阿里螞蟻的機器學習算法-一 、二、三面面經,干貨速收!

阿里一面
1.自我介紹下:
我是XXX的碩士,機器學習專業,我研究方向偏向于深度學習;然后我本科是XXX的物聯網工程專業,本科做過兩個項目:
(1)基于大數據的股票市場分析(2)基于用戶操作的推薦系統 ;研究生階段目前印象最深是做了兩個項目:
1)機器人課程作業中的challenge
2)現在正在做的基于model的智能機器學習框架,著重介紹在***一個,然后問了下實際工作,完成程度,貢獻度。***追問了一個對于物聯網的看法。
2.hashmap介紹
先說了下自己知道JAVA的hash map的用法,python中dictionary也是用hash表實現的:首先利用hash()將key和value映射到一個地址,它通過把key和value映射到表中一個位置來訪問記錄,這種查詢速度非常快,更新也快。而這個映射函數叫做哈希函數,存放值的數組叫做哈希表。 哈希函數的實現方式決定了哈希表的搜索效率。具體操作過程是:
1)數據添加:把key通過哈希函數轉換成一個整型數字,然后就將該數字對數組長度進行取余,取余結果就當作數組的下標,將value存儲在以該數字為下標的數組空間里。
2)數據查詢:再次使用哈希函數將key轉換為對應的數組下標,并定位到數組的位置獲取value。
但是,對key進行hash的時候,不同的key可能hash出來的結果是一樣的,尤其是數據量增多的時候,這個問題叫做哈希沖突。如果解決這種沖突情況呢?通常的做法有兩種,一種是鏈接法,另一種是開放尋址法,Python選擇后者。
開放尋址法(open addressing):
開放尋址法中,所有的元素都存放在散列表里,當產生哈希沖突時,通過一個探測函數計算出下一個候選位置,如果下一個獲選位置還是有沖突,那么不斷通過探測函數往下找,直到找個一個空槽來存放待插入元素。
3.算法:快排的時間復雜度和空間復雜度?平均多少?最差多少?還有那些排序的時間復雜度是O(nlogn)?知道排序中的穩定性嗎?我:快排的時間復雜度我記很清楚是O(nlogn),空間復雜度是O(1),平均就是O(nlogn),最差是O(n^2),退化成了冒泡排序;此外還有時間復雜度為O(nlogn)的還有堆排序和歸并排序;排序的穩定性知道是在排序之前,有兩個元素A1,A2,A1在A2之前,在排序之后還是A1在A2之前。
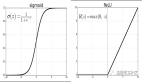
4.SVM和Logistic Regression對比:首先我介紹了下logistics regression的過程,就是把y=wx+b的結果放到sigmoid函數里,把sigmoid作為一個分類器,這樣做的原因是sigmoid函數能把所有范圍的值域控制在(0,1)區間內,然后我們把0.5作為一個分類的閾值,大于0.5的作為正類,小于0.5的作為負類。然后SVM是一個利用超平面將數據隔開分類的問題,首先我們在max所有距離平面最近的點的margin,同時subject to y(wx+b)>0,意味著分類正確:
然后:我們可以的到最近點到平面的距離:
我們***再用拉格朗日乘子式將subjuct to 條件轉換成一個等式求解***的w,b 然后求得最有超平面。我說SVM有很多kernel,這個有點像regulation,面試官說錯了,你講講kernel是什么干什么用的?我說kernel是把數據把低維映射到高維,因為有些數據在低維不可分,映射高維可以找到超平面去劃分,更好準確。
***說了LR比較方便計算,SVM 高維kernel計算復雜,但是準確。如果數據多,要求實時得到預測結果,用LR;如果數據不多,要求準確率,我選擇SVM。另外SVM可以用于多分類,而LR只能用于二分類
5.解決Overfitting、regulation的方法:regulation,我才總結下了,大致主要聊了2點:
(1)dropout,介紹dropout的概念啊,問了下train和test階段的不一樣過程細節。
主要講了下test把active function的輸出都乘以P,這樣就把train和test的輸出期望都scale到了一個range,這樣才是更加準確的。
(2)Batch Normalisation:BN,BN的原理,問什么好,好在哪里?
