深度神經(jīng)網(wǎng)絡(luò)的分布式訓(xùn)練概述:常用方法和技巧全面總結(jié)
獨(dú)立研究者 Karanbir Chahal 和 Manraj Singh Grover 與 IBM 的研究者 Kuntal Dey 近日發(fā)布了一篇論文,對深度神經(jīng)網(wǎng)絡(luò)的分布式訓(xùn)練方法進(jìn)行了全面系統(tǒng)的總結(jié),其中涉及到訓(xùn)練算法、優(yōu)化技巧和節(jié)點(diǎn)之間的通信方法等。機(jī)器之心摘取了論文主干內(nèi)容進(jìn)行介紹,更多有關(guān)數(shù)學(xué)推理過程和算法步驟的解讀請參閱原論文。
論文地址:https://arxiv.org/abs/1810.11787
深度學(xué)習(xí)已經(jīng)為人工智能領(lǐng)域帶來了巨大的發(fā)展進(jìn)步。但是,必須說明訓(xùn)練深度學(xué)習(xí)模型需要顯著大量的計算。在一臺具有一個現(xiàn)代 GPU 的單臺機(jī)器上完成一次基于 ImageNet 等基準(zhǔn)數(shù)據(jù)集的訓(xùn)練可能要耗費(fèi)多達(dá)一周的時間,研究者已經(jīng)觀察到在多臺機(jī)器上的分布式訓(xùn)練能極大減少訓(xùn)練時間。近期的研究已經(jīng)通過使用 2048 個 GPU 的集群將 ImageNet 訓(xùn)練時間降低至了 4 分鐘。這篇論文總結(jié)了各種用于分布式訓(xùn)練的算法和技術(shù),并給出了用于現(xiàn)代分布式訓(xùn)練框架的當(dāng)前最佳方法。更具體而言,我們探索了分布式隨機(jī)梯度下降的同步和異步變體、各種 All Reduce 梯度聚合策略以及用于在集群上實現(xiàn)更高吞吐量和更低延遲的最佳實踐,比如混合精度訓(xùn)練、大批量訓(xùn)練和梯度壓縮。
1. 引言
(1) 背景和動機(jī)
數(shù)據(jù)正以前所未有的規(guī)模生成。大規(guī)模互聯(lián)網(wǎng)公司每天都會生成數(shù)以 TB 計的數(shù)據(jù),這些數(shù)據(jù)都需要得到有效的分析以提取出有意義的見解 [1]。新興的深度學(xué)習(xí)是一種用于執(zhí)行這種分析的強(qiáng)大工具,這些算法在視覺 [2]、語言 [3] 和智能推理 [4] 領(lǐng)域的復(fù)雜任務(wù)上創(chuàng)造著當(dāng)前最佳。不幸的是,這些算法需要大量數(shù)據(jù)才能有效地完成訓(xùn)練,而這又會耗費(fèi)大量時間。第一個在 ImageNet 分類任務(wù)上取得當(dāng)前最佳結(jié)果的深度學(xué)習(xí)算法在單個 GPU 上訓(xùn)練足足耗費(fèi)了一周時間。在如今的時代,這樣的速度已經(jīng)完全不行了,因為現(xiàn)在的模型訓(xùn)練所使用的數(shù)據(jù)甚至?xí)? ImageNet 數(shù)據(jù)集的規(guī)模都相形見絀。現(xiàn)在存在以橫向方式延展深度學(xué)習(xí)訓(xùn)練的內(nèi)在需求,同時還要保證能夠維持單 GPU 模型那樣的準(zhǔn)確度。理想情況下,這種訓(xùn)練的速度應(yīng)該隨機(jī)器數(shù)量的增加而線性增大,同時還要能容錯以及能在高延遲網(wǎng)絡(luò)條件下收斂。
(2) 分布式訓(xùn)練概述
神經(jīng)網(wǎng)絡(luò)的分布式訓(xùn)練可以通過兩種方式實現(xiàn):數(shù)據(jù)并行化和模型并行化。數(shù)據(jù)并行化的目標(biāo)是將數(shù)據(jù)集均等地分配到系統(tǒng)的各個節(jié)點(diǎn)(node),其中每個節(jié)點(diǎn)都有該神經(jīng)網(wǎng)絡(luò)的一個副本及其本地的權(quán)重。每個節(jié)點(diǎn)都會處理該數(shù)據(jù)集的一個不同子集并更新其本地權(quán)重集。這些本地權(quán)重會在整個集群中共享,從而通過一個累積算法計算出一個新的全局權(quán)重集。這些全局權(quán)重又會被分配至所有節(jié)點(diǎn),然后節(jié)點(diǎn)會在此基礎(chǔ)上處理下一批數(shù)據(jù)。
