建立了 Spark 數倉,將業務日志收集到 Kafka 中再投遞到 HDFS 上,通過 Spark 對日志進行清洗建模,然后將業務模型再回寫到 HDFS 上,再使用 Spark 對模型進行統計、分析、輸出報表數據。后續,訊飛沿用了 Spark 技術棧引入了 spark-streaming。

隨后逐漸將 spark-streaming 遷移到了 Flink 上,主要是因為 Flink 更高的時效性和對事件時間的支持。
當初 spark-streaming 的實踐是微批的,一般設置 10 秒或是 30 秒一批,數據的時效性頂多是秒級的。而 Flink 可以支持事件驅動的開發模式,理論上時效性可以達到毫秒級。
當初基于 spark-streaming 的實時數據流邏輯較為簡陋,沒有形成一個數倉分層的結構。而 Flink 可以基于 watermark 支持事件時間,并且支持對延遲數據的處理,對于構建一個業務邏輯完備的數倉有很大的幫助。

由上圖可見,ODS 的業務日志收集到 Kafka 中,Flink 從 Kafka 中消費業務日志,清洗處理后將業務模型再回寫到 Kafka 中。然后再基于 Flink 去消費 Kafka 中的模型,提取維度和指標,統計后輸出報表。有些報表會直接寫到 sql 或 HBase 中,還有一些報表會回寫到 Kafka 中,再由 Druid 從 Kafka 中主動攝取這部分報表數據。
在整個數據流圖中 Flink 是核心的計算引擎,負責清洗日志、統計報表。
03場景實踐
3.1 ODS - 日志消費負載均衡

ODS 業務中,請求日志量級大,其他日志量級小。這樣請求日志(request_topic)在 Kafka 上分區多,曝光和點擊日志(impress/click_topic)分區少。

最初是采用單 source 的方法,創建一個 FlinkKafkaConsumer011 消費所有分區,這可能導致 task 消費負載不均。同一 topic 的不同分區在 task 上可均勻分配,但不同 topic 的分區可能會被同一 task 消費。期望能達到的消費狀態是:量級大的 topic,其 task 和 partition 一一對應,量級小的 topic 占用剩下的 task。

解決方法是把單 source 的消費方式改成了多 source union 的方式,也就是創建了兩個 consumer,一個 consumer 用來消費大的 topic,一個 consumer 用來消費小的 topic,并單獨為它們設置并行。
3.2 DWD - 日志關聯及狀態緩存

DWD 是業務模型層,需要實現的一個關鍵邏輯是日志關聯。基于 sid 關聯廣告一次生命周期中的不同行為日志。業務模型記錄了 sid 級別的維度和指標。

最初是基于 30s 的 window 來做關聯,但這種方式會導致模型輸出較第一次事件發生延遲有 30s,并且 30s 僅能覆蓋不到 12% 的曝光日志。如果擴大窗口時間則會導致輸出延遲更多,并且同一時刻存在的窗口隨時間增長,資源消耗也比較大。

后續改成了基于狀態緩存的方式來實現日志關聯,即 ValueState。同一 sid 下的日志能夠訪問到相應的 ValueState。不過為保證及時輸出,將請求、曝光、點擊等不同指標,拆分到了多條數據中,輸出的數據存在冗余。

隨著業務的增長和變化,需要緩存的狀態日益變大,內存已無法滿足。于是我們將狀態從內存遷移至 HBase 中,這樣做的好處是支持了更大的緩存,并且 Flink checkpoint 負載降低。但同時也帶來了兩個問題:引入第三方服務,需要額外維護 HBase;HBase 的穩定性也成為計算鏈路穩定性的重要依賴。

在 HBase 狀態緩存中,遇到一個數據傾斜的問題,某條測試 sid 的曝光重復上報,每小時千次量級。如上圖,該條 sid 對應的狀態達到 MB 級別,被頻繁的從 HBase 中取出并寫回,引起頻繁的 gc,影響所在 task 的性能。解決辦法是根據業務邏輯對 impress 進行去重。
3.3 DWS - 實時 OLAP

在 DWD 層基于 Flink 的事件驅動已經實現了實時模型,再由 Flink 來消費處理實時模型,從中提取出維度和指標,然后逐條的向后輸出。在這個過程中已是能輸出一個實時 OLAP 的結果了,但也需要有個后端的存儲來承接,我們因此引入了 Druid。Druid 可以支持數據的實時攝入,并且攝入的結果實時可查,也可以在攝入的同時做自動的聚合。

上圖左側:每張表需要啟動常駐任務等待 push 過來的數據。常駐任務被動接收數據,易被壓崩;常駐任務異常重啟麻煩,需要清理 zk 狀態;常駐任務的高可用依賴備份任務,浪費資源。
上圖右側:一張報表對應一個 Kafka 消費任務。消費任務自己控制攝入速率更加穩定;任務可依賴 offset 平滑的失敗自啟。
3.4 ADS - 跨源查詢

Presto 是分布式的 SQL 查詢引擎,可從不同的數據源抽取數據并關聯查詢。但會帶來 Druid 的下推優化支持不完善的問題。
3.5 流批混合現狀

如上圖所示是 Lambda 大數據框架,流式計算部分是 Kafka+Flink,批處理則是 HDFS+Spark。
流式計算的特點:
- 響應快,秒級輸出;
- 可重入性差,難以重復計算歷史日志;
- 流的持續性重要,異常需迅速介入。
批處理的特點:
- 響應慢,小時級輸出;
- 可重入性好,可重復計算歷史數據;
- 數據按小時粒度管理,個別異常可從容處理。
流批混合痛點:
- 兩遍日志清洗的計算量;
- 兩套技術框架;
- 數據一致性問題。
04未來展望

流批混合優化,直接將實時模型輸出到 HDFS。
好處是:
- 避免了對日志的重復清洗;
- 統一了建模的技術框架;
- 支持延遲數據對模型的更新。
但也有以下兩個問題:
- 實時模型重復,量級更大,計算消耗大;
- 支持數據更新的技術如 Hudi,會改變模型的使用方式,對后續使用者不友好。

最后聊一下對 Flink-SQL 的想法:檢索近 10 分鐘的某條異常日志、快速評估近 10 分鐘新策略的效果都屬于即時、微批、即席查詢。批處理鏈路小時級響應太慢;實時檢索系統如 ES,資源消耗大。可以利用 Kafka + Flink-SQL 解決上述問題,Kafka + Flink-SQL 也是今后計劃嘗試的方向。?