













資深大牛吐血總結:如何成為一名合格的云架構師?
云架構師負責管理一個組織中的云計算架構,特別是隨著云技術日益復雜化。云計算架構涵蓋了與云計算相關的一切,包括管理云存儲所需的前端平臺、服務器、存儲、交付和網絡。
本文作者從如下幾個方面全面剖析云架構師的進階攻略:
- 架構的三個維度和六個層面
- 了解云計算的歷史演進與基本原理
- 開源軟件是進階的利器
- 了解 Linux 基礎知識
- 了解數據中心和網絡基礎知識
- 基于 KVM 了解計算虛擬化
- 基于 Openvswitch 了解網絡虛擬化
- 基于 OpenStack 了解云平臺
- 基于 Mesos 和 Kubernetes 了解容器平臺
- 基于 Hadoop 和 Spark 了解大數據平臺
- 基于 Lucene 和 ElasticSearch 了解搜索引擎
- 基于 Spring Cloud 了解微服務
架構的三個維度和六個層面
三個維度

在互聯網時代,要做好一個合格的云架構師,需要熟悉三大架構。
IT 架構
IT 架構其實就是計算,網絡,存儲。這是云架構師的基本功,也是最傳統的云架構師應該首先掌握的部分。
良好設計的 IT 架構,可以降低 CAPEX 和 OPEX,減輕運維的負擔。數據中心,虛擬化,云平臺,容器平臺都屬于 IT 架構的范疇。
應用架構
隨著應用從傳統應用向互聯網應用轉型,僅僅搞定資源層面的彈性還不夠,常常會出現創建了大批機器,仍然撐不住高并發流量。因而基于微服務的互聯網架構,越來越成為云架構師所必需的技能。
良好設計的應用架構,可以實現快速迭代和高并發。數據庫,緩存,消息隊列等 PaaS,以及基于 Spring Cloud 和 Dubbo 的微服務框架,都屬于應用架構的范疇。
數據架構
數據成為人工智能時代的核心資產,在做互聯網化轉型的同時,往往進行的也是數字化轉型,并有戰略的進行數據收集,這就需要云架構師同時有大數據思維。
有意識的建設統一的數據平臺,并給予數據進行數字化運營。搜索引擎,Hadoop,Spark,人工智能都屬于數據架構的范疇。
六個層面

上面的三個維度是從人的角度出發的,如果從系統的角度出發,架構分六個層次。
基礎設施層
在數據中心里面,會有大量的機架,大量的服務器,并通過交換機和路由器將服務器連接起來,有的應用例如 Oracle 是需要部署在物理機上的。
為了管理的方便,在物理機之上會部署虛擬化,例如 Vmware,可以將對于物理機復雜的運維簡化為虛擬機靈活的運維。
虛擬化采取的運維方式多是由運維部門統一管理,當一個公司里面部門非常多的時候,往往要引入良好的租戶管理。
基于 Quota 和 QoS 的資源控制,基于 VPC 的網絡規劃等,實現從運維集中管理到租戶自助使用模式的轉換,托生于公有云的 OpenStack 在這方面做的是比較好的。
隨著應用架構越來越重要,對于標準化交付和彈性伸縮的需求越來越大,容器做為軟件交付的集裝箱,可以實現基于鏡像的跨環境遷移,Kubernetes 是容器管理平臺的事實標準。
數據層
數據層,也即一個應用的中軍大營,如果是傳統應用,可能會使用 Oracle,并使用大量的存儲過程,有大量的表聯合查詢,成本也往往比較高。
但是對于高并發的互聯網應用,需要進行微服務的拆分,數據庫實例會比較多,使用開源的 MySQL 是常見的選擇。
大量的存儲過程和聯合查詢往往會使得微服務無法拆分,性能會比較差,因而需要放到應用層去做復雜的業務邏輯,而且數據庫表和索引的設計非常重要。
當并發量比較大的時候,需要實現橫向擴展,就需要基于分布式數據庫,也是需要基于單庫良好的表和索引設計。
對于結構比較靈活的數據,可以使用 MongoDB 數據庫,橫向擴展能力比較好。
對于大量的聯合查詢需求,可以使用 ElasticSearch 之類的搜索引擎來做,速度快,更加靈活。
中間件層
因為數據庫層往往需要保證數據的不丟失以及一些事務,因而并發性能不可能非常大。
所以我們經常說,數據庫是中軍大營,不能所有的請求都到這里來,因而需要一層緩存層,用來攔截大部分的熱點請求。
Memcached 適合做簡單的 key-value 存儲,內存使用率比較高,而且由于是多核處理,對于比較大的數據,性能較好。
但是缺點也比較明顯,Memcached 嚴格來講沒有集群機制,橫向擴展完全靠客戶端來實現。
另外 Memcached 無法持久化,一旦掛了數據就都丟失了,如果想實現高可用,也是需要客戶端進行雙寫才可以。
Redis 的數據結構比較豐富,提供持久化的功能,提供成熟的主備同步,故障切換的功能,從而保證了高可用性。
另外微服務拆分以后,有時候處理一個訂單要經過非常多的服務,處理過程會比較慢,這個時候需要使用消息隊列,讓服務之間的調用變成對于消息的訂閱,實現異步處理。
RabbitMQ 和 Kafka 是常用的消息隊列,當事件比較重要的時候,會結合數據庫實現可靠消息隊列。
基礎服務層
有的時候成為中臺層,將通用的能力抽象為服務對外提供原子化接口。
這樣上層可以根據業務需求,通過靈活的組合這些原子化接口,靈活的應對業務需求的變化,實現能力的復用,以及數據的統一管理,例如用戶數據,支付數據,不會分散到各個應用中。
另外基礎服務層稱為應用、數據庫和緩存的一個分界線,不應該所有的應用都直接連數據庫,一旦出現分庫分表,數據庫遷移,緩存選型改變等,影響面會非常大,幾乎無法執行。
如果將這些底層的變更攔截在基礎服務層,上層僅僅使用基礎服務層的接口,這樣底層的變化會對上層透明,可以逐步演進。
業務服務層或者組合服務層
大部分的業務邏輯都是在這個層面實現,業務邏輯比較面向用戶,因而會經常改變,所以需要組合基礎服務的接口進行實現。
在這一層,會經常進行服務的拆分,實現開發獨立,上線獨立,擴容獨立,容災降級獨立。
微服務的拆分不應該是一個運動,而應該是一個遇到耦合痛點的時候,不斷解決,不斷演進的一個過程。
微服務拆分之后,有時候需要通過分布式事務,保證多個操作的原子性,也是在組合服務層來實現的。
用戶接口層
用戶接口層,也即對終端客戶呈現出來的界面和 App,但是卻不僅僅是界面這么簡單。
這一層有時候稱為接入層。在這一層,動態資源和靜態資源應該分離,靜態資源應該在接入層做緩存,使用 CDN 進行緩存。
也應該 UI 和 API 分離,界面應該通過組合 API 進行數據拼裝。API 會通過統一的 API 網關進行統一的管理和治理。
一方面后端組合服務層的拆分對 APP 是透明的;另一方面當并發量比較大的時候,可以在這一層實現限流和降級。
為了支撐這六個層次,在上圖的左側是一些公共能力:
- 持續集成和持續發布是保證微服務拆分過程中的快速迭代,以及變更后保證功能不變的,不引入新的 Bug。
- 服務發現和服務治理是微服務之間互相的調用,以及調用過程中出現異常情況下的熔斷,限流,降級策略。
- 大數據和人工智能是通過收集各個層面的數據,例如用戶訪問數據,用戶下單數據,客服詢問數據等,結合統一的中臺,對數據進行分析,實現智能推薦。
- 監控與 APM 是基礎設施的監控和應用的監控,發現資源層面的問題以及應用調用的問題。
作為一個云架構師還是很復雜的,千里之行,始于足下,讓我們慢慢來。
了解云計算的歷史演進與基本原理
在一頭扎進云計算的汪洋大海之前,我們應該先有一個全貌的了解,有人說了解一個知識的起點,就是了解它的歷史,也就是知道它是如何一步一步到今天的,這樣如此龐大的一個體系,其實是逐步加進來的。
這樣的知識體系對我們來說,就不是一個冷冰冰的知識網,而是一個有血有肉的人,我們只要沿著演進的線索,一步一步摸清楚“它”的脾氣就可以了。
如何把云計算講的通俗易懂,我本人思考了半天,最終寫下了下面這篇文章:終于有人把云計算、大數據和人工智能講明白了!在這里,我把核心的要點在這里寫一下。
第一:云計算的本質是實現從資源到架構的全面彈性。
所謂的彈性就是時間靈活性和空間靈活性,也即想什么時候要就什么時候要,想要多少就要多少。
資源層面的彈性也即實現計算、網絡、存儲資源的彈性。這個過程經歷了從物理機,到虛擬化,到云計算的一個演進過程。