模型并行化則是通過將該模型的架構(gòu)切分到不同的節(jié)點(diǎn)上來實現(xiàn)訓(xùn)練的分布化。AlexNet [2] 是使用模型并行化的最早期模型之一,其方法是將網(wǎng)絡(luò)分?jǐn)偟?2 個 GPU 上以便模型能放入內(nèi)存中。當(dāng)模型架構(gòu)過大以至于無法放入單臺機(jī)器且該模型的某些部件可以并行化時,才能應(yīng)用模型并行化。模型并行化可用在某些模型中,比如目標(biāo)檢測網(wǎng)絡(luò) [5],這種模型的繪制邊界框和類別預(yù)測部分是相互獨(dú)立的。一般而言,大多數(shù)網(wǎng)絡(luò)只可以分配到 2 個 GPU 上,這限制了可實現(xiàn)的可擴(kuò)展數(shù)量,因此本論文主要關(guān)注的是數(shù)據(jù)并行化。
本論文大致分為六個章節(jié),第一節(jié)將介紹已有的優(yōu)化訓(xùn)練算法。第二節(jié)將關(guān)注用于連接網(wǎng)絡(luò)各節(jié)點(diǎn)的通信策略。第三節(jié)會探索一些具體技術(shù),比如大批量訓(xùn)練、梯度壓縮以及用于在低功耗設(shè)備和低速網(wǎng)絡(luò)條件下實現(xiàn)有效訓(xùn)練的混合精度訓(xùn)練。第四節(jié)則會消化之前章節(jié)的信息,并選擇出用于不同設(shè)定的最優(yōu)的訓(xùn)練算法和通信原語。最后兩節(jié)分別是未來研究方向和總結(jié)。
2. 分布式訓(xùn)練框架的組件
(1) 分布式訓(xùn)練算法
一個常用于分布式設(shè)定中的訓(xùn)練的常用算法是隨機(jī)梯度下降(SGD),該算法將是我們進(jìn)一步討論中的核心點(diǎn)。需要指出一個重點(diǎn),針對 SGD 提及的原則可以輕松地移植給其它常用的優(yōu)化算法,比如 Adam [6]、RMSProp [7] 等等 [8]。分布式 SGD 可以大致分成兩類變體:異步 SGD 和同步 SGD。
同步 SGD [9] 的目標(biāo)是像分布式設(shè)置一樣對算法進(jìn)行復(fù)制,由此將網(wǎng)絡(luò)中的節(jié)點(diǎn)緊密地耦合到一起。而異步 SGD [10] 則會通過降低節(jié)點(diǎn)之間的依賴程度而去除不同節(jié)點(diǎn)之間的耦合。盡管這種解耦能實現(xiàn)更大的并行化,但卻不幸具有副作用,即穩(wěn)定性和準(zhǔn)確性要稍微差一些。人們已經(jīng)提出了一些對異步 SGD 的修改方式,以期能縮小其與同步 SGD 的準(zhǔn)確度差距。最近的研究趨勢是擴(kuò)展同步 SGD,更具體而言,即用大批量來訓(xùn)練網(wǎng)絡(luò)已經(jīng)得到了出色的結(jié)果。
較大的 mini-batch 大小具有一些優(yōu)勢,主要的一個優(yōu)勢是:在大 mini-batch 上訓(xùn)練時,模型能以更大的步幅到達(dá)局部最小值,由此能夠加快優(yōu)化過程的速度。但是在實踐中,使用大批量會導(dǎo)致發(fā)散問題或「泛化差距」,即網(wǎng)絡(luò)的測試準(zhǔn)確度有時會低于在更小批量上訓(xùn)練的模型。最近的一些研究通過與批量大小成比例地調(diào)整學(xué)習(xí)率而實現(xiàn)了在大批量上的訓(xùn)練。實驗發(fā)現(xiàn),增加批量大小就相當(dāng)于降低學(xué)習(xí)率 [11],而使用大批量進(jìn)行訓(xùn)練還有一個額外的好處,即在訓(xùn)練中所要更新的總參數(shù)更少。通過將批量大小增大為 8096,以及使用線性學(xué)習(xí)率調(diào)整,已經(jīng)能在一小時內(nèi)完成在 ImageNet [12] 上的訓(xùn)練了 [9]。一種名為 LARS [13] 的技術(shù)支持使用高達(dá) 32k 的批量大小,[14] 中最近還與混合精度訓(xùn)練結(jié)合到了一起,使用 64k 的批量大小,在 4 分鐘內(nèi)成功完成了在 ImageNet 數(shù)據(jù)庫上的訓(xùn)練。
