高并發的“大殺器”:異步化、并行化
高并發的大殺器:異步化
同步和異步,阻塞和非阻塞
同步和異步,阻塞和非阻塞,這幾個詞已經是老生常談,但是還是有很多同學分不清楚,以為同步肯定就是阻塞,異步肯定就是非阻塞,其實他們并不是一回事。
同步和異步關注的是結果消息的通信機制:
- 同步:調用方需要主動等待結果的返回。
- 異步:不需要主動等待結果的返回,而是通過其他手段,比如狀態通知,回調函數等。
阻塞和非阻塞主要關注的是等待結果返回調用方的狀態:
- 阻塞:是指結果返回之前,當前線程被掛起,不做任何事。
- 非阻塞:是指結果在返回之前,線程可以做一些其他事,不會被掛起。
可以看見同步和異步,阻塞和非阻塞主要關注的點不同,有人會問同步還能非阻塞,異步還能阻塞?
當然是可以的,下面為了更好的說明它們的組合之間的意思,用幾個簡單的例子說明:
同步阻塞:同步阻塞基本也是編程中最常見的模型,打個比方你去商店買衣服,你去了之后發現衣服賣完了,那你就在店里面一直等,期間不做任何事(包括看手機),等著商家進貨,直到有貨為止,這個效率很低。
- 同步非阻塞:同步非阻塞在編程中可以抽象為一個輪詢模式,你去了商店之后,發現衣服賣完了。
這個時候不需要傻傻的等著,你可以去其他地方比如奶茶店,買杯水,但是你還是需要時不時的去商店問老板新衣服到了嗎。
- 異步阻塞:異步阻塞這個編程里面用的較少,有點類似你寫了個線程池,submit 然后馬上 future.get(),這樣線程其實還是掛起的。
有點像你去商店買衣服,這個時候發現衣服沒有了,這個時候你就給老板留個電話,說衣服到了就給我打電話,然后你就守著這個電話,一直等著它響什么事也不做。這樣感覺的確有點傻,所以這個模式用得比較少。
- 異步非阻塞:這也是現在高并發編程的一個核心,也是今天主要講的一個核心。
好比你去商店買衣服,衣服沒了,你只需要給老板說這是我的電話,衣服到了就打。然后你就隨心所欲的去玩,也不用操心衣服什么時候到,衣服一到,電話一響就可以去買衣服了。
同步阻塞 PK 異步非阻塞
上面已經看到了同步阻塞的效率是多么的低,如果使用同步阻塞的方式去買衣服,你有可能一天只能買一件衣服,其他什么事都不能干;如果用異步非阻塞的方式去買,買衣服只是你一天中進行的一個小事。
我們把這個映射到我們代碼中,當我們的線程發生一次 RPC 調用或者 HTTP 調用,又或者其他的一些耗時的 IO 調用。
發起之后,如果是同步阻塞,我們的這個線程就會被阻塞掛起,直到結果返回,試想一下,如果 IO 調用很頻繁那我們的 CPU 使用率會很低很低。
正所謂是物盡其用,既然 CPU 的使用率被 IO 調用搞得很低,那我們就可以使用異步非阻塞。
當發生 IO 調用時我并不馬上關心結果,我只需要把回調函數寫入這次 IO 調用,這個時候線程可以繼續處理新的請求,當 IO 調用結束時,會調用回調函數。
而我們的線程始終處于忙碌之中,這樣就能做更多的有意義的事了。這里首先要說明的是,異步化不是萬能,異步化并不能縮短你整個鏈路調用時間長的問題,但是它能極大的提升你的最大 QPS。
一般我們的業務中有兩處比較耗時:
- CPU:CPU 耗時指的是我們的一般的業務處理邏輯,比如一些數據的運算,對象的序列化。這些異步化是不能解決的,得需要靠一些算法的優化,或者一些高性能框架。
- IO Wait:IO 耗時就像我們上面說的,一般發生在網絡調用,文件傳輸中等等,這個時候線程一般會掛起阻塞。而我們的異步化通常用于解決這部分的問題。
哪些可以異步化
上面說了異步化是用于解決 IO 阻塞的問題,而我們一般項目中可以使用異步化的情況如下:
- Servlet 異步化
- Spring MVC 異步化
- RPC 調用如(Dubbo,Thrift),HTTP 調用異步化
- 數據庫調用,緩存調用異步化
下面我會從上面幾個方面進行異步化的介紹。
Servlet 異步化
對于 Java 開發程序員來說 Servlet 并不陌生,在項目中不論你使用 Struts2,還是使用的 Spring MVC,本質上都是封裝的 Servlet。
但是我們一般的開發都是使用的同步阻塞,模式如下:
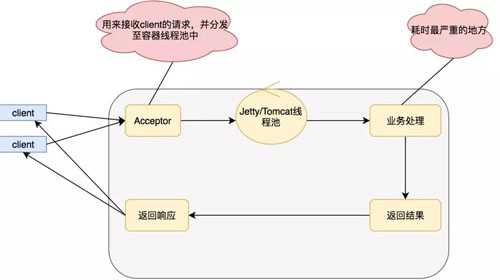
上面的模式優點在于編碼簡單,適合在項目啟動初期,訪問量較少,或者是 CPU 運算較多的項目。
缺點在于,業務邏輯線程和 Servlet 容器線程是同一個,一般的業務邏輯總得發生點 IO,比如查詢數據庫,比如產生 RPC 調用,這個時候就會發生阻塞。
而我們的 Servlet 容器線程肯定是有限的,當 Servlet 容器線程都被阻塞的時候我們的服務這個時候就會發生拒絕訪問,線程不夠我當然可以通過增加機器的一系列手段來解決這個問題。
但是俗話說得好靠人不如靠自己,靠別人替我分擔請求,還不如我自己搞定。
所以在 Servlet 3.0 之后支持了異步化,我們采用異步化之后,模式變成如下:
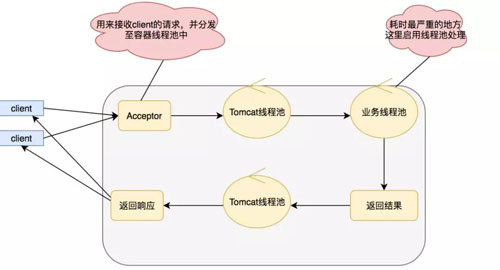
在這里我們采用新的線程處理業務邏輯,IO 調用的阻塞就不會影響我們的 Serlvet 了,實現異步 Serlvet 的代碼也比較簡單,如下:
- @WebServlet(name = "WorkServlet",urlPatterns = "/work",asyncSupported =true)
- public class WorkServlet extends HttpServlet{
- private static final long serialVersionUID = 1L;
