敢啃“硬骨頭”,開源分布式數(shù)據(jù)庫TiDB如何煉成?
原創(chuàng)【51CTO.com原創(chuàng)稿件】如今硬件的性價比越來越高,網(wǎng)絡傳輸速度越來越快,數(shù)據(jù)庫分層的趨勢逐漸顯現(xiàn),人們已經(jīng)不再強求用一個解決方案來解決所有的存儲問題,而是通過分層,讓緩存與數(shù)據(jù)庫負責各自擅長的業(yè)務場景。
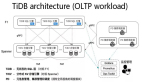
TiDB 作為一款 HTAP 數(shù)據(jù)庫,在高性能的實現(xiàn) OLTP 特性基礎之上,也同時提供基于實時交易數(shù)據(jù)的實時業(yè)務分析需求。
2018 年 5 月 18-19 日,由 51CTO 主辦的全球軟件與運維技術(shù)峰會在北京召開。
在“大數(shù)據(jù)處理技術(shù)”分會場,PingCAP CTO 黃東旭帶來了《How can HTAP help you:ATiDB Story》的主題演講。
他分享了 TiDB 的設計思路、現(xiàn)實應用場景,以及 TiDB 集群在部署和運營方面的***實踐。
什么是 TiDB 數(shù)據(jù)庫?
TiDB 是一個數(shù)據(jù)庫。我們知道市面上有很多類似 MySQL、Oracle 的數(shù)據(jù)庫。為什么還需要一個新的數(shù)據(jù)庫?
相信大家 90% 都使用過 MySQL。但是當 MySQL 的數(shù)據(jù)量比較大或者說并發(fā)開始撐不住的時候,能有什么選擇?
其實選擇沒多少。一個是完全不用 MySQL,而是用 NoSQL。比如說 HBase 或者 Cassandra 去做數(shù)據(jù)庫。
但是相應的代價就是失去了 SQL 的復雜查詢的能力,還有整個 MySQL 的 EcoSystem。
NoSQL 可以帶來橫向的水平拓展能力,但是會面臨整個業(yè)務代碼的重寫。這在很多場景下是不太現(xiàn)實的。
所以很多時候還是得用 MySQL,但是 MySQL 在數(shù)量方面有各種各樣的限制。所以過去我們能做的事情就是 Sharding,水平分區(qū),分庫分表。
但是很多時候雖然你做了水平切分,分庫分表,但是 Scale 還是一個非常大的問題。
另外一點比如說你用了讀寫分離,或者你可能用了 Cassandra 這樣的最終一次性的系統(tǒng),對于開發(fā)者來說這個新支付單是比較大的。
如果你沒有一個強一致的、持久化的存儲系統(tǒng),你的業(yè)務層的代碼是很難寫的,特別是對一些金融場景或者說對一致性要求比較高的業(yè)務。
另外,我們的數(shù)據(jù)倉庫、大數(shù)據(jù)分析的解決方案和數(shù)據(jù)庫的解決方案中間基本是徹底割裂的。
這兩年大家常用的 RabbitMQ 或者 Kafka 這樣的管道系統(tǒng),就是嘗試在數(shù)據(jù)庫和數(shù)據(jù)倉庫之間構(gòu)建一個橋梁。有沒有辦法能夠把實時的 OLAP 直接就在數(shù)據(jù)庫層面做?
或者說現(xiàn)在你用了 MySQL 的 Sharding,要去做一個簡單的跨業(yè)務的 join 的分析,都得把這個數(shù)據(jù)通過 ETL 導到 Hadoop 或者 data warehouse 里面再去做分析。

維護 ETL 的過程是一個比較麻煩的事情。另外一個問題是數(shù)據(jù)分析師可能不是一個工程師或者說一個技術(shù)很強的人,所以在技術(shù)選型上會有各種限制。
能不能就直接在數(shù)據(jù)庫上去做一些 in-place 的查詢呢,這是一個問題。另外一個就是大的趨勢,大家都在思考數(shù)據(jù)庫這樣的業(yè)務怎么去跟現(xiàn)有云架構(gòu)去整合。
舉例來說你不可能直接把一個 MySQL 實例放到一個 Container 里面,因為如果 Container 掛了,數(shù)據(jù)就沒了。
怎么去面向一個云環(huán)境或者一個可以彈性伸縮的容器環(huán)境,設計一個可以彈性伸縮的數(shù)據(jù)庫,這其實是個很大的問題。
還有一個特別大的痛點,就是在做高可用的時候人是會出錯的。我們現(xiàn)在做數(shù)據(jù)庫碰到這些問題的原因是什么呢?