架構層面的彈性也即實現通用應用和自有應用的彈性擴展。對于通用的應用,多集成為 PaaS 平臺。
對于自己的應用,通過基于腳本的 Puppet、Chef、Ansible 到基于容器鏡像的容器平臺 CaaS。

第二:大數據包含數據的收集,數據的傳輸,數據的存儲,數據的處理和分析,數據的檢索和挖掘等幾個過程。

當數據量很小時,很少的幾臺機器就能解決。慢慢的,當數據量越來越大,最牛的服務器都解決不了問題時,怎么辦呢?
這時就要聚合多臺機器的力量,大家齊心協力一起把這個事搞定,眾人拾柴火焰高。
第三:人工智能經歷了基于專家系統的計劃經濟,基于統計的宏觀調控,基于神經網絡的微觀經濟學三個階段。

開源軟件是進階的利器
架構師除了要掌握大的架構和理論之外,指導落地也是必備的技能,所謂既要懂設計模式,也要懂代碼。那從哪里去學習這些良好的,有借鑒意義的,可以落地的架構實踐呢?
這個世界上還是有很多有情懷的大牛的,尤其是程序員里面,他們喜歡做一件什么事情呢?答案是開源。很多軟件都是有閉源就有開源,源就是源代碼。
當某個軟件做的好,所有人都愛用,這個軟件的代碼呢,我封閉起來只有我公司知道,其他人不知道,如果其他人想用這個軟件,就要付我錢,這就叫閉源。但是世界上總有一些大牛看不慣錢都讓一家賺了去。
大牛們覺得,這個技術你會我也會,你能開發出來,我也能,我開發出來就是不收錢,把代碼拿出來分享給大家,全世界誰用都可以,所有的人都可以享受到好處,這個叫做開源。
非常建議大家了解,深入研究,甚至參與貢獻開源軟件,因為收益匪淺。
第一:通過開源軟件,我們可以了解大牛們的架構原則,設計模式。
其實咱們平時的工作中,是很難碰到大牛的,他可能是你渴望而不可及的公司的員工,甚至在國外,你要想進這種公司,不刷個幾年題目,面試個 N 輪是進不去的。
即便進去了,他可能是公司的高層,每天很忙,不怎么見得到他,就算當面討教,時間也不會很長,很難深入交流。
也有的大牛會選擇自主創業,或者是自由職業者,神龍見首不見尾,到了大公司都見不到。
但是感謝互聯網和開源社區,將大牛們拉到了我們身邊,你可以訂閱郵件組,可以加入討論群,可以看到大牛們的設計,看到很多人的評論,提問,還有大牛的回答,可以看到大牛的設計也不是一蹴而就完美的,看到逐漸演進的過程,等等。
這些都是能夠幫助我們快速提升水平的地方,有的時候,拿到一篇設計,都要查資料看半天,一開始都可能好多的術語都看不懂,沒關系肯下功夫,當你看 blueprints 越來越順暢的時候,你就進步了。
第二:通過開源軟件,我們可以學習到代碼級的落地實踐。
有時候我們能看到很多大牛寫的書和文章,也能看到很多理論的書籍,但是存在一個問題是,理論都懂,但是還是做不好架構。
這是因為沒有看到代碼,所有的理論都是空中樓閣,當你到了具體的代碼設計層面,那些學會的設計模式,無法轉化為你自己的實踐。
好在開源軟件的代碼都是公開的,凝結了大牛的心血,也能夠看到大牛在具體落地時候的取舍,一切那么真實,看得見,摸得著。
通過代碼進行學習,配合理論知識,更容易獲得第一手的經驗,并且在自己做設計和寫代碼的時候,馬上能夠映射到可以參考的場景,讓我們在做自己的系統的時候,少走彎路。
第三:通過開源軟件,我們可以加入社區,和其他技術人員在同一背景下共同進步。
大牛我們往往不容易接觸到,正面討論技術問題的時間更是難能可貴,但是沒有關系,開源軟件構建了一個社區,大家可以在一起討論。
你是怎么理解的,別人是怎么理解的,越討論越交流,越明晰,有時候和比你經驗稍微豐富一點的技術人員交流,可能比直接和大牛對話更加有直接作用。
大牛的話可能讓你消化半天,依然不知所云,大牛可能覺得很多普通人覺得的難點是顯而易見的,不屑去解釋。
但是社區里面的技術人員,可能和你一樣慢慢進步過來的,知道哪些點是當年自己困惑的,如果踩過這一個個的坑,他們一點撥,你就會豁然開朗。
而且每個人遇到的具體情況不同,從事的行業不同,客戶的需求不同,因而軟件設計的時候考慮的因素不同。
大牛是牛,但是不一定能夠遇到和你一樣的場景,但是社區里面,有你的同行業的,背景相近的技術人員,你們可以討論出符合你們特定場景的解決方案。
第四:通過開源軟件,我們作為個人,比較容易找到工作。
我們面試的時候,常常遇到的問題是,怎么能夠把在原來工作中自己的貢獻,理解,設計,技術能力展現出來。
其實我發現很多程序員不能很好的做到這一點,所以造成很多人面試很吃虧。