- @Override
- protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
- this.doPost(req, resp);
- }
- @Override
- protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
- //設置ContentType,關閉緩存
- resp.setContentType("text/plain;charset=UTF-8");
- resp.setHeader("Cache-Control","private");
- resp.setHeader("Pragma","no-cache");
- final PrintWriter writer= resp.getWriter();
- writer.println("老師檢查作業了");
- writer.flush();
- List<String> zuoyes=new ArrayList<String>();
- for (int i = 0; i < 10; i++) {
- zuoyes.add("zuoye"+i);;
- }
- //開啟異步請求
- final AsyncContext ac=req.startAsync();
- doZuoye(ac, zuoyes);
- writer.println("老師布置作業");
- writer.flush();
- }
- private void doZuoye(final AsyncContext ac, final List<String> zuoyes) {
- ac.setTimeout(1*60*60*1000L);
- ac.start(new Runnable() {
- @Override
- public void run() {
- //通過response獲得字符輸出流
- try {
- PrintWriter writer=ac.getResponse().getWriter();
- for (String zuoye:zuoyes) {
- writer.println("\""+zuoye+"\"請求處理中");
- Thread.sleep(1*1000L);
- writer.flush();
- }
- ac.complete();
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- });
- }
- }
實現 Serlvet 的關鍵在于 HTTP 采取了長連接,也就是當請求打過來的時候就算有返回也不會關閉,因為可能還會有數據,直到返回關閉指令。
AsyncContext ac=req.startAsync();用于獲取異步上下文,后續我們通過這個異步上下文進行回調返回數據,有點像我們買衣服的時候,留給老板一個電話。
而這個上下文也是一個電話,當有衣服到的時候,也就是當有數據準備好的時候就可以打電話發送數據了。ac.complete();用來進行長鏈接的關閉。
Spring MVC 異步化
現在其實很少人來進行 Serlvet 編程,都是直接采用現成的一些框架,比如 Struts2,Spring MVC。下面介紹下使用 Spring MVC 如何進行異步化:
首先確認你的項目中的 Servlet 是 3.0 以上,其次 Spring MVC 4.0+:
- <dependency>
- <groupId>javax.servlet</groupId>
- <artifactId>javax.servlet-api</artifactId>
- <version>3.1.0</version>
- <scope>provided</scope>
- </dependency>
- <dependency>
- <groupId>org.springframework</groupId>
- <artifactId>spring-webmvc</artifactId>
- <version>4.2.3.RELEASE</version>
- </dependency>
web.xml 頭部聲明,必須要 3.0,Filter 和 Serverlet 設置為異步:
- <?xml version="1.0" encoding="UTF-8"?>
- <web-app version="3.0" xmlns="http://java.sun.com/xml/ns/javaee"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
- http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd">
- <filter>
- <filter-name>testFilter</filter-name>
- <filter-class>com.TestFilter</filter-class>
- <async-supported>true</async-supported>
- </filter>
- <servlet>
- <servlet-name>mvc-dispatcher</servlet-name>
- <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
- .........