我個人認為關系型數(shù)據(jù)庫像 MySQL,Oracle 這些本身不是面向分布式去做設計的。
另外,即使你勉強做這個分庫分表等操作,本質(zhì)上來說你只是把 MySQL 再復制了一遍,并不是針對它是一個分布式系統(tǒng)來做存儲和計算的優(yōu)化。
這就是問題,而這也是為什么我們會覺得我在做一些跨業(yè)務的查詢或者說一些跨物理的這個機器的查詢和寫入會比較麻煩的原因。
但是終于這個情況在發(fā)生變化, 因為在 2000 年以后,分布式系統(tǒng)理論開始變?yōu)橹髁鳌?/p>
這有一個歷史發(fā)展的背景,就是過去硬件價格昂貴,而且網(wǎng)絡環(huán)境不好。所以盡可能把計算給放在本地去做。
因為 SSD 的出現(xiàn),現(xiàn)在磁盤 IO 基本上問題已經(jīng)不大了,而 Intel 很快會發(fā)布持久化內(nèi)存。像這種技術(shù)基本上解決了數(shù)據(jù)庫 IO 層上的問題。
現(xiàn)在在 Google 內(nèi)部,同一個數(shù)據(jù)中心內(nèi)讀取遠程磁盤,跟讀取本地磁盤的吞吐和延遲基本是可以做到一致的。
在這種情況下你可以認為整個數(shù)據(jù)中心就是一臺計算機,你重新去設計數(shù)據(jù)庫的時候,它本質(zhì)上就是一個分布式系統(tǒng)。
第三點就是大家的思維在發(fā)生改變,大家不再幻想有一個***的解決方案去解決掉所有存儲上的問題。
易維護
TiDB 這個項目是在三年前開始的。項目就是上面介紹的背景,我過去在豌豆莢一直維護 MySQL 集群。
后來因為關系型數(shù)據(jù)庫不易維護,經(jīng)常想能不能有一個數(shù)據(jù)庫可以結(jié)合 MySQL 和 NoSQL 的優(yōu)點。
所以這就是最開始的初心,我們要去做一個功能完備的 SQL,***去兼容現(xiàn)有的,至少是這些常用的復雜查詢、子查詢業(yè)務。
然后同時要以一個 MySQL 的協(xié)議和用法去面向客戶,或者用戶。這一點很重要,它可以極大地降低用戶去試你產(chǎn)品的成本。
事務
第二點就是事務,事務是絕對不能少的。我覺得過去這十年 NoSQL 的社區(qū)有一個特別大的問題就是追求可擴展性,但是放棄了強一致事務的支持,這是不對的。
過去不實現(xiàn)這個功能的理由是這個功能會導致系統(tǒng)延遲,性能下降。但是我覺得以犧牲數(shù)據(jù)準確性為代價去實現(xiàn)這個功能是不現(xiàn)實的。
這就相當于本來這個事情應該數(shù)據(jù)庫來做,這些 NoSQL 系統(tǒng)卻強行把這個事情交給業(yè)務層做。這會給寫業(yè)務帶來一個極大的問題。
另外一個就是擴展的易用性,就是能不能做到我這里用了一個詞叫做 push-button scaling。
我簡單地扔一臺機器進去,不做任何的 resharding,不做任何的修改配置,這個系統(tǒng)自己就擴大了,自己去做 rebalancing,這跟傳統(tǒng)的 Sharding 方案有本質(zhì)的區(qū)別。
高可用
然后 HA 是什么?HA 就是高可用,這個問題是傳統(tǒng)方案很難解決的。就是一切都是需要人工去做這個數(shù)據(jù)校驗和流量的切換。
沒有辦法能做到真正的 HA,這個數(shù)據(jù)庫能不能自動地自己去運維、自己去修復自己,自己去保證這個系統(tǒng)的可用性。
