













科普 | 你應(yīng)該知道的Java緩存進(jìn)化史
背景
本文是上周去技術(shù)沙龍聽(tīng)了一下愛(ài)奇藝的 Java 緩存之路有感寫(xiě)出來(lái)的。先簡(jiǎn)單介紹一下愛(ài)奇藝的 Java 緩存道路的發(fā)展吧。
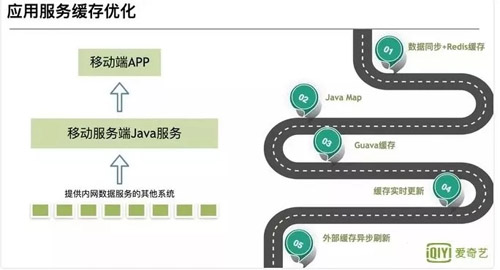
可以看見(jiàn)圖中分為幾個(gè)階段:
- 第一階段:數(shù)據(jù)同步加 Redis
通過(guò)消息隊(duì)列進(jìn)行數(shù)據(jù)同步至 Redis,然后 Java 應(yīng)用直接去取緩存。這個(gè)階段的優(yōu)點(diǎn)是:由于是使用的分布式緩存,所以數(shù)據(jù)更新快。缺點(diǎn)也比較明顯:依賴 Redis 的穩(wěn)定性,一旦 Redis 掛了,整個(gè)緩存系統(tǒng)不可用,造成緩存雪崩,所有請(qǐng)求打到 DB。
- 第二,三階段:JavaMap 到 Guava Cache
這個(gè)階段使用進(jìn)程內(nèi)緩存作為一級(jí)緩存,Redis 作為二級(jí)。優(yōu)點(diǎn):不受外部系統(tǒng)影響,其他系統(tǒng)掛了,依然能使用。缺點(diǎn):進(jìn)程內(nèi)緩存無(wú)法像分布式緩存那樣做到實(shí)時(shí)更新。由于 Java 內(nèi)存有限,必定緩存得設(shè)置大小,然后有些緩存會(huì)被淘汰,就會(huì)有命中率的問(wèn)題。
- 第四階段: Guava Cache 刷新
為了解決上面的問(wèn)題,利用 Guava Cache 可以設(shè)置寫(xiě)后刷新時(shí)間,進(jìn)行刷新。解決了一直不更新的問(wèn)題,但是依然沒(méi)有解決實(shí)時(shí)刷新。
- 第五階段:外部緩存異步刷新
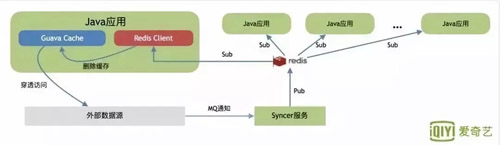
這個(gè)階段擴(kuò)展了 Guava Cache,利用 Redis 作為消息隊(duì)列通知機(jī)制,通知其他 Java 應(yīng)用程序進(jìn)行刷新。
這里簡(jiǎn)單介紹一下愛(ài)奇藝緩存發(fā)展的五個(gè)階段,當(dāng)然還有一些其他的優(yōu)化,比如 GC 調(diào)優(yōu),緩存穿透,緩存覆蓋的一些優(yōu)化等等。
原始社會(huì) - 查庫(kù)
上面說(shuō)的是愛(ài)奇藝的一個(gè)進(jìn)化線路,但是在大家的一般開(kāi)發(fā)過(guò)程中,第一步一般都沒(méi)有 Redis,而是直接查庫(kù)。
在流量不大的時(shí)候,查數(shù)據(jù)庫(kù)或者讀取文件最為方便,也能完全滿足我們的業(yè)務(wù)要求。
古代社會(huì) - HashMap
當(dāng)我們應(yīng)用有一定流量之后或者查詢數(shù)據(jù)庫(kù)特別頻繁,這個(gè)時(shí)候就可以祭出我們 Java 中自帶的 HashMap 或者 ConcurrentHashMap。我們可以在代碼中這么寫(xiě):
- public class CustomerService {
- private HashMap<String,String> hashMap = new HashMap<>();
- private CustomerMapper customerMapper;
- public String getCustomer(String name){
- String customer = hashMap.get(name);
- if ( customer == null){
- customer = customerMapper.get(name);
- hashMap.put(name,customer);
- }
- return customer;
- }
- }
但是這樣做就有個(gè)問(wèn)題 HashMap 無(wú)法進(jìn)行數(shù)據(jù)淘汰,內(nèi)存會(huì)無(wú)限制的增長(zhǎng),所以 HashMap 很快也被淘汰了。
當(dāng)然并不是說(shuō)它完全就沒(méi)用,就像我們古代社會(huì)也不是所有的東西都是過(guò)時(shí)的,比如我們中華名族的傳統(tǒng)美德是永不過(guò)時(shí)的,就像這個(gè) HashMap 一樣的可以在某些場(chǎng)景下作為緩存,當(dāng)不需要淘汰機(jī)制的時(shí)候,比如我們利用反射,如果我們每次都通過(guò)反射去搜索 Method,field,性能必定低效,這時(shí)我們用 HashMap 將其緩存起來(lái),性能能提升很多。
近代社會(huì) - LRUHashMap
在古代社會(huì)中難住我們的問(wèn)題是無(wú)法進(jìn)行數(shù)據(jù)淘汰,這樣會(huì)導(dǎo)致我們內(nèi)存無(wú)限膨脹,顯然我們是不可以接受的。
有人就說(shuō)我把一些數(shù)據(jù)給淘汰掉唄,這樣不就對(duì)了,但是怎么淘汰呢?隨機(jī)淘汰嗎?當(dāng)然不行,試想一下你剛把 A 裝載進(jìn)緩存,下一次要訪問(wèn)的時(shí)候就被淘汰了,那又會(huì)訪問(wèn)我們的數(shù)據(jù)庫(kù)了,那我們要緩存干嘛呢?
