













科普 | 從TensorFlow.js入手了解機器學習

對前端開發者來說了解機器學習是一件有挑戰性的事情。我學習機器學習沒有多久,在這個領域是個新手,在本文里我將嘗試用自己的理解去解釋一些概念。
不過,在使用已有的 AI 模型的時候我們并不需要很深的機器學習知識。我們可以使用現有的一些工具比如 Keras、TensorFlow 或 TensorFlow.js。這里我們將看看如何創建 AI 模型并且使用 TensorFlow.js 中的一些復雜的模型。
雖說不需要很深的知識,不過還是讓我來解釋一些基本概念。
什么是模型?
或者更好的問題是:什么是現實?是的,這很難回答,我們必須簡化問題以便理解。
表現部分簡化版現實的一個方法就是使用模型。所以,你可以認為有無數個模型,如世界地圖、圖表等等。
沒有機器參與其中的模型我們更易于理解。比如,如果我們想要創建一個模型來表示隨房間數變化 Barcelona 房子價格的變化。
首先,我們需要收集一些數據:
| Number of rooms | Prices |
|---|---|
| 3 | 131.000€ |
| 3 | 125.000€ |
| 4 | 235.000€ |
| 4 | 265.000€ |
| 5 | 535.000€ |
然后,我們將這兩個數據使用一個 2D 圖形展示,每個坐標軸對應一個參數。

然后...Duang! 我們現在可以畫一條線并且預測有 6 個以上房間的房子價格。
這個模型叫做線性回歸,這是機器學習里最簡單的模型之一。
當然,這個模型還不夠好:
- 只有 5 個樣本,結果不夠可信
- 只有兩個參數,但其實影響房子價格有更多的因素,如地理位置、房子年齡等
對于***個問題,我們可以添加樣本數來解決,比如添加 100 萬個數據。
對第二個問題,我們可以添加更多的坐標軸。在 2D 圖形上我們可以畫一條直線,在 3D 坐標軸里我們可以畫一個平面。

但是,如何處理 3D 以上的情形,比如 4D 甚至是 1000000D 呢?
我們的大腦無法想象多維下的圖表,不過好消息是,我們可以用數學和計算超平面來處理這種情況,而神經網絡是一個很好的處理工具。
順便,使用 TensorFlow.js 不需要成為數學專家。
什么是神經網絡?
在理解神經網絡之前,讓我們先來看看什么是神經。
現實世界里的神經差不多長這樣:

神經中最重要的部分包括:
- 樹狀突(Dendrites):數據輸入的地方。
- 軸突(Axon):輸出端。
- 突觸(Synapse):神經之間進行交流的結構。它負責將電信號從神經軸突的末端傳遞到附近神經的樹狀突。這些突觸結構是學習的關鍵,因為它們在使用中會增減電信號的活動。
在機器學習中的神經則是 (簡化后):

- 輸入(Input):輸入的參數。
- 權值(Weight):和突觸一樣,它們以增減來調整神經的活動來達成更好的線性回歸。
- 線性函數 (Linear function):每個神經就像一個線性回歸函數,目前為止一個線性回歸函數只需要一個神經。
- 激活函數 (Activation function):我們能提供一些激活函數來改變從一個標量 (Scalar) 到另一個非線性的函數。比如:sigmoid、RELU、tanh。
- 輸出 (Output):經過激活函數計算后的輸出結果。
激活函數的使用非常有用,它是神經網絡的精髓所在。沒有激活函數的話神經網絡不可能很智能。原因是盡管在網絡中你可能有很多神經,神經網絡的輸出總會是一個線性回歸。我們需要一些機制來改變這個獨立的線性回歸為非線性的以解決非線性的問題。
感謝這些激活函數,我們可以將這些線性函數轉換到非線性函數:

訓練模型
在上面的 2D 線性回歸示例里,在圖表中畫條線就足以讓我們開始預測新數據了。然而,“深度學習”的概念是要讓我們的神經網絡學著畫這條線。
畫一條簡單的線我們只需要包括一條神經的非常簡單的神經網絡,但其它的模型做的要復雜的多,比如歸類兩組數據。在這種情況下,“訓練”將會學習如何畫出下面的圖像:

這還不算復雜的,因為這只是 2D 范疇內。
每個模型都是一個世界,所有這些模型的訓練的概念都差不多。首先是畫一條隨機的線,然后在一個循環算法中改進它,修復每個循環中的錯誤。這種優化算法又叫做梯度下降法 (Gradient Descent),還有更多復雜的算法如 SGD、ADAM,概念都類似。
為了理解梯度下降法,我們需要知道每個算法 (線性回歸、邏輯回歸等) 有不同的代價函數 (cost function) 來度量這些錯誤。
代價函數總會收斂于某個點,它可能是凸或非凸函數。***的收斂點將在 0% 錯誤時被發現,我們的目標就是到達這個點。

但我們使用梯度下降算法時,我們開始于一個隨機的點,但是我們不知道它在哪。想象一下你在一座山上,完全失明,然后你需要一步一步的下山,走到***的位置。如果地形復雜 (像非凸函數),下降過程將更加復雜。
我不會深入的解釋什么是梯度下降算法。你只需要記住它是一種優化算法,用來訓練 AI 模型以最小化預測產生的錯誤。這個算法需要時間和 GPU 來計算矩陣乘法。收斂點通常在***輪執行中難以達到,所以我們需要對一些超參數 (hyperparameter) 如學習率(learning rate)進行調優,或者添加一些正則化 (regularization)。
經過反復的梯度下降法,我們達到了離收斂點很近的地方,錯誤率也接近 0%。這時候,我們的模型就創建成功,可以開始進行預測了。