原因之一:背景信息不對稱。例如原來面臨的業務上很難的問題,面試官由于不理解背景,而且短時間解釋不清楚,輕視候選人的水平。
我也遇到過很多面試官才聽了幾分鐘,就會說,這不挺簡單的,你這樣這樣不就行了,然后徹底否定你們一個團隊忙了三年的事情。
原因之二:很多有能力的程序員不會表達,導致真正寫代碼的說不明白。可能原來在公司里面一個績效非常好,一個績效非常差,但是到了面試官那里就拉平了。
原因之三:新的公司不能確定你在上家公司做的工作,到這一家都能用的。例如你做的工作有 30% 是和具體業務場景相關的,70% 是通用技術,可能下家公司只會為你的通用技術部分買單。
開源軟件的好處就是,參與的人所掌握的技能都是通的,而且大家在同一個上下文里面對話,面試官和候選人之間的信息差比較少。掌握某個開源軟件有多難,不用候選人自己說,大家心里都有數。
對于很多技術能力強,但是表達能力較弱的極少數人員來講,talk is cheap,show me the code。
代碼呈上去,就能夠表現出實力來了,而且面試官也不需要根據短短的半個小時了解一個人,可以做很多背景調查。
另外由于掌握的技術是通用的,你到下一家公司,馬上就能夠上手,幾乎不需要預熱時間,對于雙方都有好處。
第五:通過開源軟件,我們作為招聘方,比較容易招到相應人員。
如果在創業公司待過的朋友會了解到創業公司招人很難,人員流失很快,而且創業公司往往對于開發進度要求很快,因為大家都在搶時間。
因而開源軟件對于招聘方來講,也是好消息。首先創業公司沒辦法像大公司一樣,弄這么多的技術大牛,自己完全落地一套自己的體系,使用開源軟件快速搭建一套平臺先上線是最好的選擇。
其次使用開源軟件,會使得招聘相對容易,市場上火的開源軟件會有大批的從業者,參與各種論壇和社區,比較容易挖到人。
最后,開源軟件的使用使得新人來了之后沒有預熱時間,來了就上手,保證開發速度。
那如何快速上手一款開源軟件呢?我總結了如下九個步驟:
- 手動安裝起來,一定要手動。
- 使用一下,推薦 XXX in Action 系列。
- 讀文檔,讀所有的官方文檔,記不住,看不懂也要讀下來。
- 了解核心的原理和算法,推薦 XXX the definitive guide 系列。
- 看一本源碼分析的書,會讓你的源碼閱讀之旅事半功倍。
- 開始閱讀核心邏輯源代碼。
- 編譯并 Debug 源代碼。
- 開發一個插件,或者對組件做少量的修改。
- 大量的運維實踐經驗和面向真實場景的定制開發。
- 所以做一個云架構師,一定不能脫離代碼,反而要不斷的擁抱開源軟件。
了解 Linux 基礎知識
作為一個云架構師,首要的一點,就是要熟悉 Linux 的基礎知識,基本原理了。
說到操作系統,一般有三個維度:
- 桌面操作系統
- 移動操作系統
- 服務器操作系統
Stack Overflow Developer Survey 2018 有這樣一個統計,對于開發人員來說,桌面操作系統的排名是 Windows,MacOS,Linux,所以大部分人平時的辦公系統都是 Windows。

當然因為辦公的原因,平時使用 Windows 的比較多,所以在學校里,很多同學接觸到的操作系統基本上都是 Windows,但是一旦從事計算機行業,就一定要跨過 Linux 這道坎。
根據今年 W3Techs 的統計,對于服務器端,Unix-Like OS 占到的比例為近 70%。所謂 Unix-Like OS 包括下圖的 Linux,BSD 等一系列。


從這個統計可以看出,隨著云計算的發展,軟件 SaaS 化,服務化,甚至微服務化,大部分的計算都是在服務端做的,因而要成為云架構師,就必須懂 Linux。
隨著移動互聯網的發展,客戶端基本上以 Android 和 iOS 為主,下圖是 Gartner 的統計。

Android 是基于 Linux 內核的。因而客戶端也進入了 Linux 陣營,很多智能終端,智能設備等開發職位,都需要懂 Linux 的人員。
學習 Linux 主要包含兩部分,一個是怎么用,一個是怎么編程,背后原理是什么。
對于怎么用,上手的話,推薦《鳥哥的 Linux 私房菜》,按著這個手冊,就能夠學會基本的 Linux 的使用,如果再深入一點,推薦《Linux 系統管理技術手冊》,磚頭厚的一本書,是 Linux 運維手邊必備。
對于怎么編程,上手的話,推薦《Unix 環境高級編程》,有代碼,有介紹,有原理,如果對內核的原理感興趣,推薦《深入理解 Linux 內核》。
Linux 的架構如下圖:

我們知道,一臺物理機上有很多的硬件,最重要的是 CPU,內存,硬盤,網絡,但是一個物理機上要跑很多的程序,這些資源應該給誰用呢?當然是大家輪著用,誰也別獨占,誰也別餓死。
為了完成這件事情,操作系統的內核就起到了大管家的作用,將硬件資源分配給不同的用戶程序使用,并且在適當的時間將資源拿回來,再分配給其他的用戶進程,這個過程稱為調度。
操作系統的功能之一:系統調用
當用戶程序想請求資源的時候,需要調用操作系統的系統調用接口,這是內核和用戶態程序的分界線。
就像你要打車,要通過打車軟件的界面,下發打車指令一樣,這樣打車軟件才會給你調度一輛車。
操作系統的功能之二:進程管理

當一個用戶進程運行的時候,內核為它分配的資源,總要有一個數據結構保存,哪些資源分配給了這個進程。分配給這個進程的資源往往包括打開的文件,內存空間等。
操作系統的功能之三:內存管理
每個進程有獨立的內存空間,內存空間是進程用來存放數據的,就像一間一間的倉庫。
為了進程使用方便,每個進程內存空間,在進程的角度來看都是獨立的,也即都是從 0 號倉庫,1 號倉庫,一直到 N 號倉庫,都是獨享的。
但是從操作系統內核的角度來看,當然不可能獨享,而是大家共享,M 號倉庫只有一個,你用他就不能用,這就需要一個倉庫調度系統,將用戶進程的倉庫號和實際使用的倉庫號對應起來。
例如進程 1 的 10 號倉庫,對應到真實的倉庫是 110 號,進程 2 的 20 號倉庫,對應到真實的倉庫是 120 號。
操作系統功能之四:文件系統
對于 Linux 來講,很多東西都是文件,例如進程號會對應一個文件,建立一個網絡連接也對應一個文件。文件系統多種多樣,為了能夠統一適配,有一個虛擬文件系統的中間層 VFS。
操作系統功能之五:設備管理
設備分兩種,一種是塊設備,一種是字符設備,例如硬盤就是塊設備,可以格式化為文件系統,再如鼠標和鍵盤的輸入輸出是字符設備。
操作系統功能之六:網絡管理

對于 Linux 來講,網絡也是基于設備和文件系統的,但是由于網絡有自己的協議棧,要遵循 TCP/IP 協議棧標準。
了解數據中心和網絡基礎知識
云平臺當然會部署在數據中心里面,由于數據中心里面的硬件設備也是非常專業的,因而很多地方機房部門和云計算部門是兩個部門。
但是作為一個云架構師,需要和機房部門進行溝通,因而需要一定的數據中心知識,在數據中心里面,最難搞定的是網絡,因而這里面網絡知識是重中之重。
下面這個圖是一個典型的數據中心圖:

最外層是 Internet Edge,也叫 Edge Router,也叫 Border Router,它提供數據中心與 Internet 的連接。
第一層 Core Network,包含很多的 Core Switches:
- Available Zone 同 Edge Router 之間通信。
- Available Zone 之間的通信提供。
- 提供高可用性連接 HA。
- 提供 Intrusion Prevention Services。
- 提供 Distributed Denial of Service Attack Analysis and Mitigation。
- 提供 Tier 1 Load Balancer
第二層也即每個 AZ 的最上層,我們稱為 Aggregation Layer。
第三層是 Access Layer,就是一個個機架的服務器,用接入交換機連接在一起。
這是一個典型的三層網絡結構,也即接入層、匯聚層、核心層三層。除了數據中心以外,哪怕是做應用架構,對于網絡的了解也是必須的。

云架構說到底是分布式架構,既然是分布式,就是去中心化的,因而就需要系統之間通過網絡進行互通,因而網絡是作為大規模系統架構繞不過去的一個坎。
對于網絡的基本原理,推薦書籍《計算機網絡-嚴偉與潘愛民譯》,《計算機網絡:自頂向下方法》。
對于 TCP/IP 協議棧的了解,推薦書籍《TCP/IP 詳解》,《The TCP/IP Guide》。
對于網絡程序設計,推薦書籍《Unix 網絡編程》,如果你想了解網絡協議棧的實現,推薦書籍《深入理解 Linux 網絡內幕》 。
基于 KVM 了解計算虛擬化
當物理機搭建完畢之后,接下來就是基于物理機上面搭建虛擬機了。
沒有了解虛擬機的同學,可以在自己的筆記本電腦上用 VirtualBox 或者 Vmware 創建虛擬機,你會發現,很容易就能在物理機的操作系統之內再安裝多個操作系統。
通過這種方式,你可以很方便的在 Windows 辦公系統之內安裝一個 Linux 系統,從而保持 Linux 系統的持續學習。

前面講 Linux 操作系統的時候,說到操作系統,就是整個系統的管家。應用程序要申請資源,都需要通過操作系統的系統調用接口,向操作系統內核申請將 CPU,內存,網絡,硬盤等資源分配給他。
這時候你會發現,虛擬機也是物理機上的一個普通進程,當虛擬機內部的應用程序申請資源的時候,需要向虛擬機的操作系統請求。
然而虛擬機的操作系統自己本身也沒有權限操作資源,因而又需要像物理機的操作系統申請資源。
這中間要多一次翻譯的工作,完成這件事情的稱為虛擬化軟件。例如上面說的 VirtualBox 和 Vmware 都是虛擬化軟件。
但是多一層翻譯,就多一層性能損耗,如果虛擬機里面的每一個操作都要翻譯,都不能直接操作硬件,性能就會差很多,簡直沒辦法用,于是就出現了上圖中的硬件輔助虛擬化,也即通過硬件的特殊配置。
例如 VT-x 和 VT-d 等,讓虛擬機里面的操作系統知道,它不是一個原生的操作系統了,是一個虛擬機的操作系統,不能按照原來的模式操作資源了,而是通過特殊的驅動以硬件輔助的方式抄近道操作物理資源。
剛才說的是桌面虛擬化,也就是在你的筆記本電腦上,在數據中心里面,也可以使用 Vmware 進行虛擬化,但是價格比較貴,如果規模比較大,會采取開源的虛擬化軟件 qemu-kvm。