所以聰明的人們就發(fā)明了幾種淘汰算法,下面列舉下常見(jiàn)的三種 FIFO,LRU,LFU(還有一些 ARC,MRU 感興趣的可以自行搜索):
- FIFO:先進(jìn)先出,在這種淘汰算法中,先進(jìn)入緩存的會(huì)先被淘汰。
這種可謂是最簡(jiǎn)單的了,但是會(huì)導(dǎo)致我們命中率很低。試想一下我們?nèi)绻袀€(gè)訪問(wèn)頻率很高的數(shù)據(jù)是所有數(shù)據(jù)第一個(gè)訪問(wèn)的,而那些不是很高的是后面再訪問(wèn)的,那這樣就會(huì)把我們的首個(gè)數(shù)據(jù)但是他的訪問(wèn)頻率很高給擠出。
- LRU:最近最少使用算法。
在這種算法中避免了上面的問(wèn)題,每次訪問(wèn)數(shù)據(jù)都會(huì)將其放在我們的隊(duì)尾,如果需要淘汰數(shù)據(jù),就只需要淘汰隊(duì)首即可。
但是這個(gè)依然有個(gè)問(wèn)題,如果有個(gè)數(shù)據(jù)在 1 個(gè)小時(shí)的前 59 分鐘訪問(wèn)了 1 萬(wàn)次(可見(jiàn)這是個(gè)熱點(diǎn)數(shù)據(jù)),再后 1 分鐘沒(méi)有訪問(wèn)這個(gè)數(shù)據(jù),但是有其他的數(shù)據(jù)訪問(wèn),就導(dǎo)致了我們這個(gè)熱點(diǎn)數(shù)據(jù)被淘汰。
- LFU:最近最少頻率使用。
在這種算法中又對(duì)上面進(jìn)行了優(yōu)化,利用額外的空間記錄每個(gè)數(shù)據(jù)的使用頻率,然后選出頻率最低進(jìn)行淘汰。這樣就避免了 LRU 不能處理時(shí)間段的問(wèn)題。
上面列舉了三種淘汰策略,對(duì)于這三種,實(shí)現(xiàn)成本是一個(gè)比一個(gè)高,同樣的命中率也是一個(gè)比一個(gè)好。
而我們一般來(lái)說(shuō)選擇的方案居中即可,即實(shí)現(xiàn)成本不是太高,而命中率也還行的 LRU,如何實(shí)現(xiàn)一個(gè) LRUMap 呢?我們可以通過(guò)繼承 LinkedHashMap,重寫(xiě) removeEldestEntry 方法,即可完成一個(gè)簡(jiǎn)單的 LRUMap。
- class LRUMap extends LinkedHashMap {
- private final int max;
- private Object lock;
- public LRUMap(int max, Object lock) {
- //無(wú)需擴(kuò)容
- super((int) (max * 1.4f), 0.75f, true);
- this.max = max;
- this.lock = lock;
- }
- /**
- * 重寫(xiě)LinkedHashMap的removeEldestEntry方法即可
- * 在Put的時(shí)候判斷,如果為true,就會(huì)刪除最老的
- * @param eldest
- * @return
- */
- @Override
- protected boolean removeEldestEntry(Map.Entry eldest) {
- return size() > max;
- }
- public Object getValue(Object key) {
- synchronized (lock) {
- return get(key);
- }
- }
- public void putValue(Object key, Object value) {
- synchronized (lock) {
- put(key, value);
- }
- }
- public boolean removeValue(Object key) {
- synchronized (lock) {
- return remove(key) != null;
- }
- }
- public boolean removeAll(){
- clear();
- return true;
- }
- }
在 LinkedHashMap 中維護(hù)了一個(gè) entry(用來(lái)放 key 和 value 的對(duì)象)鏈表。在每一次 get 或者 put 的時(shí)候都會(huì)把插入的新 entry,或查詢到的老 entry 放在我們鏈表末尾。
可以注意到我們?cè)跇?gòu)造方法中,設(shè)置的大小特意設(shè)置到 max*1.4,在下面的 removeEldestEntry 方法中只需要 size>max 就淘汰,這樣我們這個(gè) map 永遠(yuǎn)也走不到擴(kuò)容的邏輯了,通過(guò)重寫(xiě) LinkedHashMap,幾個(gè)簡(jiǎn)單的方法我們實(shí)現(xiàn)了我們的 LruMap。
現(xiàn)代社會(huì) - Guava Cache
在近代社會(huì)中已經(jīng)發(fā)明出來(lái)了 LRUMap,用來(lái)進(jìn)行緩存數(shù)據(jù)的淘汰,但是有幾個(gè)問(wèn)題:
- 鎖競(jìng)爭(zhēng)嚴(yán)重,可以看見(jiàn)我的代碼中,Lock 是全局鎖,在方法級(jí)別上面的,當(dāng)調(diào)用量較大時(shí),性能必然會(huì)比較低。
- 不支持過(guò)期時(shí)間
- 不支持自動(dòng)刷新
所以谷歌的大佬們對(duì)于這些問(wèn)題,按捺不住了,發(fā)明了 Guava Cache,在 Guava Cache 中你可以如下面的代碼一樣,輕松使用:
- public static void main(String[] args) throws ExecutionException {
- LoadingCache<String, String> cache = CacheBuilder.newBuilder()