(2) 節(jié)點(diǎn)之間的通信
分布式訓(xùn)練還有另一個重要組件,即節(jié)點(diǎn)之間的數(shù)據(jù)通信。多虧了 GFS [15] 和 Hadoop [16] 等一些分布式文件系統(tǒng),這已經(jīng)是一個成熟的研究主題了。以點(diǎn)對點(diǎn)的方式在節(jié)點(diǎn)之間實現(xiàn)高效且可感知帶寬的通信需要集合通信原語(collective communication primitives)[17],這首先是在高性能計算(HPC)系統(tǒng)中引入的,之后由 [18] 帶進(jìn)了深度學(xué)習(xí)領(lǐng)域。TensorFlow [19] 和 PyTorch 等現(xiàn)代深度學(xué)習(xí)框架使用了這些原語來進(jìn)行 All Reduce 過程,因為其允許在最優(yōu)的時間內(nèi)完成互連節(jié)點(diǎn)之間的梯度傳輸。All Reduce [17] 在實際應(yīng)用中具有多種變體,比如 Ring All Reduce、遞歸減半或倍增(Recursive Halfing/Doubling)、Binary Blocks 算法。
在分布式訓(xùn)練中,為了實現(xiàn)有效的橫向擴(kuò)展,計算與通信的配置必須保證最優(yōu)。如果通信步驟是高效的且能與各個機(jī)器的計算保持同步,即整個集群中的計算應(yīng)該在大致同一時間結(jié)束,那么訓(xùn)練才是最優(yōu)的。如果網(wǎng)絡(luò)速度慢,那么節(jié)點(diǎn)之間的通信就會成為瓶頸。梯度壓縮和混合精度訓(xùn)練都是很有潛力的技術(shù),能夠增大網(wǎng)絡(luò)的整體吞吐量。近期的一項研究 [20] 已經(jīng)發(fā)現(xiàn)使用周期性的學(xué)習(xí)率能將實現(xiàn)網(wǎng)絡(luò)收斂所需的 epoch 數(shù)量降低 10 倍,使其成為了分布式訓(xùn)練方面一個很有潛力的研究方向。
(3) 隨機(jī)梯度下降(SGD)的變體
隨機(jī)梯度下降 [21] 是一種用于訓(xùn)練神經(jīng)網(wǎng)絡(luò)的優(yōu)化算法。這是梯度下降的一種變體,是一種用于調(diào)整權(quán)重的算法,能在每次反向傳播步驟之后使結(jié)果更接近最小值。SGD 不同于單純的梯度下降,因為其處理的是 mini-batch,而非單個訓(xùn)練樣本。其形式如下:
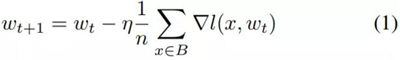
其中 w_(t+1) 是為當(dāng)前批計算出的權(quán)重,n 是 mini-batch 中的訓(xùn)練樣本的數(shù)量,∇l(x, w_t) 是為前一個訓(xùn)練樣本計算出的梯度。
對于分布式的情況,SGD 大致可分為兩類:異步 SGD 和同步 SGD。后續(xù)的章節(jié)會詳細(xì)介紹這兩種 SGD 和它們的變體。
3. 同步 SGD