- <async-supported>true</async-supported>
- </servlet>
使用 Spring MVC 封裝了 Servlet 的 AsyncContext,使用起來比較簡單。以前我們同步的模式的 Controller 是返回 ModelAndView。
而異步模式直接生成一個 DeferredResult(支持我們超時擴展)即可保存上下文,下面給出如何和我們 HttpClient 搭配的簡單 demo:
- @RequestMapping(value="/asynctask", method = RequestMethod.GET)
- public DeferredResult<String> asyncTask() throws IOReactorException {
- IOReactorConfig ioReactorConfig = IOReactorConfig.custom().setIoThreadCount(1).build();
- ConnectingIOReactor ioReactor = new DefaultConnectingIOReactor(ioReactorConfig);
- PoolingNHttpClientConnectionManager conManager = new PoolingNHttpClientConnectionManager(ioReactor);
- conManager.setMaxTotal(100);
- conManager.setDefaultMaxPerRoute(100);
- CloseableHttpAsyncClient httpclient = HttpAsyncClients.custom().setConnectionManager(conManager).build();
- // Start the client
- httpclient.start();
- //設置超時時間200ms
- final DeferredResult<String> deferredResult = new DeferredResult<String>(200L);
- deferredResult.onTimeout(new Runnable() {
- @Override
- public void run() {
- System.out.println("異步調用執行超時!thread id is : " + Thread.currentThread().getId());
- deferredResult.setResult("超時了");
- }
- });
- System.out.println("/asynctask 調用!thread id is : " + Thread.currentThread().getId());
- final HttpGet request2 = new HttpGet("http://www.apache.org/");
- httpclient.execute(request2, new FutureCallback<HttpResponse>() {
- public void completed(final HttpResponse response2) {
- System.out.println(request2.getRequestLine() + "->" + response2.getStatusLine());
- deferredResult.setResult(request2.getRequestLine() + "->" + response2.getStatusLine());
- }
- public void failed(final Exception ex) {
- System.out.println(request2.getRequestLine() + "->" + ex);
- }
- public void cancelled() {
- System.out.println(request2.getRequestLine() + " cancelled");
- }
- });
- return deferredResult;
- }
注意:在 Serlvet 異步化中有個問題是 Filter 的后置結果處理,沒法使用,對于我們一些打點,結果統計直接使用 Serlvet 異步是沒法用的。
在 Spring MVC 中就很好的解決了這個問題,Spring MVC 采用了一個比較取巧的方式通過請求轉發,能讓請求再次通過過濾器。
但是又引入了新的一個問題那就是過濾器會處理兩次,這里可以通過 Spring MVC 源碼中自身判斷的方法。
我們可以在 Filter 中使用下面這句話來進行判斷是不是屬于 Spring MVC 轉發過來的請求,從而不處理 Filter 的前置事件,只處理后置事件:
- Object asyncManagerAttr = servletRequest.getAttribute(WEB_ASYNC_MANAGER_ATTRIBUTE);
- return asyncManagerAttr instanceof WebAsyncManager ;