對于 qemu-kvm 來說,和上面的原理是一樣的,其中 qemu 的 emu 是 emulator 的意思,也即模擬器,就是翻譯的意思。
KVM 是一個可以使用 CPU 的硬件輔助虛擬化的方式,而網絡和存儲的,需要通過特殊的 virtio 的方式,提供高性能的設備虛擬化功能。
要了解虛擬化的基本原理,推薦書籍《系統虛擬化——原理與實現》,要了解 KVM,推薦兩本書籍《KVM Virtualization Cookbook》和《Mastering KVM Virtualization》。
另外 KVM 和 qemu 的官方文檔也是必須要看的,還有 Redhat 的官網很多文章非常值得學習。
基于 Openvswitch 了解網絡虛擬化
當虛擬機創建出來了,最主要的訴求就是要能上網,它能訪問到網上的資源,如果虛擬機里面部署一個網站,也希望別人能夠訪問到它。
這一方面依賴于 qemu-KVM 的網絡虛擬化,將網絡包從虛擬機里面傳播到虛擬機外面,這需要物理機內核轉換一把,形成虛擬機內部的網卡和虛擬機外部的虛擬網卡。
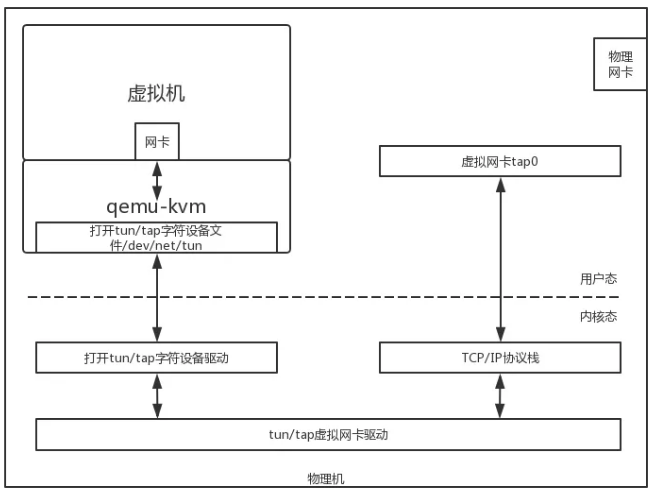
另外一方面就是虛擬機的網絡如何能夠連接到物理網絡里面。物理網絡常常稱為 underlay network,虛擬網絡常常稱為 overlay network。
從物理網絡到虛擬網絡稱為網絡虛擬化,能非常好的完成這件事情的是一個叫 Openvswitch 的虛擬交換機軟件。

Openvswitch 會有一個內核驅動,監聽物理網卡,可以將物理網卡上收到的包拿進來。
虛擬機創建出來的外部的虛擬網卡也可以添加到 Openvswitch 上,而 Openvswitch 可以設定各種的網絡包處理策略,將網絡包在虛擬機和物理機之間進行傳遞,從而實現了網絡虛擬化。

對于 Openvswitch,我主要是通過官方文檔進行研究。
基于 OpenStack 了解云平臺
當有了虛擬機,并且虛擬機能夠上網了之后,接下來就是搭建云平臺的時候了。
云是基于計算,網絡,存儲虛擬化技術的,云和虛擬化的主要區別在于,管理員的管理模式不同,用戶的使用模式也不同。
虛擬化平臺沒有多層次的豐富的租戶管理,沒有靈活 quota 配額的限制,沒有靈活的 QoS 的限制。
多采用虛擬網絡和物理網絡打平的橋接模式,虛擬機直接使用機房網絡,沒有虛擬子網 VPC 的概念,虛擬網絡的管理和隔離不能和租戶隔離完全映射起來。
對于存儲也是,公司采購了統一的存儲,也不能和租戶的隔離完全映射起來。
使用虛擬化平臺的特點是,對于這個平臺的操作完全由運維部門統一管理,而不能將權限下放給業務部門自己進行操作。
因為一旦允許不同的部門自己操作,大家都用機房網絡,在沒有統一管控的情況下,很容易網段沖突了。
如果業務部門想申請虛擬機,需要通過工單向運維部門提統一的申請。當然這個運維部門很適應這種方式,因為原來物理機就是這樣管理的。
但是公有云,例如 AWS 就沒辦法這樣,租戶千千萬萬,只能他們自己操作。
在私有云里面,隨著服務化甚至微服務化的進行,服務數目越來越多,迭代速度越來越快,業務部門需要更加頻繁的創建和消耗虛擬機,如果還是由運維部統一審批,統一操作,會使得運維部門壓力非常大。
而且還會極大限制了迭代速度,因而要引入租戶管理,運維部靈活配置每個租戶的配額 quota 和 QoS,在這個配額里面,業務部門隨時可以按照自己的需要,創建和刪除虛擬機,無需知會運維部門。
每個部門都可以創建自己的虛擬網絡 VPC,不同租戶的 VPC 之前完全隔離。
所以網段可以沖突,每個業務部門自己規劃自己的網絡架構,只有少數的機器需要被外網或者機房訪問的時候,需要少數的機房 IP。
這個也是和租戶映射起來的,可以在分配給業務部門機房網 IP 的個數范圍內,自由的使用。這樣每個部門自主操作,迭代速度就能夠加快了。
云平臺中的開源軟件的代表是 OpenStack,建議大家研究 OpenStack 的設計機制,是在云里面通用的,了解了 OpenStack,對于公有云,容器云,都能發現相似的概念和機制。
通過我們研究 OpenStack,我們會發現很多非常好的云平臺設計模式。
第一:基于 PKI Token 的認證模式
如果我們要實現一個 Restful API,希望有個統一的認證中心的話,Keystone 的三角形工作模式是常用的。
當我們要訪問一個資源,通過用戶名密碼或者 AK/SK 登錄之后,如果認證通過,接下來對于資源的訪問,不應該總帶著用戶名密碼,而是登錄的時候形成一個 Token,然后訪問資源的時候帶著 Token,服務端通過 Token 去認證中心進行驗證即可。