同步 SGD 是一種分布式梯度下降算法,這是當(dāng)前用于分布式訓(xùn)練的最常用優(yōu)化方法之一。網(wǎng)絡(luò)中的節(jié)點(diǎn)首先在它們的本地數(shù)據(jù)批上計算出梯度,然后每個節(jié)點(diǎn)都將它們的梯度發(fā)送給主服務(wù)器(master server)。主服務(wù)器通過求這些梯度的平均來累積這些梯度,從而為權(quán)重更新步驟構(gòu)建出新的全局梯度集。這些全局梯度會通過使用與單機(jī)器 SGD 同樣的配方來更新每個節(jié)點(diǎn)的本地權(quán)重。這整個過程都類似于在單臺機(jī)器上通過單個數(shù)據(jù) mini-batch 計算前向通過和反向傳播步驟,因此同步 SGD 能保證收斂。但是同步 SGD 也存在一些局限性。
4. 異步 SGD
異步 SGD 是一種分布式梯度下降算法,允許在不同節(jié)點(diǎn)上使用不同的數(shù)據(jù)子集來并行地訓(xùn)練多個模型副本。每個模型副本都會向參數(shù)服務(wù)器請求全局權(quán)重,處理一個 mini-batch 來計算梯度并將它們發(fā)回參數(shù)服務(wù)器,然后參數(shù)服務(wù)器會據(jù)此更新全局權(quán)重。因為每個節(jié)點(diǎn)都獨(dú)立計算梯度且無需彼此之間的交互,所以它們可以按自己的步調(diào)工作,也對機(jī)器故障更為穩(wěn)健,即如果一個節(jié)點(diǎn)故障,其它節(jié)點(diǎn)還能繼續(xù)處理,因此能消除由同步 SGD 引入的同步屏障(synchronization barrier)問題。
5. Ring 算法
[17] 中的 Ring All Reduce 結(jié)合了兩種算法:scatter-reduce 和 all gather。

圖 1:Ring 算法
scatter reduce 工作 p-1 個步驟,其中 p 是機(jī)器的數(shù)量。梯度向量被分為 p 塊。

算法 1:Ring 算法的 scatter reduce
在 scatter reduce 過程結(jié)束后,每臺機(jī)器都會有一部分最終結(jié)果。現(xiàn)在,每臺機(jī)器只需將自己那部分結(jié)果廣播給所有其它機(jī)器即可。這是使用 all gather 過程完成的,非常類似于 scatter gather,只是在接收數(shù)據(jù)上有些約簡,這部分只是被看作是最終結(jié)果存儲起來。

算法 2:Ring 算法的 all gather
6. 遞歸減半和倍增算法
[17] 中的遞歸距離倍增和向量減半算法使用了 4 種不同的原語,如下所示:
- 遞歸向量減半:向量在每個時間步驟減半。
- 遞歸向量倍增:分散在各個進(jìn)程的向量的各個小塊被遞歸式地收集起來,構(gòu)建成一個大的向量。
- 遞歸距離減半:機(jī)器之間的距離在每次通信迭代后減半。
- 遞歸距離倍增:機(jī)器之間的距離在每次通信迭代后倍增。

圖 2:減半和倍增算法
類似于 Ring 算法,這種 All Reduce 算法也由兩個過程構(gòu)成:scatter-reduce 和 all gather。該算法與 Ring 算法的不同之處是這些過程執(zhí)行運(yùn)算的方式。

算法 3:Scatter Reduce 向量減半算法

算法 4:All Gather 向量倍增算法
7. Binary Blocks 算法
Binary Blocks 算法是對遞歸距離倍增和向量減半算法的延展,它的目標(biāo)是當(dāng)機(jī)器數(shù)量不是 2 的乘方數(shù)時降低負(fù)載的不平衡程度。在用于非 2 的乘方數(shù)情況的原始算法中,有一些機(jī)器會被閑置在一旁,直到算法執(zhí)行完成,之后它們會接收結(jié)果得到的向量。這種方法會導(dǎo)致某些情況下大量機(jī)器空閑,比如,對于 600 臺機(jī)器構(gòu)成的集群,會有 86 臺機(jī)器空閑,進(jìn)程只會在另外 512 臺機(jī)器上執(zhí)行。使用這種方法會出現(xiàn)很顯著的負(fù)載不平衡。
Binary Blocks 算法是通過將機(jī)器的數(shù)量分成 2 的乘方數(shù)的多個模塊來緩解這個問題。舉個例子,對于 600 臺機(jī)器構(gòu)成的集群,可以分成 4 組,其中每組各有 2^9、2^6、2^4、2^3 臺機(jī)器。