- .maximumSize(100)
- //寫(xiě)之后30ms過(guò)期
- .expireAfterWrite(30L, TimeUnit.MILLISECONDS)
- //訪問(wèn)之后30ms過(guò)期
- .expireAfterAccess(30L, TimeUnit.MILLISECONDS)
- //20ms之后刷新
- .refreshAfterWrite(20L, TimeUnit.MILLISECONDS)
- //開(kāi)啟weakKey key 當(dāng)啟動(dòng)垃圾回收時(shí),該緩存也被回收
- .weakKeys()
- .build(createCacheLoader());
- System.out.println(cache.get("hello"));
- cache.put("hello1", "我是hello1");
- System.out.println(cache.get("hello1"));
- cache.put("hello1", "我是hello2");
- System.out.println(cache.get("hello1"));
- }
- public static com.google.common.cache.CacheLoader<String, String> createCacheLoader() {
- return new com.google.common.cache.CacheLoader<String, String>() {
- @Override
- public String load(String key) throws Exception {
- return key;
- }
- };
- }
我將會(huì)從 Guava Cache 原理中,解釋 Guava Cache 是如何解決 LRUMap 的幾個(gè)問(wèn)題的。
鎖競(jìng)爭(zhēng)
Guava Cache 采用了類似 ConcurrentHashMap 的思想,分段加鎖,在每個(gè)段里面各自負(fù)責(zé)自己的淘汰的事情。
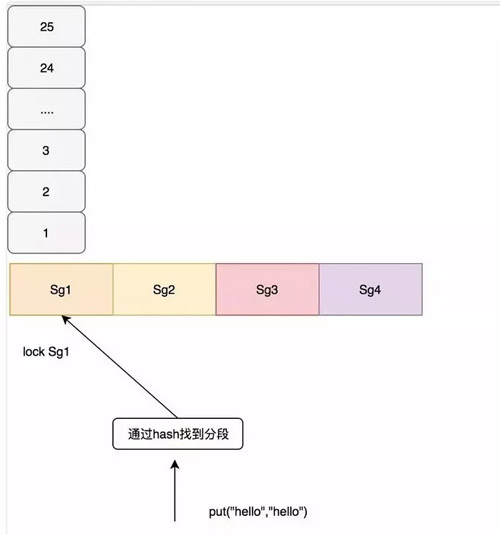
在 Guava 根據(jù)一定的算法進(jìn)行分段,這里要說(shuō)明的是,如果段太少那競(jìng)爭(zhēng)依然很嚴(yán)重,如果段太多容易出現(xiàn)隨機(jī)淘汰,比如大小為 100 的,給他分 100 個(gè)段,那也就是讓每個(gè)數(shù)據(jù)都獨(dú)占一個(gè)段,而每個(gè)段會(huì)自己處理淘汰的過(guò)程,所以會(huì)出現(xiàn)隨機(jī)淘汰。在 Guava Cache 中通過(guò)如下代碼,計(jì)算出應(yīng)該如何分段。
- int segmentShift = 0;
- int segmentCount = 1;
- while (segmentCount < concurrencyLevel && (!evictsBySize() || segmentCount * 20 <= maxWeight)) {
- ++segmentShift;
- segmentCount <<= 1;
- }
上面 segmentCount 就是我們最后的分段數(shù),其保證了每個(gè)段至少 10 個(gè) entry。如果沒(méi)有設(shè)置 concurrencyLevel 這個(gè)參數(shù),那么默認(rèn)就會(huì)是 4,最后分段數(shù)也最多為 4,例如我們 size 為 100,會(huì)分為 4 段,每段最大的 size 是 25。
在 Guava Cache 中對(duì)于寫(xiě)操作直接加鎖,對(duì)于讀操作,如果讀取的數(shù)據(jù)沒(méi)有過(guò)期,且已經(jīng)加載就緒,不需要進(jìn)行加鎖,如果沒(méi)有讀到會(huì)再次加鎖進(jìn)行二次讀,如果還沒(méi)有需要進(jìn)行緩存加載,也就是通過(guò)我們配置的 CacheLoader,我這里配置的是直接返回 Key,在業(yè)務(wù)中通常配置從數(shù)據(jù)庫(kù)中查詢。 如下圖所示:
過(guò)期時(shí)間
相比于 LRUMap 多了兩種過(guò)期時(shí)間,一個(gè)是寫(xiě)后多久過(guò)期 expireAfterWrite,一個(gè)是讀后多久過(guò)期 expireAfterAccess。
很有意思的事情是,在 Guava Cache 中對(duì)于過(guò)期的 entry 并沒(méi)有馬上過(guò)期(也就是并沒(méi)有后臺(tái)線程一直在掃),而是通過(guò)進(jìn)行讀寫(xiě)操作的時(shí)候進(jìn)行過(guò)期處理,這樣做的好處是避免后臺(tái)線程掃描的時(shí)候進(jìn)行全局加鎖。看下面的代碼:
- public static void main(String[] args) throws ExecutionException, InterruptedException {
- Cache<String, String> cache = CacheBuilder.newBuilder()
- .maximumSize(100)
- //寫(xiě)之后5s過(guò)期
- .expireAfterWrite(5, TimeUnit.MILLISECONDS)
- .concurrencyLevel(1)
- .build();
- cache.put("hello1", "我是hello1");
- cache.put("hello2", "我是hello2");
- cache.put("hello3", "我是hello3");
- cache.put("hello4", "我是hello4");
- //至少睡眠5ms
- Thread.sleep(5);
- System.out.println(cache.size());