全鏈路異步化
上面我們介紹了 Serlvet 的異步化,相信細心的同學都看出來似乎并沒有解決根本的問題,我的 IO 阻塞依然存在,只是換了個位置而已。
當 IO 調用頻繁同樣會讓業務線程池快速變滿,雖然 Serlvet 容器線程不被阻塞,但是這個業務依然會變得不可用。
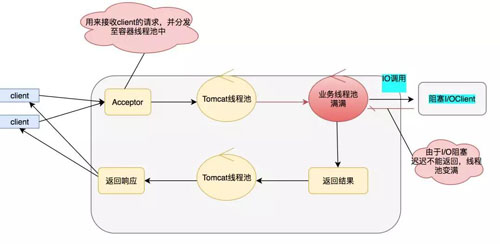
那么怎么才能解決上面的問題呢?答案就是全鏈路異步化,全鏈路異步追求的是沒有阻塞,打滿你的 CPU,把機器的性能壓榨到極致。模型圖如下:
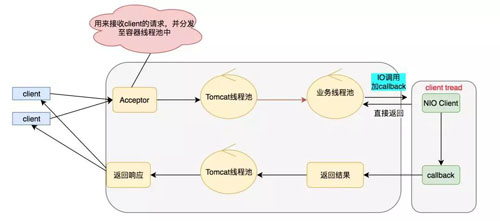
具體的 NIO Client 到底做了什么事呢,具體如下面模型:
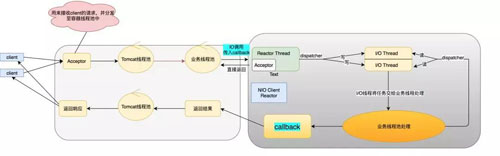
上面就是我們全鏈路異步的圖了(部分線程池可以優化)。全鏈路的核心在于只要我們遇到 IO 調用的時候,我們就可以使用 NIO,從而避免阻塞,也就解決了之前說的業務線程池被打滿的尷尬場景。
遠程調用異步化
我們一般遠程調用使用 RPC 或者 HTTP:
- 對于 RPC 來說,一般 Thrift,HTTP,Motan 等支持都異步調用,其內部原理也都是采用事件驅動的 NIO 模型。
- 對于 HTTP 來說,一般的 Apache HTTP Client 和 Okhttp 也都提供了異步調用。
下面簡單介紹下 HTTP 異步化調用是怎么做的。首先來看一個例子:
- public class HTTPAsyncClientDemo {
- public static void main(String[] args) throws ExecutionException, InterruptedException, IOReactorException {
- //具體參數含義下文會講
- //apache提供了ioReactor的參數配置,這里我們配置IO 線程為1
- IOReactorConfig ioReactorConfig = IOReactorConfig.custom().setIoThreadCount(1).build();
- //根據這個配置創建一個ioReactor
- ConnectingIOReactor ioReactor = new DefaultConnectingIOReactor(ioReactorConfig);
- //asyncHttpClient使用PoolingNHttpClientConnectionManager管理我們客戶端連接
- PoolingNHttpClientConnectionManager conManager = new PoolingNHttpClientConnectionManager(ioReactor);
- //設置總共的連接的最大數量
- conManager.setMaxTotal(100);
- //設置每個路由的連接的最大數量
- conManager.setDefaultMaxPerRoute(100);
- //創建一個Client
- CloseableHttpAsyncClient httpclient = HttpAsyncClients.custom().setConnectionManager(conManager).build();
- // Start the client
- httpclient.start();
- // Execute request
- final HttpGet request1 = new HttpGet("http://www.apache.org/");
- Future<HttpResponse> future = httpclient.execute(request1, null);
- // and wait until a response is received
- HttpResponse response1 = future.get();
- System.out.println(request1.getRequestLine() + "->" + response1.getStatusLine());
- // One most likely would want to use a callback for operation result
- final HttpGet request2 = new HttpGet("http://www.apache.org/");
- httpclient.execute(request2, new FutureCallback<HttpResponse>() {
- //Complete成功后會回調這個方法
- public void completed(final HttpResponse response2) {
- System.out.println(request2.getRequestLine() + "->" + response2.getStatusLine());
- }
- public void failed(final Exception ex) {