器算法")
算法 5:Binary Blocks 主服務(wù)器算法

算法 6:Scatter Reduce 主客戶端算法
8. 容錯式 All Reduce
如果一個分布式集群是由低可靠度的設(shè)備構(gòu)成的,那么一旦遇到機(jī)器故障就需要重啟 All Reduce 算法。我們提出了一種容錯式 Binary Blocks 算法,將 Raft 共識算法 [31] 的元素整合進(jìn)了 All Reduce 中。該算法能應(yīng)對機(jī)器故障,只要備份的副本仍可運(yùn)行,就能繼續(xù)執(zhí)行。

圖 3:Raft 算法
9. 調(diào)整批量大小
在實際訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)時,學(xué)習(xí)率會隨著訓(xùn)練經(jīng)過多個 epoch 后而緩慢逐漸減小。這背后的直觀思想是讓權(quán)重在訓(xùn)練初期邁開更大的步子,隨著模型接近收斂,步子也越來越小。這在實踐中的效果相當(dāng)好,并且能比使用固定學(xué)習(xí)率訓(xùn)練的模型達(dá)到更好的收斂程度。這也是一種很高效的方法,因為初期采用較大的學(xué)習(xí)率能夠在使用更小的學(xué)習(xí)率微調(diào)之前取得很好的進(jìn)展。但是,使用較大的批量大小進(jìn)行訓(xùn)練是一個很有前景的研究方向,因為這能顯著加速訓(xùn)練過程,能將訓(xùn)練時間從數(shù)天降至幾分鐘,正如 [9,14,13] 中證明的那樣;[11] 的研究更是增強(qiáng)了這一趨勢,通過實驗證明增大批量大小就相當(dāng)于降低學(xué)習(xí)率。
使用更大的批量大小進(jìn)行訓(xùn)練的優(yōu)勢是模型執(zhí)行的整體權(quán)重更新的數(shù)量更少,這能讓訓(xùn)練速度更快,如圖 4 所示。但是,相比于使用更小批量大小訓(xùn)練的模型,直接使用大批量進(jìn)行訓(xùn)練也會出現(xiàn)問題,比如過早發(fā)散以及最終驗證準(zhǔn)確度更低。
![衰減學(xué)習(xí)率與增大批量大小 [11]](https://s4.51cto.com/oss/201811/06/eedc5d2d143f911432adc0f4447f0b17.jpg "衰減學(xué)習(xí)率與增大批量大小 [11]")
圖 4:衰減學(xué)習(xí)率與增大批量大小 [11]
10. 張量融合
對于 ResNet 等某些常見的模型,研究者已經(jīng)觀察到為梯度計算的張量的大小是相當(dāng)小的。更具體而言,用于卷積層的梯度張量大小比全卷積層的要小得多。這個現(xiàn)象是很突出的,因為通過線路發(fā)送少量數(shù)據(jù)可能會導(dǎo)致出現(xiàn)大量延遲,同時也沒有充分利用網(wǎng)絡(luò)帶寬。一種解決這一問題的簡單方法是張量融合 [14],簡單來說就是將多個小張量融合到一起,形成一個至少超過某個最小大小的張量,之后再在網(wǎng)絡(luò)中發(fā)送這個融合得到的張量。執(zhí)行這種融合的好處是降低每臺機(jī)器起始時間的負(fù)載以及降低網(wǎng)絡(luò)流量的整體頻率。這能讓網(wǎng)絡(luò)變得不再亂七八糟以及在最優(yōu)時間內(nèi)完成任務(wù)。但是,為小張量使用張量融合可能會導(dǎo)致 Ring All Reduce 變得低效而緩慢,[14] 提出了一種分層式 All Reduce,使用了多層主從設(shè)置,觀察表明這種方法能帶來更低的延遲。這種分層式 All Reduce 的工作方式是將所有機(jī)器分成不同的批,之后每一批都選擇一個主節(jié)點(diǎn)來聚合梯度。這些主節(jié)點(diǎn)在它們自身上執(zhí)行 Ring All Reduce,之后該主節(jié)點(diǎn)將更新后的梯度分配給它們各自的從節(jié)點(diǎn)。這種策略是通過降低批的數(shù)量來降低延遲開銷,進(jìn)而逐步降低 Ring All Reduce 的開銷。使用張量融合能減少小網(wǎng)絡(luò)的處理,并提升網(wǎng)絡(luò)的整體速度,這是很值得推薦的。這種方法在 Horovord [38] 和騰訊的框架 [14] 等產(chǎn)業(yè)系統(tǒng)中得到了廣泛的使用,使其成為了現(xiàn)代分布式訓(xùn)練框架中的重要一員。