如果每次驗證都去認證中心,效率比較差,后來就有了 PKI Token,也即 Token 解密出來是一個有詳細租戶信息的字符串,這樣本地就可以進行認證和鑒權。

第二:基于 Role Based Access Control 的鑒權模式
對于權限控制,我們學會比較通用的 Role Based Access Control 的權限控制模式, 形成“用戶-角色-權限”的授權模型。
在這種模型中,用戶與角色之間,角色與權限之間,一般兩者是多對多的關系,可以非常靈活的控制權限。

第三:基于 Quota 的配額管理
可以通過設置計算,網絡,存儲的 quota,設置某個租戶自己可以自主操作的資源量。
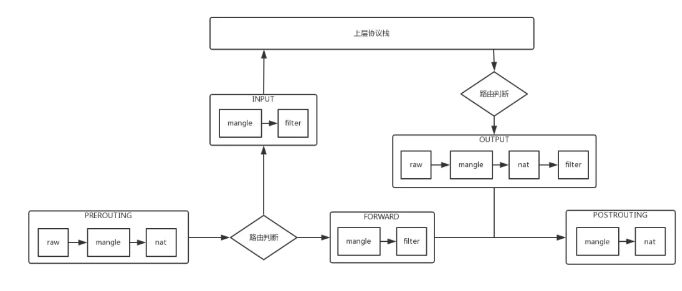
第四:基于預選和優選兩階段的 Scheduler 機制

當需要從一個資源池里面,選擇一個節點,使用這個節點上的資源的時候,一個通用的 Scheduler 機制是:
首先進行預選,也即通過 Filter,將不滿足條件的過濾掉。
然后進行優選,也即對于過濾后,滿足條件的候選人,通過計算權重,選擇其中最優的。
第五:基于獨立虛擬子網的網絡模式

為了每個租戶可以獨立操作,因而虛擬網絡應該是獨立于物理網絡的,這樣不同的租戶可以進行獨立的網絡規劃而互不影響,也不影響物理網絡,當需要跨租戶訪問,或者要訪問物理網絡的時候,需要通過路由器。
第六:基于 Copy On Write 的鏡像機制
有時候我們在虛擬機里面做了一些操作以后,希望能夠把這個時候的鏡像保存下來,好隨時恢復到這個時間點,一個最最簡單的方法就是完全復制一份,但是由于鏡像太大了,這樣效率很差。
因而采取 Copy On Write 的機制,當打鏡像的時刻,并沒有新的存儲消耗,而是當寫入新的東西的時候,將原來的數據找一個地方復制保存下來,這就是 Copy On Write。
對于 Openstack,有一種鏡像 qcow2 就是采取的這樣的機制。

這樣鏡像就像分層一樣,一層一層的羅列上去。
第七:基于 namespace 和 cgroup 的隔離和 Qos 機制
在 OpenStack 里面,網絡節點的路由器是由 network namespace 來隔離的。

KVM 的占用的 CPU 和內存,使用 Cgroup 來隔離的。

網絡的 QoS 使用 TC 來隔離的。

第八:基于 iptables 的安全機制
有時候,我們希望網絡中的節點之間不能相互訪問,作為最簡單的防火墻,iptables 起到了很重要的作用,以后實現 ACL 機制的,都可以考慮使用 iptables。
基于 Mesos 和 Kubernetes 了解容器平臺
搭建完畢虛擬化層和云平臺層,接下來就是容器層了。Docker 有幾個核心技術,一個是鏡像,一個是運行時,運行時又分看起來隔離的 namespace 和用起來隔離的 cgroup。
Docker 的鏡像也是一種 Copy On Write 的鏡像格式,下面的層級是只讀的,所有的寫入都在最上層。

對于運行時,Docker 使用的 namespace 除了 network namespace 外,還有很多,如下表格所示。

Docker 對于 cgroup 的使用是在運行 Docker 的時候,在路徑 /sys/fs/cgroup/cpu/docker/ 下面控制容器運行使用的資源。
可見容器并沒有使用更新的技術,而是一種新型的交付方式,也即應用的交付應該是一容器鏡像的方式交付,容器一旦啟動起來,就不應該進入容器做各種修改,這就是不可改變基礎設施。
由于容器的鏡像不包含操作系統內核,因而小的多,可以進行跨環境的遷移和彈性伸縮。
有了容器之后,接下來就是容器平臺的選型,其實 Swarm、Mesos、Kubernetes 各有優勢,也可以在不同的階段,選擇使用不同的容器平臺。
基于 Mesos 的 DCOS 更像是一個數據中心管理平臺,而非僅僅容器管理平臺,它可以兼容 Kubernetes 的編排,同時也能跑各種大數據應用。
在容器領域,基于 Kubernetes 的容器編排已經成為事實標準。

當我們深入分析 Kubernetes 管理容器模式的時候,我們也能看到熟悉的面孔。
在 Kubernetes 里面,租戶之間靠 namespace 進行隔離,這個不是 Docker 的 namespace,而是 Kubernetes 的概念。
API Server 的鑒權,也是基于 Role Based Access Control 模式的。Kubernetes 對于 namespace,也有 Quota 配置,使用 ResourceQuota。

當 Kubernetes 想選擇一個節點運行 pod 的時候,選擇的過程也是通過預選和優選兩個階段:
預選(Filtering)
- PodFitsResources 滿足資源。
- PodSelectorMatches 符合標簽。
- PodFitsHost 符合節點名稱。
優選(Weighting)
- LeastRequestedPriority 資源消耗最小。
- BalancedResourceAllocation 資源使用最均衡。
Kubernetes 規定了以下的網絡模型定義:
- 所有的容器都可以在不使用 NAT 的情況下同別的容器通信。
- 所有的節點都可以在不使用 NAT 的情況下同所有的容器通信。
- 容器的地址和別人看到的地址一樣。
也即容器平臺應該有自己的私有子網,常用的有 Flannel、Calico、Openvswitch 都是可以的。
既可以使用 Overlay 的方式,如圖 Flannel:
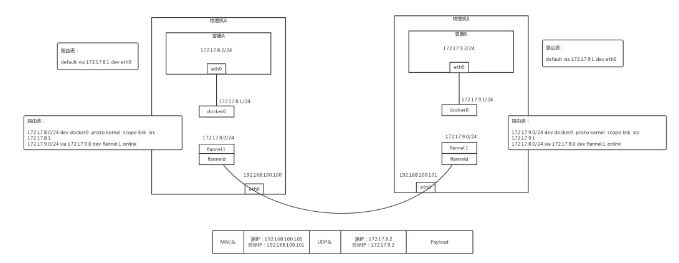
也可以使用 BGP 的方式,如圖 Calico:

基于 Hadoop 和 Spark 了解大數據平臺
對于數據架構的部分,其實經歷了三個過程,分別是 Hadoop Map-Reduce 1.0,基于 Yarn 的 Map-Reduce 2.0,還有 Spark。
如下圖是 Map-Reduce 1.0 的過程:

Map-Reduce 的過程將一個大任務,split 成為多個 Map Task,分散到多臺機器并行處理,將處理的結果保存到本地,第二個階段,Reduce Task 將中間結果拷貝過來,將結果集中處理,取得最終結果。
在 Map-Reduce 1.0 的時候,跑任務的方式只有這一種,為了應對復雜的場景,將任務的調度和資源的調度分成兩層。
其中資源的調用由 Yarn 進行,Yarn 不管是 Map 還是 Reduce,只要向它請求,它就找到空閑的資源分配給它。
每個任務啟動的時候,專門啟動一個 Application Master,管理任務的調度,它是知道 Map 和 Reduce 的。這就是 Map-Reduce 2.0,如下圖:

這里 Yarn 相當于外包公司的老板,所有的員工都是 Worker,都是他的資源,外包公司的老板是不清楚接的每一個項目的。
Application Master 相當于接的每個項目的項目經理,他是知道項目的具體情況的,他在執行項目的時候,如果需要員工干活,需要向外包公司老板申請。
Yarn 是個通用的調度平臺,能夠跑 Map-Reduce 2,就能跑 Spark。

Spark 也是創建 Spark 自己的 Application Master,用于調度任務。
Spark 之所以比較快,是因為前期規劃做的好,不是像 Map-Reduce 一樣,每一次分配任務和聚合任務都要寫一次硬盤,而是將任務分成多個階段,將所有在一個 Map 都做了的合成一個階段,這樣中間不用落盤,但是到了需要合并的地方,還是需要落盤的。
基于 Lucene 和 ElasticSearch 了解搜索引擎

當大數據將收集好的數據處理完畢之后,一般會保存在兩個地方,一個是正向索引,可以用 Hbase,Cassandra 等文檔存儲,一個是反向索引,方便搜索,就會保存在基于 Lucene 的 ElasticSearch 里面。
基于 Spring Cloud 了解微服務
最后到了應用架構,也即微服務。接下來細說微服務架構設計中不得不知的十大要點。

設計要點一:負載均衡 + API 網關

在實施微服務的過程中,不免要面臨服務的聚合與拆分。
當后端服務的拆分相對比較頻繁的時候,作為手機 App 來講,往往需要一個統一的入口,將不同的請求路由到不同的服務,無論后面如何拆分與聚合,對于手機端來講都是透明的。
有了 API 網關以后,簡單的數據聚合可以在網關層完成,這樣就不用在手機 App 端完成,從而手機 App 耗電量較小,用戶體驗較好。
有了統一的 API 網關,還可以進行統一的認證和鑒權,盡管服務之間的相互調用比較復雜,接口也會比較多。
API 網關往往只暴露必須的對外接口,并且對接口進行統一的認證和鑒權,使得內部的服務相互訪問的時候,不用再進行認證和鑒權,效率會比較高。
有了統一的 API 網關,可以在這一層設定一定的策略,進行 A/B 測試,藍綠發布,預發環境導流等等。API 網關往往是無狀態的,可以橫向擴展,從而不會成為性能瓶頸。
設計要點二:無狀態化與獨立有狀態集群

影響應用遷移和橫向擴展的重要因素就是應用的狀態。無狀態服務,是要把這個狀態往外移,將 Session 數據,文件數據,結構化數據保存在后端統一的存儲中,從而應用僅僅包含商務邏輯。
狀態是不可避免的,例如 ZooKeeper,DB,Cache 等,把這些所有有狀態的東西收斂在一個非常集中的集群里面。整個業務就分兩部分,一個是無狀態的部分,一個是有狀態的部分。
無狀態的部分能實現兩點:
- 跨機房隨意地部署,也即遷移性。
- 彈性伸縮,很容易地進行擴容。
有狀態的部分,如 ZooKeeper,DB,Cache 有自己的高可用機制,要利用到它們自己高可用的機制來實現這個狀態的集群。
雖說無狀態化,但是當前處理的數據,還是會在內存里面的,當前的進程掛掉數據,肯定也是有一部分丟失的。
為了實現這一點,服務要有重試的機制,接口要有冪等的機制,通過服務發現機制,重新調用一次后端服務的另一個實例就可以了。
設計要點三:數據庫的橫向擴展

數據庫是保存狀態,是最重要的也是最容易出現瓶頸的。有了分布式數據庫可以使數據庫的性能隨著節點增加線性地增加。
分布式數據庫最最下面是 RDS,是主備的,通過 MySQL 的內核開發能力,我們能夠實現主備切換數據零丟失。
所以數據落在這個 RDS 里面,是非常放心的,哪怕是掛了一個節點,切換完了以后,你的數據也是不會丟的。
再往上就是橫向怎么承載大的吞吐量的問題,上面有一個負載均衡 NLB,用 LVS,HAProxy,Keepalived,下面接了一層 Query Server。
Query Server 是可以根據監控數據進行橫向擴展的,如果出現了故障,可以隨時進行替換的修復,對于業務層是沒有任何感知的。
另外一個就是雙機房的部署,DDB 開發了一個數據運河 NDC 的組件,可以使得不同的 DDB 之間在不同的機房里面進行同步。
這時候不但在一個數據中心里面是分布式的,在多個數據中心里面也會有一個類似雙活的一個備份,高可用性有非常好的保證。
設計要點四:緩存