- System.out.println(request2.getRequestLine() + "->" + ex);
- }
- public void cancelled() {
- System.out.println(request2.getRequestLine() + " cancelled");
- }
- });
- }
- }
下面給出 httpAsync 的整個類圖:
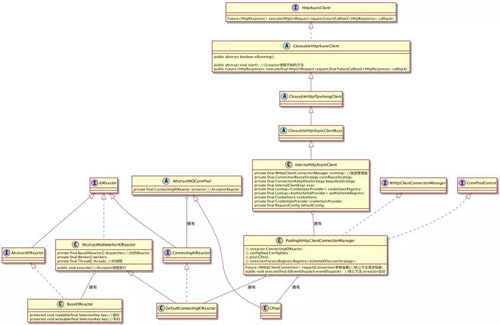
對于我們的 HTTPAysncClient 最后使用的是 InternalHttpAsyncClient,在 InternalHttpAsyncClient 中有個 ConnectionManager,這個就是我們管理連接的管理器。
而在 httpAsync 中只有一個實現那就是 PoolingNHttpClientConnectionManager。
這個連接管理器中有兩個我們比較關心的,一個是 Reactor,一個是 Cpool:
- Reactor:所有的 Reactor 這里都是實現了 IOReactor 接口。在 PoolingNHttpClientConnectionManager 中會有擁有一個 Reactor,那就是 DefaultConnectingIOReactor,這個 DefaultConnectingIOReactor,負責處理 Acceptor。
在 DefaultConnectingIOReactor 有個 excutor 方法,生成 IOReactor 也就是我們圖中的 BaseIOReactor,進行 IO 的操作。這個模型就是我們上面的 1.2.2 的模型。
- CPool:在 PoolingNHttpClientConnectionManager 中有個 CPool,主要是負責控制我們連接,我們上面所說的 maxTotal 和 defaultMaxPerRoute,都是由其進行控制。
如果每個路由有滿了,它會斷開最老的一個鏈接;如果總共的 total 滿了,它會放入 leased 隊列,釋放空間的時候就會將其重新連接。
數據庫調用異步化
對于數據庫調用一般的框架并沒有提供異步化的方法,這里推薦自己封裝或者使用網上開源的。
異步化并不是高并發的銀彈,但是有了異步化的確能提高你機器的 QPS,吞吐量等等。
上述講的一些模型如果能合理的做一些優化,然后進行應用,相信能對你的服務有很大的幫助。
高并發大殺器:并行化
想必熱愛游戲的同學小時候都幻想過要是自己會分身之術,就能一邊打游戲一邊上課了。
可惜現實中并沒有這個技術,你要么只有老老實實的上課,要么就只有逃課去打游戲了。
雖然在現實中我們無法實現分身這樣的技術,但是我們可以在計算機世界中實現這樣的愿望。
計算機中的分身術
計算機中的分身術不是天生就有了。在 1971 年,英特爾推出的全球第一顆通用型微處理器 4004,由 2300 個晶體管構成。
當時,公司的聯合創始人之一戈登摩爾就提出大名鼎鼎的“摩爾定律”——每過 18 個月,芯片上可以集成的晶體管數目將增加一倍。
最初的主頻 740KHz(每秒運行 74 萬次),現在過了快 50 年了,大家去買電腦的時候會發現現在的主頻都能達到 4.0GHZ了(每秒 40 億次)。
但是主頻越高帶來的收益卻是越來越小:
- 據測算,主頻每增加 1G,功耗將上升 25 瓦,而在芯片功耗超過 150 瓦后,現有的風冷散熱系統將無法滿足散熱的需要。有部分 CPU 都可以用來煎雞蛋了。
- 流水線過長,使得單位頻率效能低下,越大的主頻其實整體性能反而不如小的主頻。
- 戈登摩爾認為摩爾定律未來 10-20 年會失效。
在單核主頻遇到瓶頸的情況下,多核 CPU 應運而生,不僅提升了性能,并且降低了功耗。
所以多核 CPU 逐漸成為現在市場的主流,這樣讓我們的多線程編程也更加的容易。
說到了多核 CPU 就一定要說 GPU,大家可能對這個比較陌生,但是一說到顯卡就肯定不陌生,筆者搞過一段時間的 CUDA 編程,我才意識到這個才是真正的并行計算。
大家都知道圖片像素點吧,比如 1920*1080 的圖片有 210 萬個像素點,如果想要把一張圖片的每個像素點都進行轉換一下,那在我們 Java 里面可能就要循環遍歷 210 萬次。
就算我們用多線程 8 核 CPU,那也得循環幾十萬次。但是如果使用 Cuda,最多可以 365535*512 = 100661760(一億)個線程并行執行,就這種級別的圖片那也是馬上處理完成。
但是 Cuda 一般適合于圖片這種,有大量的像素點需要同時處理,但是指令集很少所以邏輯不能太復雜。
應用中的并行
一說起讓你的服務高性能的手段,那么異步化,并行化這些肯定會第一時間在你腦海中顯現出來,并行化可以用來配合異步化,也可以用來單獨做優化。
我們可以想想有這么一個需求,在你下外賣訂單的時候,這筆訂單可能還需要查用戶信息,折扣信息,商家信息,菜品信息等。
用同步的方式調用,如下圖所示:
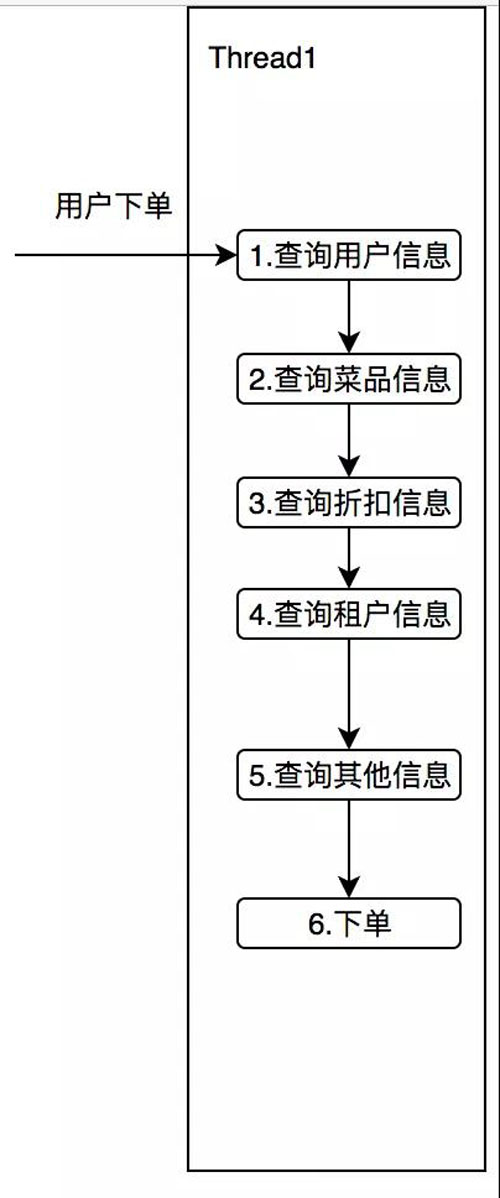
設想一下這 5 個查詢服務,平均每次消耗 50ms,那么本次調用至少是 250ms,我們細想一下,這五個服務其實并沒有任何的依賴,誰先獲取誰后獲取都可以。
那么我們可以想想,是否可以用多重影分身之術,同時獲取這五個服務的信息呢?