- cache.put("hello5", "我是hello5");
- System.out.println(cache.size());
- }
- 輸出:
- 4
- 1
從這個(gè)結(jié)果中我們知道,在 put 的時(shí)候才進(jìn)行的過(guò)期處理。特別注意的是我上面 concurrencyLevel(1)這里將分段最大設(shè)置為 1,不然不會(huì)出現(xiàn)這個(gè)實(shí)驗(yàn)效果的,在上面一節(jié)中已經(jīng)說(shuō)過(guò),我們是以段位單位進(jìn)行過(guò)期處理。在每個(gè) Segment 中維護(hù)了兩個(gè)隊(duì)列:
- final Queue<ReferenceEntry<K, V>> writeQueue;
- final Queue<ReferenceEntry<K, V>> accessQueue;
writeQueue 維護(hù)了寫(xiě)隊(duì)列,隊(duì)頭代表著寫(xiě)得早的數(shù)據(jù),隊(duì)尾代表寫(xiě)得晚的數(shù)據(jù)。accessQueue 維護(hù)了訪問(wèn)隊(duì)列,和 LRU 一樣,用來(lái)進(jìn)行訪問(wèn)時(shí)間的淘汰。如果當(dāng)這個(gè) Segment 超過(guò)最大容量,比如我們上面所說(shuō)的 25,超過(guò)之后,就會(huì)把 accessQueue 這個(gè)隊(duì)列的第一個(gè)元素進(jìn)行淘汰。
- void expireEntries(long now) {
- drainRecencyQueue();
- ReferenceEntry<K, V> e;
- while ((e = writeQueue.peek()) != null && map.isExpired(e, now)) {
- if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {
- throw new AssertionError();
- }
- }
- while ((e = accessQueue.peek()) != null && map.isExpired(e, now)) {
- if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {
- throw new AssertionError();
- }
- }
- }
上面就是 Guava Cache 處理過(guò)期 entries 的過(guò)程,會(huì)對(duì)兩個(gè)隊(duì)列一次進(jìn)行 peek 操作,如果過(guò)期就進(jìn)行刪除。
一般處理過(guò)期 entries 可以在我們的 put 操作的前后,或者讀取數(shù)據(jù)時(shí)發(fā)現(xiàn)過(guò)期了,然后進(jìn)行整個(gè) segment 的過(guò)期處理,又或者進(jìn)行二次讀 lockedGetOrLoad 操作的時(shí)候調(diào)用。
- void evictEntries(ReferenceEntry<K, V> newest) {
- ///... 省略無(wú)用代碼
- while (totalWeight > maxSegmentWeight) {
- ReferenceEntry<K, V> e = getNextEvictable();
- if (!removeEntry(e, e.getHash(), RemovalCause.SIZE)) {
- throw new AssertionError();
- }
- }
- }
- /**
- **返回accessQueue的entry
- **/
- ReferenceEntry<K, V> getNextEvictable() {
- for (ReferenceEntry<K, V> e : accessQueue) {
- int weight = e.getValueReference().getWeight();
- if (weight > 0) {
- return e;
- }
- }
- throw new AssertionError();
- }
上面是我們驅(qū)逐 entry 的時(shí)候的代碼,可以看見(jiàn)訪問(wèn)的是 accessQueue 對(duì)其隊(duì)頭進(jìn)行驅(qū)逐。而驅(qū)逐策略一般是在對(duì) segment 中的元素發(fā)生變化時(shí)進(jìn)行調(diào)用,比如插入操作,更新操作,加載數(shù)據(jù)操作。
自動(dòng)刷新
自動(dòng)刷新操作,在 Guava Cache 中實(shí)現(xiàn)相對(duì)比較簡(jiǎn)單,直接通過(guò)查詢,判斷其是否滿足刷新條件,進(jìn)行刷新。
其他特性
在 Guava Cache 中還有一些其他特性:
虛引用
在 Guava Cache 中,key 和 value 都能進(jìn)行虛引用的設(shè)定,在 segment 中有兩個(gè)引用隊(duì)列:
- final @Nullable ReferenceQueue<K> keyReferenceQueue;
- final @Nullable ReferenceQueue<V> valueReferenceQueue;
這兩個(gè)隊(duì)列用來(lái)記錄被回收的引用,其中每個(gè)隊(duì)列記錄了每個(gè)被回收的 entry 的 hash,這樣回收了之后通過(guò)這個(gè)隊(duì)列中的 hash 值就能把以前的 entry 進(jìn)行刪除。
刪除監(jiān)聽(tīng)器
在 Guava Cache 中,當(dāng)有數(shù)據(jù)被淘汰時(shí),但是你不知道他到底是過(guò)期,還是被驅(qū)逐,還是因?yàn)樘撘玫膶?duì)象被回收?
