如何高效訓(xùn)練?綜述匯總:大型深度學(xué)習(xí)訓(xùn)練的并行分布式系統(tǒng)
本文經(jīng)自動(dòng)駕駛之心公眾號(hào)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
23年1月論文“Systems for Parallel and Distributed Large-Model Deep Learning Training“, 來自UCSD。

深度學(xué)習(xí)(DL)已經(jīng)改變了各種領(lǐng)域的應(yīng)用,包括計(jì)算機(jī)視覺、自然語(yǔ)言處理和表格數(shù)據(jù)分析。對(duì)提高DL模型精度的探索促使探索越來越大的神經(jīng)架構(gòu),最近的一些Transformer模型跨越了數(shù)千億個(gè)可學(xué)習(xí)參數(shù)。這些設(shè)計(jì)為DL空間帶來了規(guī)模驅(qū)動(dòng)系統(tǒng)挑戰(zhàn),例如內(nèi)存瓶頸、運(yùn)行時(shí)效率低和模型開發(fā)成本高。解決這些問題的努力已經(jīng)探索了一些技術(shù),如神經(jīng)架構(gòu)的并行化、在內(nèi)存層次結(jié)構(gòu)中溢出數(shù)據(jù)以及高效內(nèi)存的數(shù)據(jù)表示。這項(xiàng)調(diào)查將探索大型模型訓(xùn)練系統(tǒng)的前景,強(qiáng)調(diào)關(guān)鍵挑戰(zhàn)和用于解決這些挑戰(zhàn)的各種技術(shù)。
DL實(shí)踐的最新發(fā)展為DL研究引入了系統(tǒng)模型規(guī)模的新挑戰(zhàn)。實(shí)踐者已經(jīng)開始探索將非常大的神經(jīng)結(jié)構(gòu)圖用于DL模型,其中一些包含數(shù)十億甚至數(shù)萬億的可訓(xùn)練參數(shù)!關(guān)鍵示例包括NLP Transformer模型BERT Large[16]、GPT-3[13]和Meta的深度學(xué)習(xí)推薦模型(DLRM)[41]。這些模型的龐大規(guī)模在三個(gè)關(guān)鍵領(lǐng)域帶來了嚴(yán)峻挑戰(zhàn)。
- (1) 內(nèi)存可擴(kuò)展性。標(biāo)準(zhǔn)DL訓(xùn)練通常將模型的參數(shù)保存在加速器(例如GPU)的存儲(chǔ)器上,并使用采樣數(shù)據(jù)來計(jì)算每個(gè)參數(shù)的梯度更新。對(duì)于非常大的模型,保存參數(shù)、中間計(jì)算和梯度更新所需的空間通常會(huì)超過加速器相對(duì)有限的內(nèi)存資源。高端消費(fèi)級(jí)GPU,如特斯拉V100[2],具有16-32GB的設(shè)備內(nèi)存,但大型DLRM可能需要數(shù)百GB的空間。
- (2) 性能。參數(shù)計(jì)數(shù)的增加通常與較高的執(zhí)行時(shí)間有關(guān)。此外,復(fù)雜的模型架構(gòu)往往需要大型數(shù)據(jù)集來提高模型的學(xué)習(xí)能力——例如,GPT-3在300Btoken上進(jìn)行訓(xùn)練[13],開源BLOOM語(yǔ)言模型在366B[12]上進(jìn)行訓(xùn)練。訓(xùn)練這樣的模型可能需要數(shù)周甚至數(shù)月的時(shí)間[12,41]。因此,可以提高執(zhí)行性能的優(yōu)化對(duì)大規(guī)模DL模型的開發(fā)人員非常有益。