在這塊我們也做了一些工作,就是我們在底下的整個數(shù)據(jù)模型完全放棄掉了主從的模型,完全基于 Raft 跟 Paxos 這樣的一種分布式選舉算法來做。
這個還比較重要,因為如果一個系統(tǒng)你不能保證它的可用性,談再多的性能都是沒有意義的,特別是對于 OLTP 系統(tǒng)來說。
我的這個系統(tǒng)能不能既在上面去支持 ACID 事務,同時又可以利用 Spark 或者 Hadoop 去用整個機群的計算資源和能力,再去做一些復雜的 SQL 查詢的時候能加速。這個其實是可以做到的。
開源
***一點就是一定是***開源,通用的技術(shù)軟件不開源是絕對沒有未來的。
因為現(xiàn)在時代已經(jīng)變了,過去那種閉門造車,然后招一大堆銷售,挨家敲門說你要不要試一下的搞法是不對的,特別是平臺性質(zhì)的軟件。
而且開源會更加有利于去做軟件推廣,你的用戶越多,用戶給你的反饋就越多。
這會比自己在內(nèi)部去做軟件速度快得多。這也是為什么這個項目才開始三年,我們的客戶就超過了 2000 多家。
TiDB 數(shù)據(jù)庫的四大“殺手锏”
現(xiàn)在我來總結(jié)一下 TiDB 數(shù)據(jù)庫有哪些應用場景可以在你自己的業(yè)務里面去使用。
用例 1:MySQL 分片與合并
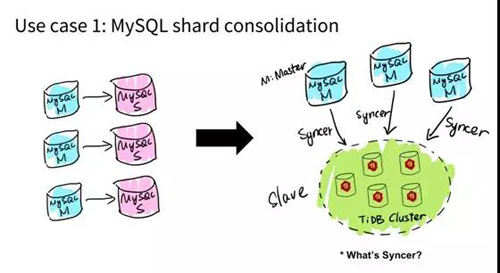
***種場景就是 MySQL,比如已有的業(yè)務使用了 MySQL Sharding,沒問題。現(xiàn)在 TiDB 因為在業(yè)務層實時兼容 MySQL 的這個訪問協(xié)議。
而且我們做了一個工具 Syncer,它能夠把 TiDB 作為一個 MySQL Master 的 Slave,在業(yè)務層前端可以是一個主庫 MySQL,而作為從庫的 TiDB 可以看做一個大的 MySQL。
過去我們有一個說法叫一主多從, 但現(xiàn)在有了 TiDB 以后,可以反過來說多主一從。
你可以把這多個 MySQL 組的不同的表、不同的業(yè)務、不同的庫,實時的 Binlog 的數(shù)據(jù)全都同步、匯總到一個大的分布式的 MySQL 上。
這個分布式 MySQL 就是 TiDB。在這個 MySQL 之上,你可以去用一些比較復雜的 Query,比如 join,groupby 全都可以。所以這個是一種用戶場景。
Syncer 是什么?我剛才簡單提了下,Syncer 是可以把自己偽裝成一個 MySQL 的 Slave 去做數(shù)據(jù)的同步的工具。
它本質(zhì)上是一個 Binlog Listener,會去監(jiān)聽 MySQL 的 Binlog,然后把它變成數(shù)據(jù)庫的語句。
用例 2:直接替換 MySQL
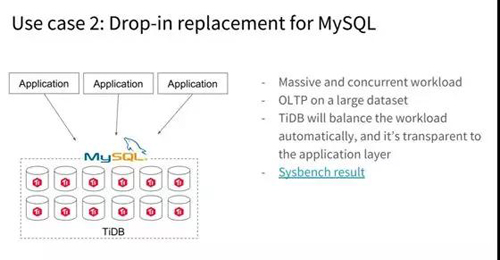
另外一個應用場景就非常簡單粗暴,最簡單的情況是業(yè)務在快速地增長,但是原來業(yè)務就是 MySQL 寫的,也沒考慮什么分庫分表,架構(gòu)這樣的事情。
摩拜早期的時候就用 MySQL。后來發(fā)現(xiàn)業(yè)務開始快速增長,公司在 30 人團隊規(guī)模的時候開始使用 TiDB。
然后一年之內(nèi)整個公司人數(shù)增長到 800 人,數(shù)據(jù)從很小的數(shù)據(jù)集到后來在 TiDB 上有幾十 T 的數(shù)據(jù),不需要再去做分庫分表。