這個(gè)時(shí)候你可以調(diào)用這個(gè)方法 removalListener(RemovalListener listener)添加監(jiān)聽(tīng)器進(jìn)行數(shù)據(jù)淘汰的監(jiān)聽(tīng),可以打日志或者一些其他處理,可以用來(lái)進(jìn)行數(shù)據(jù)淘汰分析。
在 RemovalCause 記錄了所有被淘汰的原因:被用戶刪除,被用戶替代,過(guò)期,驅(qū)逐收集,由于大小淘汰。
Guava Cache 的總結(jié)
細(xì)細(xì)品讀 Guava Cache 的源碼總結(jié)下來(lái),其實(shí)就是一個(gè)性能不錯(cuò)的,api 豐富的 LRU Map。愛(ài)奇藝的緩存的發(fā)展也是基于此之上,通過(guò)對(duì) Guava Cache 的二次開(kāi)發(fā),讓其可以進(jìn)行 Java 應(yīng)用服務(wù)之間的緩存更新。
走向未來(lái)-caffeine
Guava Cache 的功能的確是很強(qiáng)大,滿足了絕大多數(shù)人的需求,但是其本質(zhì)上還是 LRU 的一層封裝,所以在眾多其他較為優(yōu)良的淘汰算法中就相形見(jiàn)絀了。而 Caffeine Cache 實(shí)現(xiàn)了 W-TinyLFU(LFU+LRU 算法的變種)。下面是不同算法的命中率的比較:
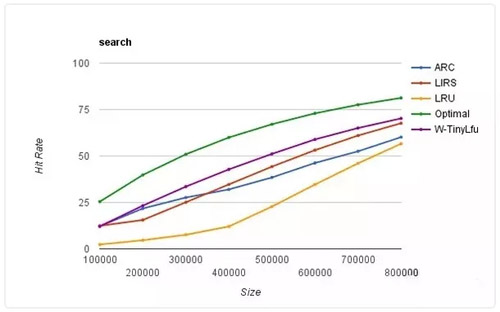
其中 Optimal 是最理想的命中率,LRU 和其他算法相比的確是個(gè)弟弟。而我們的 W-TinyLFU 是最接近理想命中率的。當(dāng)然不僅僅是命中率 Caffeine 優(yōu)于了 Guava Cache,在讀寫(xiě)吞吐量上面也是完爆 Guava Cache。
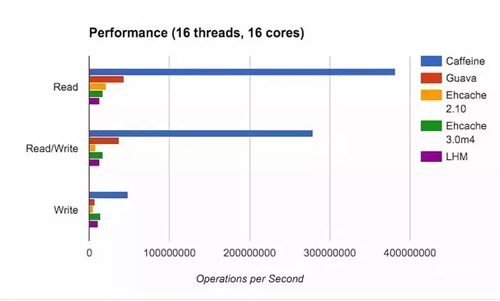
這個(gè)時(shí)候你肯定會(huì)好奇為啥 Caffeine 這么牛逼呢?別著急下面慢慢給你道來(lái)。
W-TinyLFU
上面已經(jīng)說(shuō)過(guò)了傳統(tǒng)的 LFU 是怎么一回事。在 LFU 中只要數(shù)據(jù)訪問(wèn)模式的概率分布隨時(shí)間保持不變時(shí),其命中率就能變得非常高。
這里我還是拿愛(ài)奇藝舉例,比如有部新劇出來(lái)了,我們使用 LFU 給他緩存下來(lái),這部新劇在這幾天大概訪問(wèn)了幾億次,這個(gè)訪問(wèn)頻率也在我們的 LFU 中記錄了幾億次。
但是新劇總會(huì)過(guò)氣的,比如一個(gè)月之后這個(gè)新劇的前幾集其實(shí)已經(jīng)過(guò)氣了,但是他的訪問(wèn)量的確是太高了,其他的電視劇根本無(wú)法淘汰這個(gè)新劇,所以在這種模式下是有局限性。
所以各種 LFU 的變種出現(xiàn)了,基于時(shí)間周期進(jìn)行衰減,或者在最近某個(gè)時(shí)間段內(nèi)的頻率。同樣的 LFU 也會(huì)使用額外空間記錄每一個(gè)數(shù)據(jù)訪問(wèn)的頻率,即使數(shù)據(jù)沒(méi)有在緩存中也需要記錄,所以需要維護(hù)的額外空間很大。
可以試想我們對(duì)這個(gè)維護(hù)空間建立一個(gè) HashMap,每個(gè)數(shù)據(jù)項(xiàng)都會(huì)存在這個(gè) HashMap 中,當(dāng)數(shù)據(jù)量特別大的時(shí)候,這個(gè) HashMap 也會(huì)特別大。
再回到 LRU,我們的 LRU 也不是那么一無(wú)是處,LRU 可以很好的應(yīng)對(duì)突發(fā)流量的情況,因?yàn)樗恍枰塾?jì)數(shù)據(jù)頻率。
所以 W-TinyLFU 結(jié)合了 LRU 和 LFU,以及其他的算法的一些特點(diǎn)。
頻率記錄
首先要說(shuō)到的就是頻率記錄的問(wèn)題,我們要實(shí)現(xiàn)的目標(biāo)是利用有限的空間可以記錄隨時(shí)間變化的訪問(wèn)頻率。在 W-TinyLFU 中使用 Count-Min Sketch 記錄我們的訪問(wèn)頻率,而這個(gè)也是布隆過(guò)濾器的一種變種。如下圖所示::
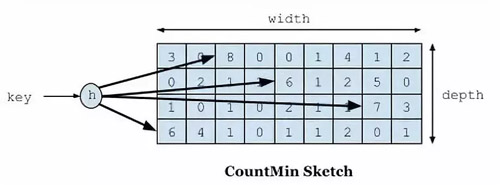
如果需要記錄一個(gè)值,那我們需要通過(guò)多種 hash 算法對(duì)其進(jìn)行處理hash,然后在對(duì)應(yīng)的 hash 算法的記錄中+1,為什么需要多種 hash 算法呢?