- (3) 訓(xùn)練費(fèi)用。前兩個(gè)挑戰(zhàn)的標(biāo)準(zhǔn)解決方案通常涉及跨多個(gè)設(shè)備并行存儲(chǔ)或執(zhí)行。然而,這種方法可能會(huì)顯著提高計(jì)算成本。BLOOM使用416個(gè)A100 GPU進(jìn)行訓(xùn)練,Megatron LM使用512個(gè)[5]。這對(duì)大多數(shù)從業(yè)者來說是不現(xiàn)實(shí)的,尤其是當(dāng)這些GPU需要保留幾周甚至幾個(gè)月的訓(xùn)練時(shí)間時(shí)。在AWS上復(fù)制BLOOM的訓(xùn)練程序?qū)⒒ㄙM(fèi)550萬美元。請(qǐng)注意,這甚至沒有考慮到模型選擇的額外成本,包括訓(xùn)練多個(gè)模型以評(píng)估最佳超參數(shù)設(shè)置和配置[29]。
隨著不斷突破模型規(guī)模的界限,解決這些挑戰(zhàn)以實(shí)現(xiàn)大模型DL空間的進(jìn)一步發(fā)展變得越來越必要。因此,已經(jīng)開發(fā)了各種系統(tǒng)和技術(shù)來解決這些問題。一些方向包括重具體化(rematerialization)[15]、數(shù)據(jù)溢出/CPU卸載[23,36,37,45–47]、流水線/模型并行[21,25,27,33,40]和混合并行[26,31,36,37,60]。這些主題屬于“大模型訓(xùn)練技術(shù)”的保護(hù)傘,已成為工業(yè)界和學(xué)術(shù)界研究人員的重點(diǎn),但該領(lǐng)域的工作量之大使該主題難以確定方向。本文回顧大模型DL訓(xùn)練系統(tǒng)空間的現(xiàn)狀,并評(píng)估該領(lǐng)域未來的增長(zhǎng)和發(fā)展方向。
最近發(fā)布了一些關(guān)于該領(lǐng)域的高級(jí)別、簡(jiǎn)短的綜述[20,54],但并不全面,也沒有涉及模型選擇、混合并行性和技術(shù)交叉等關(guān)鍵主題。本文將討論這些領(lǐng)域,并進(jìn)一步深入研究最先進(jìn)的技術(shù)。
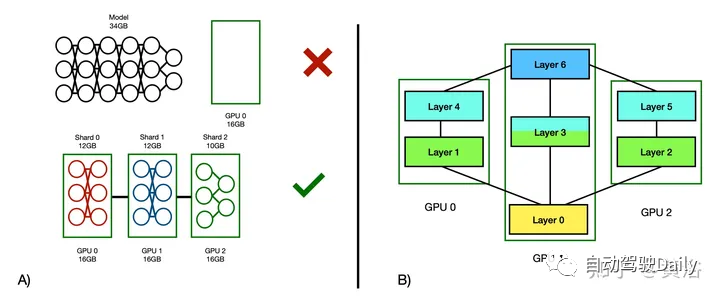
模型并行是指將神經(jīng)架構(gòu)圖劃分或分片為子圖,并將每個(gè)子圖或模型分片分配給不同設(shè)備的技術(shù)。在前饋網(wǎng)絡(luò)中,這些碎片可能指的是堆疊層的組。
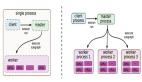
模型并行性的加速潛力在很大程度上取決于體系結(jié)構(gòu)和分片策略。前饋網(wǎng)絡(luò)上的序列模型分片(如圖A所示)將不提供并行執(zhí)行的范圍,而是在加速器之間引入相關(guān)圖(dependency graph)。然而,這種分片策略在序列體系結(jié)構(gòu)(如Transformers)中仍然很流行,因?yàn)樗梢栽诙鄠€(gè)設(shè)備之間分配內(nèi)存需求,而且設(shè)置起來相當(dāng)簡(jiǎn)單。在其他情況下,神經(jīng)計(jì)算圖為算子間并行提供了自然的機(jī)會(huì)(如圖B所示)。
如圖所示:A) 說明了如何將不適合單個(gè)GPU的大型前饋網(wǎng)絡(luò)在三個(gè)GPU上進(jìn)行模型并行化以實(shí)現(xiàn)執(zhí)行;(注:執(zhí)行速度并沒有加快——沒有并行執(zhí)行,只有分區(qū)內(nèi)存需求)B) 三個(gè)GPU上的性能模型并行分片策略的示例,并行執(zhí)行層用共享顏色表示;這種策略利用了算子圖中現(xiàn)有的并行執(zhí)行機(jī)會(huì)——如果圖本質(zhì)上更序貫處理,這可能并不一定。
