集成學習:三個臭皮匠,賽過諸葛亮
原創【51CTO.com原創稿件】俗話說“三個臭皮匠,頂個諸葛亮”,多個比較弱的人若能有一種方法集中利用他們的智慧,也可以達到比較好的效果。
其實,集成學習的思路亦是如此——在對新的實例進行分類的時候,把若干個單個分類器集成起來,通過對多個分類器的分類結果進行某種組合來決定最終的分類,以取得比單個分類器更好的性能。
如果把單個分類器比作一個決策者的話,集成學習的方法就相當于多個決策者共同進行一項決策。
目前,集成學習的常用算法有三種,分別為:bagging,boosting和stacking。
Bagging 算法,或稱 Bootstrap Aggregating 算法。大家通常使用 Bagging 這個名字,是因為它是綜合了Bootstrapping和Aggregagtion而形成的一個組合模型。
Bagging算法主要對樣本訓練集合進行隨機化抽樣,通過反復的抽樣訓練新的模型,最終在這些模型的基礎上選取綜合預測結果。
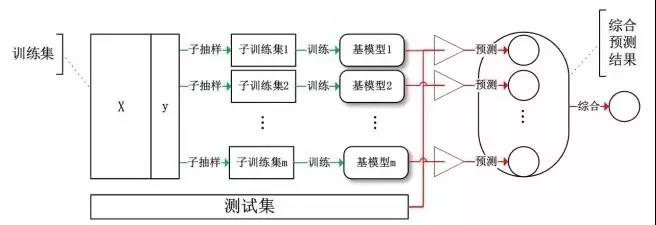
Bagging
基于Bagging的代表算法有隨機森林
Boosting(提升)算法,是常用的有效的統計學習算法,屬于迭代算法。Boosting和Bagging的區別在于是對加權后的數據利用弱分類器依次進行訓練。
Boosting通過不斷地使用一個弱學習器彌補前一個弱學習器的“不足”的過程,來串行地構造一個較強的學習器,這個強學習器能夠使目標函數值足夠小。
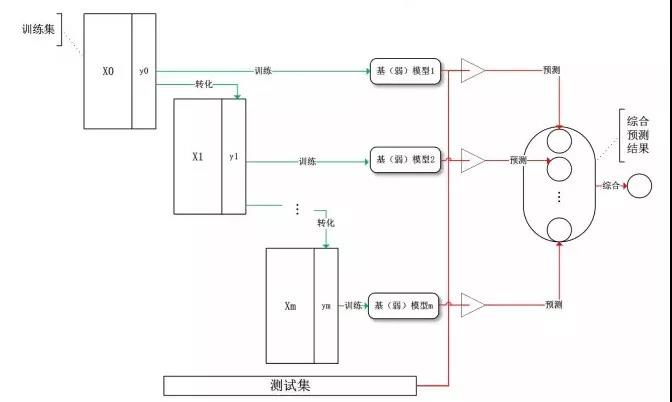
Boosting
Boosting系列算法里***算法主要有AdaBoost算法和GBDT算法。
Stacking(堆疊)算法是通過一個元分類器或者元回歸器來整合多個分類模型或回歸模型的集成學習技術。基礎模型利用整個訓練集做訓練,元模型將基礎模型的特征作為特征進行訓練。
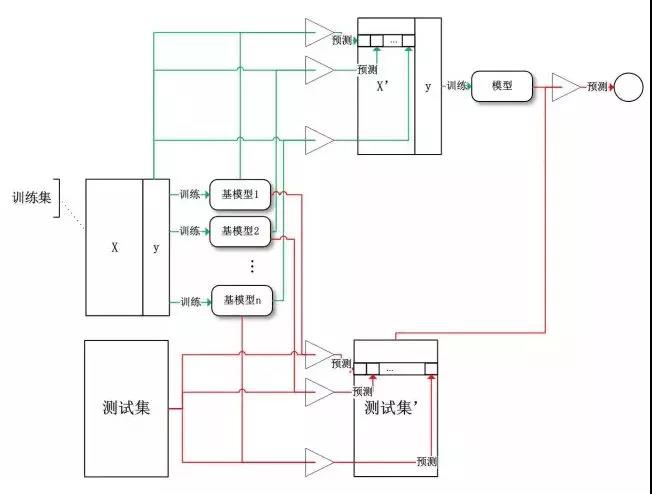
Stacking
基礎模型通常包含不同的學習算法,因此stacking通常是異質集成。
對數值型輸出,最常見的結合策略是使用平均法。
-
簡單平均法
-
加權平均法
但是對于規模比較大的集成來說,權重參數比較多,較容易導致過擬合。加權平均法未必一定優于簡單平均法。
一般而言,在個體學習器性能相差較大時,宜使用加權平均法,而在個體學習器性能相近時,宜使用簡單平均法。
相對多數投票法:預測為得票最多的標記。若同時有多個標記獲得***票,則從中隨機選取一個。
假設我們的預測類別是,對于任意一個預測樣本x,我們的個弱學習器的預測結果分別是。 最簡單的投票法是相對多數投票法,也就是我們常說的少數服從多數,也就是個弱學習器的對樣本X的預測結果中,數量最多的類別為最終的分類類別。如果不止一個類別獲得***票,則隨機選擇一個做最終類別。
絕對多數投票法:若某標記得票過半數,則預測為該標記;否則拒絕預測。
與相對多數投票法相比較為復雜,也就是我們常說的要票過半數。在相對多數投票法的基礎上,不光要求獲得***票,還要求票過半數。
加權投票法:算法更為復雜,和加權平均法一樣,每個弱學習器的分類票數要乘以一個權重,最終將各個類別的加權票數求和,***的值對應的類別為最終類別。
當訓練數據很多時,為了盡量縮小誤差,可利用一種更為強大的結合策略,便是使用“學習法”,即通過另一個學習器來進行結合。
對于學習法,代表方法是stacking,當使用stacking的結合策略時, 我們不是對弱學習器的結果做簡單的邏輯處理,而是再加上一層學習器,也就是說,我們將訓練集弱學習器的學習結果作為輸入,將訓練集的輸出作為輸出,重新訓練一個學習器來得到最終結果。
在這種情況下,我們將弱學習器稱為初級學習器,將用于結合的學習器稱為次級學習器。對于測試集,我們首先用初級學習器預測一次,得到次級學習器的輸入樣本,再用次級學習器預測一次,得到最終的預測結果。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】