優化如下:
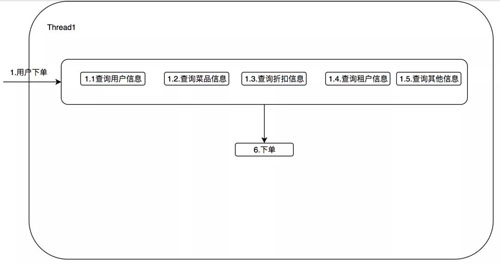
將這五個查詢服務并行查詢,在理想情況下可以優化至 50ms。當然說起來簡單,我們真正如何落地呢?
CountDownLatch/Phaser
CountDownLatch 和 Phaser 是 JDK 提供的同步工具類。Phaser 是 1.7 版本之后提供的工具類。而 CountDownLatch 是 1.5 版本之后提供的工具類。
這里簡單介紹一下 CountDownLatch,可以將其看成是一個計數器,await()方法可以阻塞至超時或者計數器減至 0,其他線程當完成自己目標的時候可以減少 1,利用這個機制我們可以用來做并發。
可以用如下的代碼實現我們上面的下訂單的需求:
- public class CountDownTask {
- private static final int CORE_POOL_SIZE = 4;
- private static final int MAX_POOL_SIZE = 12;
- private static final long KEEP_ALIVE_TIME = 5L;
- private final static int QUEUE_SIZE = 1600;
- protected final static ExecutorService THREAD_POOL = new ThreadPoolExecutor(CORE_POOL_SIZE, MAX_POOL_SIZE,
- KEEP_ALIVE_TIME, TimeUnit.SECONDS, new LinkedBlockingQueue<>(QUEUE_SIZE));
- public static void main(String[] args) throws InterruptedException {
- // 新建一個為5的計數器
- CountDownLatch countDownLatch = new CountDownLatch(5);
- OrderInfo orderInfo = new OrderInfo();
- THREAD_POOL.execute(() -> {
- System.out.println("當前任務Customer,線程名字為:" + Thread.currentThread().getName());
- orderInfo.setCustomerInfo(new CustomerInfo());
- countDownLatch.countDown();
- });
- THREAD_POOL.execute(() -> {
- System.out.println("當前任務Discount,線程名字為:" + Thread.currentThread().getName());
- orderInfo.setDiscountInfo(new DiscountInfo());
- countDownLatch.countDown();
- });
- THREAD_POOL.execute(() -> {
- System.out.println("當前任務Food,線程名字為:" + Thread.currentThread().getName());
- orderInfo.setFoodListInfo(new FoodListInfo());
- countDownLatch.countDown();
- });
- THREAD_POOL.execute(() -> {
- System.out.println("當前任務Tenant,線程名字為:" + Thread.currentThread().getName());
- orderInfo.setTenantInfo(new TenantInfo());
- countDownLatch.countDown();
- });
- THREAD_POOL.execute(() -> {
- System.out.println("當前任務OtherInfo,線程名字為:" + Thread.currentThread().getName());
- orderInfo.setOtherInfo(new OtherInfo());
- countDownLatch.countDown();
- });
- countDownLatch.await(1, TimeUnit.SECONDS);
- System.out.println("主線程:"+ Thread.currentThread().getName());
- }
- }
建立一個線程池(具體配置根據具體業務,具體機器配置),進行并發的執行我們的任務(生成用戶信息,菜品信息等),最后利用 await 方法阻塞等待結果成功返回。
CompletableFuture
相信各位同學已經發現,CountDownLatch 雖然能實現我們需要滿足的功能但是其仍然有個問題是,我們的業務代碼需要耦合 CountDownLatch 的代碼。
比如在我們獲取用戶信息之后,我們會執行 countDownLatch.countDown(),很明顯我們的業務代碼顯然不應該關心這一部分邏輯,并且在開發的過程中萬一寫漏了,那我們的 await 方法將只會被各種異常喚醒。
所以在 JDK 1.8 中提供了一個類 CompletableFuture,它是一個多功能的非阻塞的 Future。(什么是 Future:用來代表異步結果,并且提供了檢查計算完成,等待完成,檢索結果完成等方法。)
我們將每個任務的計算完成的結果都用 CompletableFuture 來表示,利用 CompletableFuture.allOf 匯聚成一個大的 CompletableFuture,那么利用 get()方法就可以阻塞。
- public class CompletableFutureParallel {
- private static final int CORE_POOL_SIZE = 4;
- private static final int MAX_POOL_SIZE = 12;