另一種方法是實(shí)際劃分網(wǎng)絡(luò)中的各個(gè)算子。一些算子(如嵌入表)可以以最小的開銷按寬度進(jìn)行分片(sharded)。其他,如矩陣乘法,仍然可以進(jìn)行分割(例如使用并行GEMM策略[55]),但需要更多的通信步驟。如圖展示了一個(gè)模型并行嵌入表的示例。這些寬度分片策略,通常被稱為張量并行,因?yàn)樗鼈冃枰斎霃埩糠謪^(qū),可以實(shí)現(xiàn)比算子間模型并行更高性能的算子內(nèi)并行,但需要更多的精力和思考來實(shí)現(xiàn)。此外,大多數(shù)張量并行算子至少需要一個(gè)全聚集(all-gather)通信步驟來重新聚集分區(qū)輸出,這一事實(shí)削弱了性能優(yōu)勢(shì)。Mesh TensorFlow[51]提供了一個(gè)通用的框架和語(yǔ)言來指定張量并行計(jì)算,盡管它不再被支持或維護(hù)。

任何類型的模型并行都引入了GPU-GPU通信。最新的英偉達(dá)GPU支持“NVLink”互連,即提供高達(dá)900GB/s帶寬的高速GPU-GPU通信路由,這有助于最大限度地減少開銷。然而,NVLink并不總是現(xiàn)成的,尤其是當(dāng)用戶無法輕松定制的云端機(jī)器。當(dāng)不支持NVLink時(shí),GPU-GPU通信通過PCIe互連運(yùn)行,速度要慢得多。特斯拉V100通常被認(rèn)為是DL應(yīng)用程序的標(biāo)準(zhǔn)高性能GPU,支持16GB/s的16通道PCIe 3.0互連。
為了避免通過緩慢的互連傳輸過多數(shù)據(jù),模型并行性用戶通常會(huì)選擇一種分區(qū)策略,該策略將最小化需要在片之間傳輸?shù)募せ畹臄?shù)量,或者平衡計(jì)算以隱藏通信成本。為此存在各種分片算法[14,25,26,37,46,61]。
數(shù)據(jù)并行是一種常見的深度學(xué)習(xí)執(zhí)行策略,可以并行消費(fèi)多個(gè)小批量數(shù)據(jù)。數(shù)據(jù)并行執(zhí)行技術(shù)可以分為兩大類——異步數(shù)據(jù)并行和同步數(shù)據(jù)并行。
最著名的數(shù)據(jù)異步并行技術(shù)是Parameter Server,其中一個(gè)核心主服務(wù)器持有一組基線參數(shù),而分布式worker持有在不同的小批量上訓(xùn)練的模型副本。分布式工作程序偶爾會(huì)向基線服務(wù)器發(fā)送更新,而基線服務(wù)器又會(huì)向分布式工作程序發(fā)送替換參數(shù),以保持它們的更新。工作程序可能會(huì)彼此不同步,因?yàn)樗鼈冎恍枰c基線服務(wù)器通信/同步。異步技術(shù)帶來了許多挑戰(zhàn),例如與單個(gè)worker訓(xùn)練相比,準(zhǔn)確性下降,以及由于worker返回時(shí)間的差異而導(dǎo)致的不可復(fù)制的結(jié)果。由于這些原因,在現(xiàn)代DL訓(xùn)練環(huán)境中,異步技術(shù)通常被逐步淘汰,取而代之的是同步技術(shù)。