由于這是一個(gè)壓縮算法必定會(huì)出現(xiàn)沖突,比如我們建立一個(gè) Long 的數(shù)組,通過(guò)計(jì)算出每個(gè)數(shù)據(jù)的 hash 的位置。比如張三和李四,他們倆有可能 hash 值都是相同,比如都是 1 那 Long[1] 這個(gè)位置就會(huì)增加相應(yīng)的頻率,張三訪問(wèn) 1 萬(wàn)次,李四訪問(wèn) 1 次那 Long[1] 這個(gè)位置就是 1 萬(wàn)零 1。
如果取李四的訪問(wèn)評(píng)率的時(shí)候就會(huì)取出是 1 萬(wàn)零 1,但是李四命名只訪問(wèn)了 1 次啊,為了解決這個(gè)問(wèn)題,所以用了多個(gè) hash 算法可以理解為 Long[][] 二維數(shù)組的一個(gè)概念,比如在第一個(gè)算法張三和李四沖突了,但是在第二個(gè),第三個(gè)中很大的概率不沖突,比如一個(gè)算法大概有 1% 的概率沖突,那四個(gè)算法一起沖突的概率是 1% 的四次方。
通過(guò)這個(gè)模式,我們?nèi)±钏牡脑L問(wèn)率的時(shí)候取所有算法中,李四訪問(wèn)最低頻率的次數(shù)。所以他的名字叫 Count-Min Sketch。
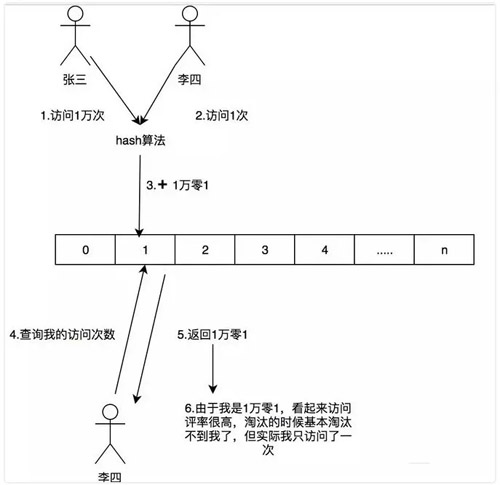
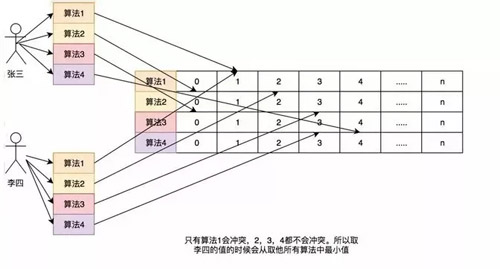
這里和以前的做個(gè)對(duì)比,簡(jiǎn)單的舉個(gè)例子:如果一個(gè) HashMap 來(lái)記錄這個(gè)頻率,如果我有 100 個(gè)數(shù)據(jù),那這個(gè) HashMap 就得存儲(chǔ) 100 個(gè)這個(gè)數(shù)據(jù)的訪問(wèn)頻率。
哪怕我這個(gè)緩存的容量是 1,因?yàn)?LFU 的規(guī)則我必須全部記錄這 100 個(gè)數(shù)據(jù)的訪問(wèn)頻率。如果有更多的數(shù)據(jù)我就有記錄更多的。
在 Count-Min Sketch 中,我這里直接說(shuō) Caffeine 中的實(shí)現(xiàn)吧(在 FrequencySketch 這個(gè)類中),如果你的緩存大小是 100,他會(huì)生成一個(gè) Long 數(shù)組大小是和 100 最接近的 2 的冪的數(shù),也就是 128。
而這個(gè)數(shù)組將會(huì)記錄我們的訪問(wèn)頻率。在 Caffeine 中它規(guī)則頻率最大為 15,15 的二進(jìn)制位 1111,總共是 4 位,而 Long 型是 64 位。所以每個(gè) Long 型可以放 16 種算法,但是 Caffeine 并沒(méi)有這么做,只用了四種 hash 算法,每個(gè) Long 型被分為四段,每段里面保存的是四個(gè)算法的頻率。
這樣做的好處是可以進(jìn)一步減少 hash 沖突,原先 128 大小的 hash,就變成了 128X4。
一個(gè)Long的結(jié)構(gòu)如下:
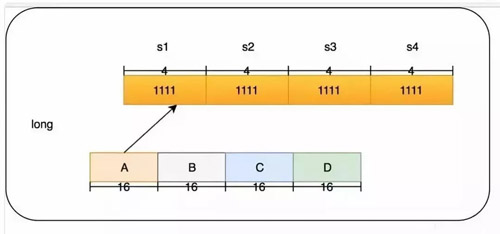
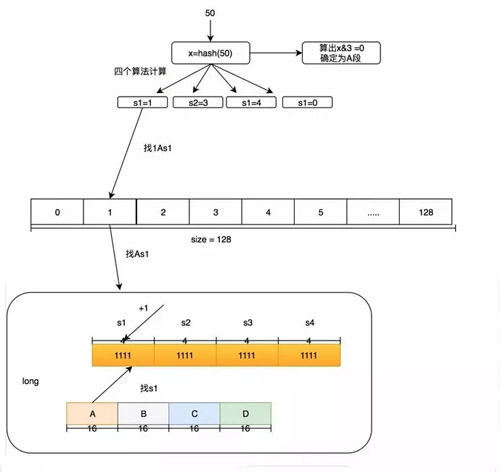
我們的 4 個(gè)段分為 A,B,C,D,在后面我也會(huì)這么叫它們。而每個(gè)段里面的四個(gè)算法我叫他 s1,s2,s3,s4。下面舉個(gè)例子,如果要添加一個(gè)訪問(wèn) 50 的數(shù)字頻率應(yīng)該怎么做?我們這里用 size=100 來(lái)舉例。
- 首先確定 50 這個(gè) hash 是在哪個(gè)段里面,通過(guò) hash & 3 必定能獲得小于 4 的數(shù)字,假設(shè) hash & 3=0,那就在 A 段。