11. 低精度訓(xùn)練
在 ImageNet 數(shù)據(jù)庫 [12] 上訓(xùn)練一個 ResNet 模型 [29] 的最快時間目前是 4 分鐘 [14]。在那項研究中,研究者使用低延遲的零副本 RDMA 網(wǎng)絡(luò)連接了 2048 個 GPU,并且組合性地使用了 LARS 算法、混合 All Reduce 算法、張量融合和混合精度訓(xùn)練。混合 All Reduce 算法結(jié)合了 Ring All Reduce 和分層式的版本,并根據(jù)當(dāng)前步驟的張量大小來進(jìn)行切換。他們還使用了一種全新的方法才實現(xiàn)了這樣的整體訓(xùn)練速度增益:混合精度訓(xùn)練 [39]。由此所帶來的吞吐量和帶寬效率增長將訓(xùn)練速度提升了 8 倍。顧名思義,混合精度訓(xùn)練是使用兩種不同的數(shù)據(jù)類型來訓(xùn)練神經(jīng)網(wǎng)絡(luò)——更小的數(shù)據(jù)類型用于大多數(shù)運(yùn)算,更大的數(shù)據(jù)類型用于對精度要求嚴(yán)格的運(yùn)算。
神經(jīng)網(wǎng)絡(luò)最初是使用單精度或雙精度數(shù)作為默認(rèn)數(shù)據(jù)類型,因為這些數(shù)據(jù)類型在獲取網(wǎng)絡(luò)想要建模的任務(wù)的表征上表現(xiàn)很好。單精度數(shù)是 32 位浮點(diǎn)數(shù),雙精度數(shù)是 64 位浮點(diǎn)數(shù)。近期有研究表明通過在更低精度數(shù)據(jù)類型進(jìn)行訓(xùn)練,可將神經(jīng)網(wǎng)絡(luò)的速度和大小降低 50%-80% [40, 41]。一種常用方法是使用 16 位浮點(diǎn)數(shù)來訓(xùn)練網(wǎng)絡(luò)(FP16 訓(xùn)練),但與使用單精度訓(xùn)練的同樣網(wǎng)絡(luò)相比,這些網(wǎng)絡(luò)的測試準(zhǔn)確度會更差一些 [39]。這種情況的原因主要是權(quán)重更新步驟的精度更低。更具體而言,將低精度梯度與學(xué)習(xí)率相乘有時會導(dǎo)致數(shù)值溢出 16 位的范圍,從而導(dǎo)致計算不正確,進(jìn)而導(dǎo)致最終驗證準(zhǔn)確度損失。
混合精度訓(xùn)練 [39] 的目標(biāo)是通過使用單精度(32 位)的權(quán)重主副本并以半精度(16 位)運(yùn)行其它一切來解決這個問題。
混合精度訓(xùn)練能實現(xiàn)更高的吞吐量,從而能降低計算與通信瓶頸。但是,混合精度訓(xùn)練也存在一些需要注意的是像,即損失丟失和算術(shù)精度更低。
12. 梯度和參數(shù)壓縮
擴(kuò)展分布式訓(xùn)練過程的一個主要瓶頸是節(jié)點(diǎn)之間的模型權(quán)重和梯度通信具有很高的帶寬成本。當(dāng)在使用了聯(lián)盟學(xué)習(xí)(federated learning)[42] 的設(shè)備(尤其是移動設(shè)備)上訓(xùn)練時,這個瓶頸會尤其顯著,因為其存在網(wǎng)絡(luò)帶寬低和連接速度慢的問題。針對這一問題,研究者已經(jīng)提出了多種用于高效利用網(wǎng)絡(luò)帶寬的方法。使用 SGD 的異步和同步變體允許節(jié)點(diǎn)各自獨(dú)立地通信,同時還能實現(xiàn)并行化并將網(wǎng)絡(luò)帶寬利用提升到一定程度 [10,43,44];另外在梯度壓縮上已經(jīng)取得一些顯著進(jìn)展也很有希望 [45]。這些方法主要基于兩大思想:量化和稀疏化。