所以在業(yè)務快速增長的場景下 TiDB 是個很好的選擇,然后對于 OLTP 的業(yè)務來說,TiDB 也是一個很好的選擇。
對吞吐來說,TiDB 基本上可以做到線型擴張,機器越多,性能越好。而對于延遲來說,TiDB 也有非常出色的表現(xiàn)。
用例 3:數(shù)據(jù)倉庫
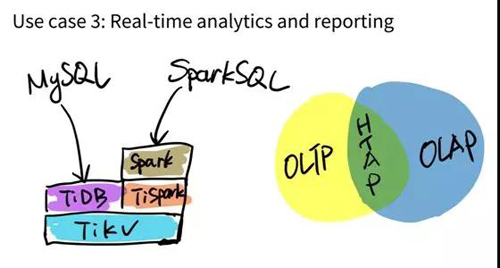
還有一類使用場景是直接把 TiDB 作為數(shù)據(jù)倉庫用。 TiDB 在 OLAP 的性能測評方面表現(xiàn)非常出眾。
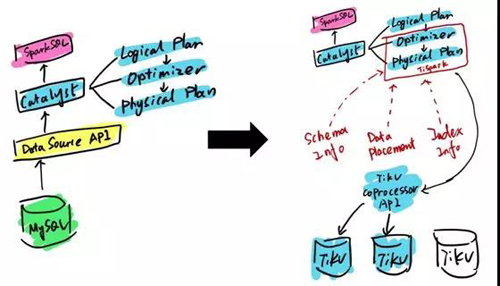
如果有一些特別復雜的 SQL,TiDB 的 SQL 層還是搞不定,我這邊也做了一個開源的項目,叫 TiSpark 。
它其實是一個 Spark 的插件,能夠讓用戶直接用 Spark SQL 來實時地在 TiKV 上做大數(shù)據(jù)分析。
第三個應用場景,TiDB 本身是一個存儲跟計算分開的一個項目。它底下 Key-Value 的那一層也可以單獨拿出來用,你可以把它當作一個 Hbase 的替代品, 同時支持跨行的事務。
TiDB 的項目其實是受到了 Google Spanner 這個系統(tǒng)的啟發(fā),是通過 NoSQL 這一層支持 transaction 的。
TiKV 提供了兩層 API,一層是支持跨行事物 transaction 的 API。第二層 API 叫弱 API,主要用來做單行的事務,不提供跨行事務的 ACID 的支持,但是換取的是整個性能和延遲的進一步提升。
所以如果有需要,事務可以用 transaction 的 API,如果需要性能,但是沒有強一致事務的跨行事務的需求,就用弱 API。弱 API 跟 Hbase 的一致性級別是一樣的。
用例 4:作為其他系統(tǒng)的基石

基于通用的 KV 層,我們是可以做到很多我們想做的事情。TiDB 并不只是一個簡單的數(shù)據(jù)庫項目,它應該是其他的分布式系統(tǒng)的 building block,可以作為其他系統(tǒng)構(gòu)建的基石。
TiDB 本身對外提供的是 MySQL 的接口,但是社區(qū)里面的小伙伴直接去給 TiKV 層去封裝一個 Redis 的協(xié)議層。
然后能讓用戶直接用 Redis 的協(xié)議去做 TiKV。這樣就變成了可持久化的 Scalable 的 Redis。
然后另外一個 Case,是在今日頭條用的,就是對外提供一個 S3,你想造自己的 S3 沒有問題。
但是造 S3 最難的部分是在源信息管理這塊,并不是它的 data nodes,所以如果你已經(jīng)有了一個支持跨事務的一個源信息存儲系統(tǒng),你可以做到自己去建造 S3。
我知道已經(jīng)有一些社區(qū)的同學構(gòu)建一整套新的分布式存儲的服務,現(xiàn)在 API 還沒有開源,但我覺得不久的未來會開源。
如何從 MySQL 遷移到 TiDB?
既然 TiDB 這么好,那現(xiàn)在怎么把 MySQL 遷移到 TiDB 上呢?因為 TiDB 其實是基于 MySQL 生態(tài)的,當然可以用 MySQLDump。

我們自己做了一個數(shù)據(jù)的導入導出工具叫 Lightning。為什么要做這個呢?