- 對(duì) 50 的 hash 再用其他 hash 算法再做一次 hash,得到 Long 數(shù)組的位置。假設(shè)用 s1 算法得到 1,s2 算法得到 3,s3 算法得到 4,s4 算法得到 0。
- 然后在 Long[1] 的 A 段里面的 s1 位置進(jìn)行+1,簡(jiǎn)稱 1As1 加 1,然后在 3As2 加 1,在 4As3 加 1,在 0As4 加 1。
這個(gè)時(shí)候有人會(huì)質(zhì)疑頻率最大為 15 的這個(gè)是否太小?沒(méi)關(guān)系在這個(gè)算法中,比如 size 等于 100,如果他全局提升了 1000 次就會(huì)全局除以 2 衰減,衰減之后也可以繼續(xù)增加,這個(gè)算法再 W-TinyLFU 的論文中證明了其可以較好的適應(yīng)時(shí)間段的訪問(wèn)頻率。
讀寫(xiě)性能
在 Guava Cache 中我們說(shuō)過(guò)其讀寫(xiě)操作中夾雜著過(guò)期時(shí)間的處理,也就是你在一次 put 操作中有可能還會(huì)做淘汰操作,所以其讀寫(xiě)性能會(huì)受到一定影響。
可以看上面的圖中,Caffeine 的確在讀寫(xiě)操作上面完爆 Guava Cache。主要是因?yàn)樵?Caffeine,對(duì)這些事件的操作是通過(guò)異步操作,它將事件提交至隊(duì)列,這里的隊(duì)列的數(shù)據(jù)結(jié)構(gòu)是 RingBuffer。
然后會(huì)通過(guò)默認(rèn)的 ForkJoinPool.commonPool(),或者自己配置線程池,進(jìn)行取隊(duì)列操作,然后在進(jìn)行后續(xù)的淘汰,過(guò)期操作。
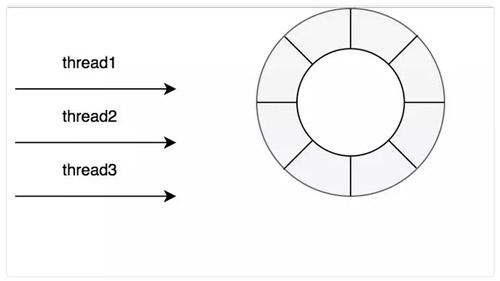
當(dāng)然讀寫(xiě)也是有不同的隊(duì)列,在 Caffeine 中認(rèn)為緩存讀比寫(xiě)多很多,所以對(duì)于寫(xiě)操作是所有線程共享一個(gè) Ringbuffer。
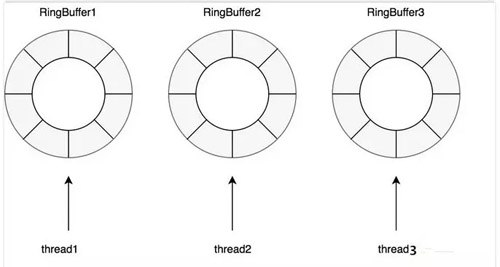
對(duì)于讀操作比寫(xiě)操作更加頻繁,進(jìn)一步減少競(jìng)爭(zhēng),其為每個(gè)線程配備了一個(gè) RingBuffer:
數(shù)據(jù)淘汰策略
在 Caffeine 所有的數(shù)據(jù)都在 ConcurrentHashMap 中,這個(gè)和 Guava Cache 不同,Guava Cache 是自己實(shí)現(xiàn)了個(gè)類似 ConcurrentHashMap 的結(jié)構(gòu)。在 Caffeine 中有三個(gè)記錄引用的 LRU 隊(duì)列:
- Eden 隊(duì)列:在 Caffeine 中規(guī)定只能為緩存容量的 %1,如果 size=100,那這個(gè)隊(duì)列的有效大小就等于 1。這個(gè)隊(duì)列中記錄的是新到的數(shù)據(jù),防止突發(fā)流量由于之前沒(méi)有訪問(wèn)頻率,而導(dǎo)致被淘汰。
比如有一部新劇上線,在最開(kāi)始其實(shí)是沒(méi)有訪問(wèn)頻率的,防止上線之后被其他緩存淘汰出去,而加入這個(gè)區(qū)域。伊甸區(qū),最舒服最安逸的區(qū)域,在這里很難被其他數(shù)據(jù)淘汰。
- Probation 隊(duì)列:叫做緩刑隊(duì)列,在這個(gè)隊(duì)列就代表你的數(shù)據(jù)相對(duì)比較冷,馬上就要被淘汰了。這個(gè)有效大小為 size 減去 eden 減去 protected。
- Protected 隊(duì)列:在這個(gè)隊(duì)列中,可以稍微放心一下了,你暫時(shí)不會(huì)被淘汰,但是別急,如果 Probation 隊(duì)列沒(méi)有數(shù)據(jù)了或者 Protected 數(shù)據(jù)滿了,你也將會(huì)面臨淘汰的尷尬局面。