最流行的同步數(shù)據(jù)并行執(zhí)行技術(shù)是分布式數(shù)據(jù)并行(Distributed Data Parallelism,DDP)。DDP復(fù)制模型并將副本分配給 不同的加速器。首先接受一個(gè)初始的“全局小批量”,然后在副本之間均勻分解,為每個(gè)副本生成本地梯度更新。然后,這些梯度在副本之間聚合,產(chǎn)生全局更新,通常使用 all-reduce通信模式。然后將此全局更新并行應(yīng)用于每個(gè)復(fù)制副本。該技術(shù)在數(shù)學(xué)上等效于使用原始全局小批量的單個(gè)GPU訓(xùn)練。雖然這種技術(shù)引入了一個(gè) all-reduce通信步驟,但這些開銷通常可以在模型執(zhí)行時(shí)間下重疊和隱藏。
All Gather和All Reduce通信模式通常用于數(shù)據(jù)并行和更廣泛的分布式DL。這些模式的目的是在不同的處理器上獲取單獨(dú)的數(shù)據(jù),然后將它們聚合并分發(fā)回處理器,這樣每個(gè)處理器現(xiàn)在都擁有相同數(shù)據(jù)的副本。all-together模式都使用一種算法,其中每個(gè)處理器將其數(shù)據(jù)傳送給其他每個(gè)處理器。如果每個(gè)處理器都有一個(gè)需要全局廣播的數(shù)據(jù)分區(qū),則通常會(huì)使用此方法。每個(gè)帶寬使用率高的處理器通常需要 個(gè)通信步驟——每個(gè)處理器必須與所有其他處理器進(jìn)行通信。All-reduce模式是All-together之上的一層,它將與一些reduction函數(shù)(例如總和、平均值)相結(jié)合。在同步過程中,運(yùn)行函數(shù)與運(yùn)行all-together然后運(yùn)行局部函數(shù)應(yīng)用程序相比,省去了一個(gè)步驟。例如,Horovod[50]實(shí)現(xiàn)了一個(gè)為數(shù)據(jù)并行梯度聚合的帶寬最優(yōu)reduce模式,其中每個(gè)處理器需要2×( ? 1) 個(gè)通信步驟完成完全的gather和educe。
混合并行是指將不同的并行策略結(jié)合起來以實(shí)現(xiàn)更高的整體性能的策略。例如,將數(shù)據(jù)并行性疊加在模型并行性之上,可以使用戶實(shí)現(xiàn)跨多個(gè)設(shè)備的內(nèi)存可擴(kuò)展性,同時(shí)加快數(shù)據(jù)并行性的執(zhí)行速度。這些策略需要在設(shè)計(jì)中進(jìn)行權(quán)衡。一個(gè)簡(jiǎn)單的覆蓋混合并行,模型并行性的多設(shè)備需求要乘以數(shù)據(jù)并行性的復(fù)制要求。任務(wù)并行性的進(jìn)一步疊加(例如,在多模型訓(xùn)練中)可以將另一個(gè)乘法因子添加到等式中。更復(fù)雜的混合可能會(huì)將數(shù)據(jù)并行應(yīng)用于模型并行體系結(jié)構(gòu)的某些階段,讓其他階段串行執(zhí)行,如圖所示。注意這個(gè)設(shè)計(jì)打開了新的“搜索空間”——數(shù)據(jù)并行復(fù)制應(yīng)該選擇哪些階段?模型并行分片決策如何影響數(shù)據(jù)并行性能?有限的資源應(yīng)該如何分配到各個(gè)階段,設(shè)備互連和拓?fù)浣Y(jié)構(gòu)如何影響性能?
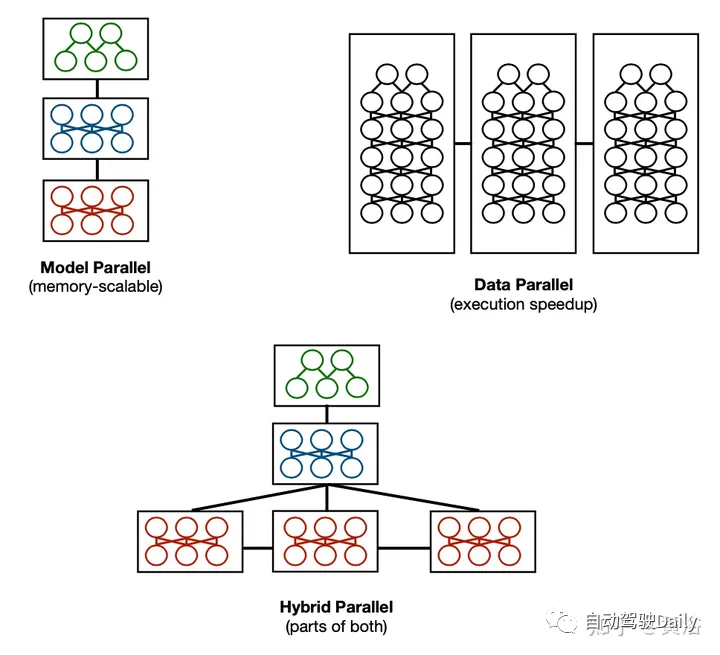
模型架構(gòu)的規(guī)模大致分為兩類——深度規(guī)模化和寬度規(guī)模化。深度規(guī)模化是像Transformers這樣的長(zhǎng)序列鏈架構(gòu)最常見的需求。寬度規(guī)模化通常用于非常寬、易于并行化的算子(例如表查找)。