- private static final long KEEP_ALIVE_TIME = 5L;
- private final static int QUEUE_SIZE = 1600;
- protected final static ExecutorService THREAD_POOL = new ThreadPoolExecutor(CORE_POOL_SIZE, MAX_POOL_SIZE,
- KEEP_ALIVE_TIME, TimeUnit.SECONDS, new LinkedBlockingQueue<>(QUEUE_SIZE));
- public static void main(String[] args) throws InterruptedException, ExecutionException, TimeoutException {
- OrderInfo orderInfo = new OrderInfo();
- //CompletableFuture 的List
- List<CompletableFuture> futures = new ArrayList<>();
- futures.add(CompletableFuture.runAsync(() -> {
- System.out.println("當前任務Customer,線程名字為:" + Thread.currentThread().getName());
- orderInfo.setCustomerInfo(new CustomerInfo());
- }, THREAD_POOL));
- futures.add(CompletableFuture.runAsync(() -> {
- System.out.println("當前任務Discount,線程名字為:" + Thread.currentThread().getName());
- orderInfo.setDiscountInfo(new DiscountInfo());
- }, THREAD_POOL));
- futures.add( CompletableFuture.runAsync(() -> {
- System.out.println("當前任務Food,線程名字為:" + Thread.currentThread().getName());
- orderInfo.setFoodListInfo(new FoodListInfo());
- }, THREAD_POOL));
- futures.add(CompletableFuture.runAsync(() -> {
- System.out.println("當前任務Other,線程名字為:" + Thread.currentThread().getName());
- orderInfo.setOtherInfo(new OtherInfo());
- }, THREAD_POOL));
- CompletableFuture allDoneFuture = CompletableFuture.allOf(futures.toArray(new CompletableFuture[futures.size()]));
- allDoneFuture.get(10, TimeUnit.SECONDS);
- System.out.println(orderInfo);
- }
- }
可以看見我們使用 CompletableFuture 能很快的完成需求,當然這還不夠。
Fork/Join
我們上面用 CompletableFuture 完成了對多組任務并行執行,但是它依然是依賴我們的線程池。
在我們的線程池中使用的是阻塞隊列,也就是當我們某個線程執行完任務的時候需要通過這個阻塞隊列進行,那么肯定會發生競爭,所以在 JDK 1.7 中提供了 ForkJoinTask 和 ForkJoinPool。
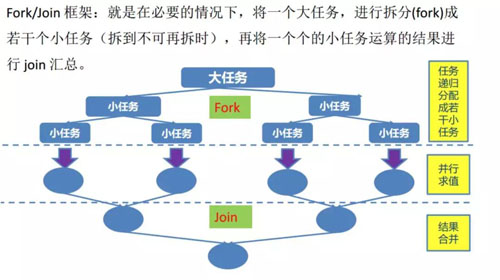
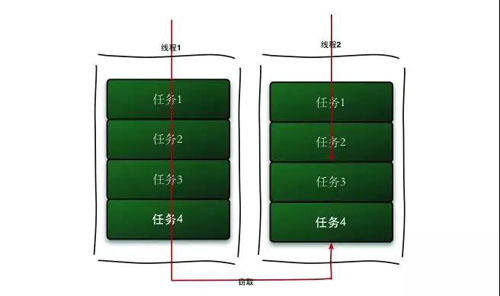
ForkJoinPool 中每個線程都有自己的工作隊列,并且采用 Work-Steal 算法防止線程饑餓。
Worker 線程用 LIFO 的方法取出任務,但是會用 FIFO 的方法去偷取別人隊列的任務,這樣就減少了鎖的沖突。
網上這個框架的例子很多,我們看看如何使用代碼完成我們上面的下訂單需求:
- public class OrderTask extends RecursiveTask<OrderInfo> {
- @Override
- protected OrderInfo compute() {
- System.out.println("執行"+ this.getClass().getSimpleName() + "線程名字為:" + Thread.currentThread().getName());
- // 定義其他五種并行TasK
- CustomerTask customerTask = new CustomerTask();
- TenantTask tenantTask = new TenantTask();
- DiscountTask discountTask = new DiscountTask();
- FoodTask foodTask = new FoodTask();
- OtherTask otherTask = new OtherTask();
- invokeAll(customerTask, tenantTask, discountTask, foodTask, otherTask);
- OrderInfo orderInfo = new OrderInfo(customerTask.join(), tenantTask.join(), discountTask.join(), foodTask.join(), otherTask.join());
- return orderInfo;
- }
- public static void main(String[] args) {