當(dāng)然想要變成這個(gè)隊(duì)列,需要把 Probation 訪問(wèn)一次之后,就會(huì)提升為 Protected 隊(duì)列。這個(gè)有效大小為(size 減去 eden) X 80% 如果 size =100,就會(huì)是 79。
這三個(gè)隊(duì)列關(guān)系如下:
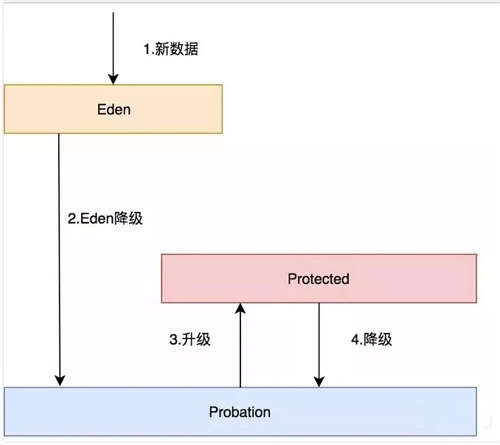
- 所有的新數(shù)據(jù)都會(huì)進(jìn)入 Eden。
- Eden 滿了,淘汰進(jìn)入 Probation。
- 如果在 Probation 中訪問(wèn)了其中某個(gè)數(shù)據(jù),則這個(gè)數(shù)據(jù)升級(jí)為 Protected。
- 如果 Protected 滿了又會(huì)繼續(xù)降級(jí)為 Probation。
對(duì)于發(fā)生數(shù)據(jù)淘汰的時(shí)候,會(huì)從 Probation 中進(jìn)行淘汰,會(huì)把這個(gè)隊(duì)列中的數(shù)據(jù)隊(duì)頭稱為受害者,這個(gè)隊(duì)頭肯定是最早進(jìn)入的,按照 LRU 隊(duì)列的算法的話那它就應(yīng)該被淘汰,但是在這里只能叫它受害者,這個(gè)隊(duì)列是緩刑隊(duì)列,代表馬上要給它行刑了。
這里會(huì)取出隊(duì)尾叫候選者,也叫攻擊者。這里受害者會(huì)和攻擊者做 PK,通過(guò)我們的 Count-Min Sketch 中的記錄的頻率數(shù)據(jù)有以下幾個(gè)判斷:
- 如果攻擊者大于受害者,那么受害者就直接被淘汰。
- 如果攻擊者<=5,那么直接淘汰攻擊者。這個(gè)邏輯在他的注釋中有解釋: 他認(rèn)為設(shè)置一個(gè)預(yù)熱的門檻會(huì)讓整體命中率更高。
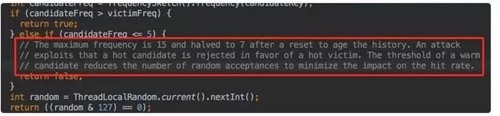
- 其他情況,隨機(jī)淘汰。
如何使用
對(duì)于熟悉 Guava 的玩家來(lái)說(shuō),如果擔(dān)心有切換成本,那么你就多慮了, Caffeine 的 api 借鑒了 Guava 的 api,可以發(fā)現(xiàn)其基本一模一樣。
- public static void main(String[] args) {
- Cache<String, String> cache = Caffeine.newBuilder()
- .expireAfterWrite(1, TimeUnit.SECONDS)
- .expireAfterAccess(1,TimeUnit.SECONDS)
- .maximumSize(10)
- .build();
- cache.put("hello","hello");
- }
順便一提的是,越來(lái)越多的開(kāi)源框架都放棄了 Guava Cache,比如 Spring5。在業(yè)務(wù)上我也曾經(jīng)比較過(guò) Guava Cache 和 Caffeine,最終選擇了 Caffeine,在線上也有不錯(cuò)的效果。所以不用擔(dān)心 Caffeine 不成熟,沒(méi)人使用。
最后
本文主要講述愛(ài)奇藝的緩存之路和本地緩存的一個(gè)發(fā)展歷史(從古至今到未來(lái)),以及每一種緩存的實(shí)現(xiàn)基本原理。
當(dāng)然要使用好緩存光是這些遠(yuǎn)遠(yuǎn)不夠,比如本地緩存如何在其他地方更改了之后同步更新,分布式緩存,多級(jí)緩存等等。后面也會(huì)專門寫(xiě)一節(jié)介紹這個(gè)如何用好緩存。
對(duì)于 Guava Cache 和 Caffeine 的原理后面也會(huì)專門抽出時(shí)間寫(xiě)這兩個(gè)的源碼分析,如果感興趣的朋友可以關(guān)注公眾號(hào)第一時(shí)間查閱更新文章。


