使用 TensorFlow.js 來訓練模型
TensorFlow.js 給我們提供了一個簡單的辦法來創建神經網絡。
首先,我們將先創建一個 LinearModel 類,添加trainModel方法。
對這類模型我將使用一個序列模型 (sequential model),序列模型指的是某一層的輸出是下一層的輸入,比如當模型的拓撲結構是一個簡單的棧,不包含分支和跳過。
在trainModel方法里我們將定義層 (只需要使用一個,這對于線性回歸問題來說足夠了):
- import * as tf from '@tensorflow/tfjs';
- /**
- * Linear model class
- */
- export default class LinearModel {
- /**
- * Train model
- */
- async trainModel(xs, ys){
- const layers = tf.layers.dense({
- units: 1, // Dimensionality of the output space
- inputShape: [1], // Only one param
- });
- const lossAndOptimizer = {
- loss: 'meanSquaredError',
- optimizer: 'sgd', // Stochastic gradient descent
- };
- this.linearModel = tf.sequential();
- this.linearModel.add(layers); // Add the layer
- this.linearModel.compile(lossAndOptimizer);
- // Start the model training!
- await this.linearModel.fit(
- tf.tensor1d(xs),
- tf.tensor1d(ys),
- );
- }
- ...more
- }
該類的使用方法:
- const model = new LinearModel();
- // xs and ys -> array of numbers (x-axis and y-axis)
- await model.trainModel(xs, ys);
訓練結束后,我們可以開始進行預測了!
使用 TensorFlow.js 進行預測
預測的部分通常會簡單些。訓練模型需要定義一些超參數,相比之下,進行預測很簡單。我們將在 LinearRegressor 類里添加該方法:
- import * as tf from '@tensorflow/tfjs';
- export default class LinearModel {
- ...trainingCode
- predict(value){
- return Array.from(
- this.linearModel
- .predict(tf.tensor2d([value], [1, 1]))
- .dataSync()
- )
- }
- }
現在,我們在代碼里使用預測方法
- const prediction = model.predict(500); // Predict for the number 500
- console.log(prediction) // => 420.423
; // Predict for the number 500 console.log(prediction) // => 420.423")
你可以在線運行一下這段代碼:
https://stackblitz.com/edit/linearmodel-tensorflowjs-react
在 TensorFlow.js 中使用訓練好的模型
學習如何創建模型是最難的部分,正常化訓練數據,正確選擇所有的超參數,等等。如果你是新手并且想使用某些模型玩玩,你可以使用訓練好的模型。
有很多模型都可以在 TensorFlow.js 中使用,而且,你可以使用 TensorFlow 或 Keras 創建模型,然后導入到 TensorFlow.js。
比如,你可以使用 posenet 模型 (實時人類姿態模擬) 來做些好玩的事情:
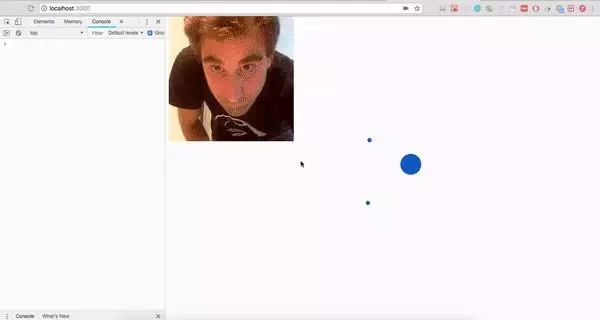
代碼在: https://github.com/aralroca/posenet-d3
它的使用非常簡單:
- import * as posenet from '@tensorflow-models/posenet';
- // Constants
- const imageScaleFactor = 0.5;
- const outputStride = 16;
- const flipHorizontal = true;
- const weight = 0.5;
- // Load the model
- const net = await posenet.load(weight);
- // Do predictions
- const poses = await net
- .estimateSinglePose(
- imageElement,
- imageScaleFactor,
- flipHorizontal,
- outputStride
- );
poses 變量在這個 JSON 文件里:
- {
- "score": 0.32371445304906,
- "keypoints": [
- {
- "position": {
- "y": 76.291801452637,
- "x": 253.36747741699
- },
- "part": "nose",
- "score": 0.99539834260941
- },
- {
- "position": {
- "y": 71.10383605957,
- "x": 253.54365539551
- },
- "part": "leftEye",
- "score": 0.98781454563141
- },
- // ...And for: rightEye, leftEar, rightEar, leftShoulder, rightShoulder
- // leftElbow, rightElbow, leftWrist, rightWrist, leftHip, rightHip,
- // leftKnee, rightKnee, leftAnkle, rightAnkle
- ]
- }
想象一下僅僅這個模型就可以做多少有趣的事情啊!
上面這個示例代碼在: https://github.com/aralroca/fishFollow-posenet-tfjs
從 Keras 導入模型
我們可以從外部導入模型到 TensorFlow.js,在下面的例子里,我們將使用一個 Keras 的模型來進行數字識別 (文件格式為 h5)。為了達到目的,我們需要使用 tfjs_converter。
- pip install tensorflowjs
然后,使用轉換工具:
- tensorflowjs_converter --input_format keras keras/cnn.h5 src/assets
現在,你可以將模型導入到 JS 代碼里了。
- // Load model
- const model = await tf.loadModel('./assets/model.json');
- // Prepare image
- let img = tf.fromPixels(imageData, 1);
- img = img.reshape([1, 28, 28, 1]);
- img = tf.cast(img, 'float32');
- // Predict
- const output = model.predict(img);
僅需幾行代碼,你就可以使用 Keras 中的數字識別模型。當然,我們還可以加入一些更好玩的邏輯,比如,添加一個 canvas 來畫一個數字,然后捕捉圖像來識別數字。

代碼: https://github.com/aralroca/MNIST_React_TensorFlowJS
為何在瀏覽器運行 AI?
如果硬件不行,在瀏覽器上訓練模型可能效率非常低下。TensorFlow.js 借助了 WebGL 的接口來加速訓練,但即使這樣它也比 TensorFlow Python 版本要慢 1.5-2 倍。
但是,在 TensorFlow.js 之前,我們基本不可能不靠 API 交互在瀏覽器使用機器學習模型。現在我們可以在我們的應用里 離線的 訓練和使用模型。并且,無需與服務端交互讓預測變得更快。
另一個好處是在瀏覽器執行這些計算可以降低服務器開銷,節省成本。
結論
- 模型是我們用于展現現實某一部分的簡化手段,可以用來進行預測。
- 創建模型的一個好方式是使用神經網絡。
- 創建神經網絡的簡單易用方式是 TensorFlow.js。



