- ForkJoinPool forkJoinPool = new ForkJoinPool(Runtime.getRuntime().availableProcessors() -1 );
- System.out.println(forkJoinPool.invoke(new OrderTask()));
- }
- }
- class CustomerTask extends RecursiveTask<CustomerInfo>{
- @Override
- protected CustomerInfo compute() {
- System.out.println("執行"+ this.getClass().getSimpleName() + "線程名字為:" + Thread.currentThread().getName());
- return new CustomerInfo();
- }
- }
- class TenantTask extends RecursiveTask<TenantInfo>{
- @Override
- protected TenantInfo compute() {
- System.out.println("執行"+ this.getClass().getSimpleName() + "線程名字為:" + Thread.currentThread().getName());
- return new TenantInfo();
- }
- }
- class DiscountTask extends RecursiveTask<DiscountInfo>{
- @Override
- protected DiscountInfo compute() {
- System.out.println("執行"+ this.getClass().getSimpleName() + "線程名字為:" + Thread.currentThread().getName());
- return new DiscountInfo();
- }
- }
- class FoodTask extends RecursiveTask<FoodListInfo>{
- @Override
- protected FoodListInfo compute() {
- System.out.println("執行"+ this.getClass().getSimpleName() + "線程名字為:" + Thread.currentThread().getName());
- return new FoodListInfo();
- }
- }
- class OtherTask extends RecursiveTask<OtherInfo>{
- @Override
- protected OtherInfo compute() {
- System.out.println("執行"+ this.getClass().getSimpleName() + "線程名字為:" + Thread.currentThread().getName());
- return new OtherInfo();
- }
- }
我們定義一個 Order Task 并且定義五個獲取信息的任務,在 Compute 中分別 Fork 執行這五個任務,最后在將這五個任務的結果通過 Join 獲得,最后完成我們的并行化的需求。
parallelStream
在 JDK 1.8 中提供了并行流的 API,當我們使用集合的時候能很好的進行并行處理。
下面舉了一個簡單的例子從 1 加到 100:
- public class ParallelStream {
- public static void main(String[] args) {
- ArrayList<Integer> list = new ArrayList<Integer>();
- for (int i = 1; i <= 100; i++) {
- list.add(i);
- }
- LongAdder sum = new LongAdder();
- list.parallelStream().forEach(integer -> {
- // System.out.println("當前線程" + Thread.currentThread().getName());
- sum.add(integer);
- });
- System.out.println(sum);
- }
- }
parallelStream 中底層使用的那一套也是 Fork/Join 的那一套,默認的并發程度是可用 CPU 數 -1。
分片
可以想象有這么一個需求,每天定時對 ID 在某個范圍之間的用戶發券,比如這個范圍之間的用戶有幾百萬,如果給一臺機器發的話,可能全部發完需要很久的時間。
所以分布式調度框架比如:elastic-job 都提供了分片的功能,比如你用 50 臺機器,那么 id%50 = 0 的在第 0 臺機器上;=1 的在第 1 臺機器上發券,那么我們的執行時間其實就分攤到了不同的機器上了。
并行化注意事項
線程安全:在 parallelStream 中我們列舉的代碼中使用的是 LongAdder,并沒有直接使用我們的 Integer 和 Long,這個是因為在多線程環境下 Integer 和 Long 線程不安全。所以線程安全我們需要特別注意。
合理參數配置:可以看見我們需要配置的參數比較多,比如我們的線程池的大小,等待隊列大小,并行度大小以及我們的等待超時時間等等。
我們都需要根據自己的業務不斷的調優防止出現隊列不夠用或者超時時間不合理等等。
上面介紹了什么是并行化,并行化的各種歷史,在 Java 中如何實現并行化,以及并行化的注意事項。希望大家對并行化有個比較全面的認識。
最后給大家提個兩個小問題:
- 在我們并行化當中有某個任務如果某個任務出現了異常應該怎么辦?
- 在我們并行化當中有某個任務的信息并不是強依賴,也就是如果出現了問題這部分信息我們也可以不需要,當并行化的時候,這種任務出現了異常應該怎么辦?