1)降低了樣本之間的差異,scale到(0,1)。
2)降低了層層之間的依賴,主要體現在前一層的輸出是下一層的輸入,那么我們把所有數據都scale到了(0,1)的distribution,那么降低了層層之間的依賴關系,從而使數據更加準確。
全程聊了一個小時,我人都傻了,一面不是面簡歷嗎?(內心OS。***問了面試官兩個問題:1)我本來跟老板匯報了工作在路上走著,電話就來了,我就說沒準備好問了下面試官對我的評價,然后面試官很nice說基本面不錯,給我評價偏正面;2)問了面試官的部門工作內容,balala講了一堆。然后跟我說,后面可能有人聯系你,也可能沒人聯系你,有人聯系的話,可能是他同事。
二面
一,介紹自己及項目:主要介紹自己在TensorLayer框架的制作,貢獻,太細節了,導致面試官說本來要問我的都說了。
二.基礎考察:
1.你知道感知野嗎?什么作用?你知道卷積的作用嗎?你用過池化層嗎?有哪些?
當時一臉懵逼,感知野是神馬啊?***再次確認了感知野其實就是在多個kernel做卷積的時候的窗口區域,就是3個33等于1個77的感知大小。
卷積的作用是提取特征,前面的卷積提取類似于人眼能識別的初步特征,后面的卷積是能夠提取更加不容易發現但是真實存在的特征。
Pooling 用過,max pooling, average pooling, global average pooling。再問這兩個分別有什么用?
max pooling我蠢到說提取最有特征的特征,其實就是***有代表性的特征;average pooling提取的是比較general 的特征;global average pooling用來分類的,因為后面網絡的加深,full connected layer參數太多了,不容易訓練,為了快速準確得到結果,采用global average pooling,沒有參數,但是得到的分類效果跟FC差不多。
2. 講到這里有點尬,你說你做過爬蟲,自己寫的還是用的框架?
用的框架,現在基本不用java我覺得我還是要補一補,差不多都忘光了,我所做的就是用Xpath找到爬取的元素,然后保存下來,再用腳本轉成待用Jason。
3.你機器學習的,知道sequence to sequence嗎?
我***反應是RNN,我說RNN沒了解,主要我只做深度學習CNN相關工作,大佬呵呵一笑,說你們要補補基礎啊。
4. 在線編程:
給個題目你寫寫吧,不用math中的取平法差,判斷一個自然數是不是可以開方(時間復雜度盡量低)?
媽耶,***反應二分查找。
一上去尬了寫了一個boolean,然后刪除,搞了個def開始寫函數。
***問了2個問題,他又問了我2個問題:(1)(這次是個P8大佬)在杭州,你工作地點介不介意?(我多說了幾句話,開了地圖炮,真的內心話)(2)你作為tensorlayer的contributor,對標Kreas,優勢在哪里?他說Kears底層支持好多庫caffe2,Pytorch,等等,我說TensorLayer出發點不一樣,怎么樣比比了一通,方正我覺得沒邏輯~感覺自己涼了~因為面試官給我回饋就是你要拓展你的機器學習知識面啊啊啊,我一個搞機器學習被吐槽這樣。。。
三面
全程50分鐘,主要講的是項目:針對項目提出幾個優化問題;
1.對于提供可以自由裁剪pre-train model,怎么保證你輸出的前面部分的check point 參數與模型結構 freeze在一起能在新的任務里,表現好?有沒有實驗數據支撐?
2.你知道depthwise-CNN嗎?講講具體原理?那1*1的kernel的作用是什么呢?對網絡model有什么影響?
3.你還知道或者學習過那些傳統機器學習算法?XGBoost?HMM?SVM等等都清楚嗎?
4. 你學過那些基本算法?數據結構的運用?
5. 你是哪里人?老家?籍貫?
6.問我大學經歷,未來打算,為什么工作?聽出來我想先工作,問我后面想不想讀博?
交換問題,
1.面試官的工作內容。
2.對自己的評價及建議:短時間內展示自己最閃亮的部分(第二天進四面,等待通知) 。