比如說過去我們?nèi)绻苯邮怯?MySQL 的協(xié)議,用 MyDumper、Myloader,就是簡單粗暴的導出導入。
那 TiDB 想要做什么事情呢?因為大家知道 MyDumper Dump 出來的就是 MySQL 一條條的語句。
然后在 TiDB 這邊要從 SQL,到它的 parser 到執(zhí)行計劃、指導事務、到 KV,***才寫到單機的 RocksDB 上面。
這個過程一遍遍重復執(zhí)行是一個很慢的過程,如下圖:
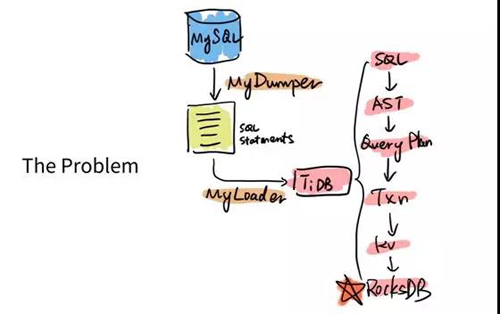
我們就想,有沒有辦法能夠直接繞過中間所有的東西,直接利用 MyDumper Dump 出來的這個 SQL 語句直接生成底下的 RocksDB 的數(shù)據(jù)的格式呢?當然可以。
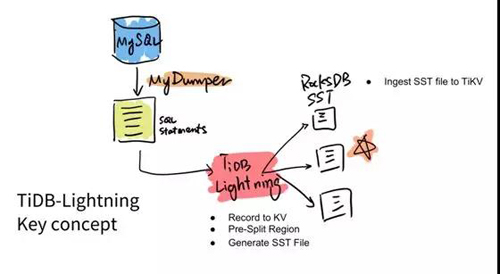
所以這就是 Lightning 在做的事情。你可以認為這是一個升級版的 MySQLDumper,直接 Dump 出 SQL 語句。
然后我們在 TiDB Lightning 這個項目內(nèi)部直接去做了這個 Record to KV,就是直接生成底層的 key-value pairs。然后同時在內(nèi)部去做數(shù)據(jù)分片,提前分好。
第三個就是直接去繞過中間所有的這些 SQL,直接去生成 RocksDB 的 SSD 文件,相當于存儲的格式文件發(fā)送給不同的機器。然后這個機器直接去把文件 Load 到數(shù)據(jù)庫里面就完成了,中間其實是很快的。
部署 TiDB,我們選的技術(shù)方案是 Ansible,所有的部署都是可以一鍵完成。然后包括性能調(diào)優(yōu)什么的完全是開源的。
我們目前正在把 TiDB 這個項目捐給 CNCF 基金會,正在跟 Kubernetes 進行整合,現(xiàn)在正在測試階段,未來肯定也會開源。
當然,如果你說想在本地自己去玩一玩,但是 TiDB 這么多組件,我能不能用一條命令就能在本地搭建一個完整的 TiDB Cluster 去做測試呢?當然可以。
我們這邊是有 Docker Compose,是兩條路徑,一條是 git clone,然后第二條是啟動。
它會啟動包括 Dashboard,數(shù)據(jù)的遷移、可視化,TiDB MySQL 的 Service endpoint、TiSpark 全都會在你的 Docker Container 去創(chuàng)建。
另外這還不夠,我們把一些核心算法通過數(shù)學的方式去形式化地證明它是正確的。
這個 TLA+ 的源碼文件開源了,大家如果想在自己的分布式系統(tǒng)里面去用 TLA+ 做數(shù)學上的證明,你可以去參考我們寫的文檔。所以我覺得測試反而是這個公司最重要的一塊資產(chǎn)。
總結(jié)

***,有幾個大的問題也是這段時間我思考得比較多的,比如說你整個集群云化了以后,在數(shù)據(jù)庫的層面上 Multi—tenancy 該怎么做?就是如何能去做到更有效的資源隔離和復用?
現(xiàn)在并沒有太好的解決方案,因為整個 IO 的隔離還是比較大的問題。
第二個就是自治,這個數(shù)據(jù)庫能不能擁有智能,就是我再不需要人工去做運維。
這個數(shù)據(jù)庫能夠自己部署,自己維護,自己更新。然后數(shù)據(jù)出現(xiàn)問題,自己修復;性能出現(xiàn)問題,自己調(diào)優(yōu)。
我們也在嘗試去把一些我們運營時的 Metric 往 Tensorflow 里面去導,自動地去做調(diào)優(yōu)。這個工作正在做,然后應該 CMU 是一些比較有意思的工作。
還有就是軟硬件的結(jié)合,就是說怎么去利用這些新時代的硬件來提升你的整個數(shù)據(jù)庫的穩(wěn)定性能。
黃東旭,PingCAP 的聯(lián)合創(chuàng)始人兼***技術(shù)官。他是分布式系統(tǒng)和數(shù)據(jù)庫開發(fā)方面的專家。他在分布式存儲方面擁有豐富的經(jīng)驗和獨特的見解。他是 Codis(一種常用的分布式 Redis 緩存解決方案)和 TiDB(一種分布式關系型數(shù)據(jù)庫)的聯(lián)合創(chuàng)始人。
【51CTO原創(chuàng)稿件,合作站點轉(zhuǎn)載請注明原文作者和出處為51CTO.com】