算法 7:用于節(jié)點(diǎn) k 上單純的動量 SGD 的深度梯度壓縮
13. 未來研究
過去幾年來,分布式訓(xùn)練領(lǐng)域已經(jīng)取得了很大的進(jìn)展,并已為進(jìn)一步創(chuàng)新做好了準(zhǔn)備。相關(guān)領(lǐng)域目前正在增大 mini-batch 大小的限制,直到網(wǎng)絡(luò)不會發(fā)散或降低同步 SGD 的最終驗證準(zhǔn)確度的程度,還在研究解決異步 SGD 的 stale 梯度和最終驗證準(zhǔn)確度降低的問題。在更低功耗的設(shè)備上進(jìn)行訓(xùn)練已經(jīng)以聯(lián)盟學(xué)習(xí)(federated learning)[42] 的形式獲得一些發(fā)展勢頭,也出現(xiàn)了一些用于安全和去中心化訓(xùn)練的現(xiàn)代深度學(xué)習(xí)框架構(gòu)建模塊。在消費(fèi)級設(shè)備上訓(xùn)練有一些好處,其中之一是能夠打造能基于消費(fèi)者交互學(xué)習(xí)特定習(xí)慣的智能應(yīng)用,而且通過在設(shè)備上存儲數(shù)據(jù)和執(zhí)行訓(xùn)練,還能保證用戶的數(shù)據(jù)隱私。這類應(yīng)用的一個案例是 Android Predictive Keyboard(安卓預(yù)測鍵盤),它能在設(shè)備上學(xué)習(xí)用于預(yù)測下一個詞的小型個性化模型。在低功耗設(shè)備上訓(xùn)練的一個關(guān)鍵難題是可用的網(wǎng)絡(luò)帶寬和計算資源很少。高效的框架也許可以實現(xiàn)在手機(jī)和物聯(lián)網(wǎng)設(shè)備上的大規(guī)模訓(xùn)練,從而實現(xiàn)便攜式的深度學(xué)習(xí)應(yīng)用。[54] 已經(jīng)在低功耗設(shè)備上的分布式訓(xùn)練方面做出了一些出色的工作,其使用了強(qiáng)化學(xué)習(xí)算法來調(diào)度在異構(gòu)式設(shè)備集群上的訓(xùn)練任務(wù)。在商品級設(shè)備上進(jìn)行分布式訓(xùn)練需要在訓(xùn)練和通信方面進(jìn)行多種優(yōu)化。梯度壓縮和混合精度訓(xùn)練是少數(shù)幾種結(jié)果優(yōu)良且很有希望的方向。整體而言,這個領(lǐng)域的研究方向很活躍且存在很多創(chuàng)新,并已經(jīng)做好準(zhǔn)備,即將成為更廣泛智能應(yīng)用的核心組件。
總結(jié)
我們介紹和總結(jié)了分布式訓(xùn)練框架的各個組件。為了打造一個高效且可擴(kuò)展的分布式訓(xùn)練框架,我們推薦使用以下技術(shù):
推薦使用同步 SGD 算法來進(jìn)行訓(xùn)練,因為它有嚴(yán)格的收斂保證。
應(yīng)該使用 Binary Blocks 算法來執(zhí)行梯度累積的 All Reduce 流程,因為其運(yùn)行時間更優(yōu)。
為了有效地使用硬件和網(wǎng)絡(luò)帶寬,應(yīng)該在框架中使用梯度壓縮、量化和混合精度訓(xùn)練等多種技術(shù)。我們推薦組合式地使用深度梯度壓縮和混合精度訓(xùn)練。
應(yīng)該使用非常大的批量大小來進(jìn)行訓(xùn)練,以最大化并行能力和最小化運(yùn)行時間。我們推薦使用 LARS 算法,因為已有研究證明它能夠以高達(dá) 64000 的批量大小足夠穩(wěn)健地訓(xùn)練網(wǎng)絡(luò)。
【本文是51CTO專欄機(jī)構(gòu)“機(jī)器之心”的原創(chuàng)譯文,微信公眾號“機(jī)器之心( id: almosthuman2014)”】