在高并發場景下緩存是非常重要的。要有層次的緩存,使得數據盡量靠近用戶。數據越靠近用戶能承載的并發量也越大,響應時間越短。
在手機客戶端 App 上就應該有一層緩存,不是所有的數據都每時每刻從后端拿,而是只拿重要的,關鍵的,時常變化的數據。
尤其對于靜態數據,可以過一段時間去取一次,而且也沒必要到數據中心去取,可以通過 CDN,將數據緩存在距離客戶端最近的節點上,進行就近下載。
有時候 CDN 里面沒有,還是要回到數據中心去下載,稱為回源,在數據中心的最外層,我們稱為接入層,可以設置一層緩存,將大部分的請求攔截,從而不會對后臺的數據庫造成壓力。
如果是動態數據,還是需要訪問應用,通過應用中的商務邏輯生成,或者去數據庫讀取,為了減輕數據庫的壓力,應用可以使用本地的緩存,也可以使用分布式緩存。
如 Memcached 或者 Redis,使得大部分請求讀取緩存即可,不必訪問數據庫。
當然動態數據還可以做一定的靜態化,也即降級成靜態數據,從而減少后端的壓力。
設計要點五:服務拆分與服務發現

當系統扛不住,應用變化快的時候,往往要考慮將比較大的服務拆分為一系列小的服務。
這樣第一個好處就是開發比較獨立,當非常多的人在維護同一個代碼倉庫的時候,往往對代碼的修改就會相互影響。
常常會出現我沒改什么測試就不通過了,而且代碼提交的時候,經常會出現沖突,需要進行代碼合并,大大降低了開發的效率。
另一個好處就是上線獨立,物流模塊對接了一家新的快遞公司,需要連同下單一起上線,這是非常不合理的行為。
我沒改還要我重啟,我沒改還讓我發布,我沒改還要我開會,都是應該拆分的時機。
再就是高并發時段的擴容,往往只有最關鍵的下單和支付流程是核心,只要將關鍵的交易鏈路進行擴容即可,如果這時候附帶很多其他的服務,擴容既是不經濟的,也是很有風險的。
另外的容災和降級,在大促的時候,可能需要犧牲一部分的邊角功能,但是如果所有的代碼耦合在一起,很難將邊角的部分功能進行降級。
當然拆分完畢以后,應用之間的關系就更加復雜了,因而需要服務發現的機制,來管理應用相互的關系,實現自動的修復,自動的關聯,自動的負載均衡,自動的容錯切換。
設計要點六:服務編排與彈性伸縮

當服務拆分了,進程就會非常的多,因而需要服務編排來管理服務之間的依賴關系,以及將服務的部署代碼化,也就是我們常說的基礎設施即代碼。
這樣對于服務的發布,更新,回滾,擴容,縮容,都可以通過修改編排文件來實現,從而增加了可追溯性,易管理性,和自動化的能力。
既然編排文件也可以用代碼倉庫進行管理,就可以實現一百個服務中,更新其中五個服務,只要修改編排文件中的五個服務的配置就可以。
當編排文件提交的時候,代碼倉庫自動觸發自動部署升級腳本,從而更新線上的環境。
當發現新的環境有問題時,當然希望將這五個服務原子性地回滾,如果沒有編排文件,需要人工記錄這次升級了哪五個服務。
有了編排文件,只要在代碼倉庫里面 Revert,就回滾到上一個版本了。所有的操作在代碼倉庫里都是可以看到的。
設計要點七:統一配置中心

服務拆分以后,服務的數量非常多,如果所有的配置都以配置文件的方式放在應用本地的話,非常難以管理。
可以想象當有幾百上千個進程中有一個配置出現了問題,是很難將它找出來的,因而需要有統一的配置中心,來管理所有的配置,進行統一的配置下發。
在微服務中,配置往往分為以下幾類:
一類是幾乎不變的配置,這種配置可以直接打在容器鏡像里面。
第二類是啟動時就會確定的配置,這種配置往往通過環境變量,在容器啟動的時候傳進去。
第三類就是統一的配置,需要通過配置中心進行下發。例如在大促的情況下,有些功能需要降級,哪些功能可以降級,哪些功能不能降級,都可以在配置文件中統一配置。
設計要點八:統一日志中心

同樣是進程數目非常多的時候,很難對成千上百個容器,一個一個登錄進去查看日志,所以需要統一的日志中心來收集日志。
為了使收集到的日志容易分析,對于日志的規范,需要有一定的要求,當所有的服務都遵守統一的日志規范的時候,在日志中心就可以對一個交易流程進行統一的追溯。
例如在最后的日志搜索引擎中,搜索交易號,就能夠看到在哪個過程出現了錯誤或者異常。
設計要點九:熔斷,限流,降級

服務要有熔斷,限流,降級的能力,當一個服務調用另一個服務,出現超時的時候,應及時返回,而非阻塞在那個地方,從而影響其他用戶的交易,可以返回默認的托底數據。
當一個服務發現被調用的服務,因為過于繁忙,線程池滿,連接池滿,或者總是出錯,則應該及時熔斷,防止因為下一個服務的錯誤或繁忙,導致本服務的不正常,從而逐漸往前傳導,導致整個應用的雪崩。
當發現整個系統的確負載過高的時候,可以選擇降級某些功能或某些調用,保證最重要的交易流程的通過,以及最重要的資源全部用于保證最核心的流程。
還有一種手段就是限流,當既設置了熔斷策略,又設置了降級策略,通過全鏈路的壓力測試,應該能夠知道整個系統的支撐能力。
因而就需要制定限流策略,保證系統在測試過的支撐能力范圍內進行服務,超出支撐能力范圍的,可拒絕服務。
當你下單的時候,系統彈出對話框說 “系統忙,請重試”,并不代表系統掛了,而是說明系統是正常工作的,只不過限流策略起到了作用。
設計要點十:全方位的監控

當系統非常復雜的時候,要有統一的監控,主要有兩個方面,一個是是否健康,一個是性能瓶頸在哪里。
當系統出現異常的時候,監控系統可以配合告警系統,及時地發現,通知,干預,從而保障系統的順利運行。
當壓力測試的時候,往往會遭遇瓶頸,也需要有全方位的監控來找出瓶頸點,同時能夠保留現場,從而可以追溯和分析,進行全方位的優化。