模型并行等技術(shù)對(duì)于大型Transformer訓(xùn)練和一般的深度模型訓(xùn)練來說是必不可少的。然而,為非常深的模型啟用并行執(zhí)行可能具有挑戰(zhàn)性。對(duì)于一個(gè)深的層序列,最自然的分片策略是將序列劃分為子序列。但這種方法迫使用戶添加GPU,而實(shí)際上并沒有從任何性能優(yōu)勢(shì)中獲益——將序列劃分為子序列并不能提供任何并行執(zhí)行加速的機(jī)會(huì)。考慮一個(gè)萬億參數(shù)模型,它甚至需要使用1024個(gè)GPU才能適應(yīng)內(nèi)存。所有這些GPU都只是用于“啟用”執(zhí)行,并沒有提供任何性能優(yōu)勢(shì)。事實(shí)上,由于GPU間的通信成本,該策略可能比同等的內(nèi)存內(nèi)訓(xùn)練作業(yè)慢。
存在一些寬度分片(width-wise sharding)策略,例如跨多個(gè)GPU并行處理注意塊中的操作。然而,這些方法需要更多的定制,增加通信開銷,并且需要模型設(shè)計(jì)者付出大量的努力來實(shí)現(xiàn)。因此,大多數(shù)用于深度模型訓(xùn)練的系統(tǒng)更喜歡應(yīng)用可以針對(duì)所有深度模型類進(jìn)行優(yōu)化的廣義深度分片策略,而不是一次針對(duì)單個(gè)架構(gòu)。
盡管存在順序依賴性的挑戰(zhàn),但深度分片也可以帶來許多機(jī)會(huì)。流水線并行和溢出(spilling)等技術(shù)只適用于深度分片模型(depth-wise sharded models)。
在推薦模型中,嵌入表通常是寬度分片最受歡迎的候選者。大多數(shù)公司都使用基于嵌入的電子商務(wù)模型,這些公司收集特定實(shí)體的數(shù)據(jù)(如Meta、Netflix、TikTok)來創(chuàng)建定制的體驗(yàn)。一種標(biāo)準(zhǔn)的方法是創(chuàng)建一個(gè)表,將用戶ID映射到可訓(xùn)練向量,然后將這些向量饋送到頂部的其他DNN。然而,要想在Facebook這樣的數(shù)十億用戶平臺(tái)上運(yùn)行,相應(yīng)的表格必須非常寬。一個(gè)30億的索引表,大小為1024個(gè)可訓(xùn)練向量,填充單精度(32位)浮點(diǎn),需要12TB的內(nèi)存。真實(shí)世界的推薦模塊可能包括用于查找的多個(gè)表(例如,用戶表、業(yè)務(wù)表、視頻目錄表),這進(jìn)一步增加了內(nèi)存成本。
對(duì)嵌入表進(jìn)行分區(qū)是一項(xiàng)簡(jiǎn)單的任務(wù),因?yàn)楸淼牟檎沂遣⑿械摹粋€(gè)索引的查找不依賴于其他索引。因此,將表分配給不同GPU成為子表,是分配內(nèi)存成本的常見策略。跨片并行執(zhí)行,可以簡(jiǎn)單地將小批量中的索引查找請(qǐng)求路由到適當(dāng)?shù)腉PU。然而,為了在并行表查找之后重新聚合小批量饋送到頂部DNN,需要一個(gè)潛在的昂貴的all-together通信步驟。
將寬度分片應(yīng)用于其他算子(如矩陣乘法)并不常見,但也并非聞所未聞。但總的來說,嵌入表是內(nèi)存最密集的單個(gè)操作[9]。考慮到寬度分片的主要用例是嵌入表,針對(duì)這種情況進(jìn)行優(yōu)化可能顯得過于特殊。然而,嵌入表和推薦模型在DL工作負(fù)載中占了很大比例——Meta報(bào)告稱,他們50%的DL訓(xùn)練周期都花在了基于嵌入表的推薦模型上[9]。因此,優(yōu)化非常廣泛的模型情況是非常值得的,即使適用性比序貫深度模型可擴(kuò)展性的優(yōu)化更有限。
如圖對(duì)不同訓(xùn)練系統(tǒng)和技術(shù)進(jìn)行比較:
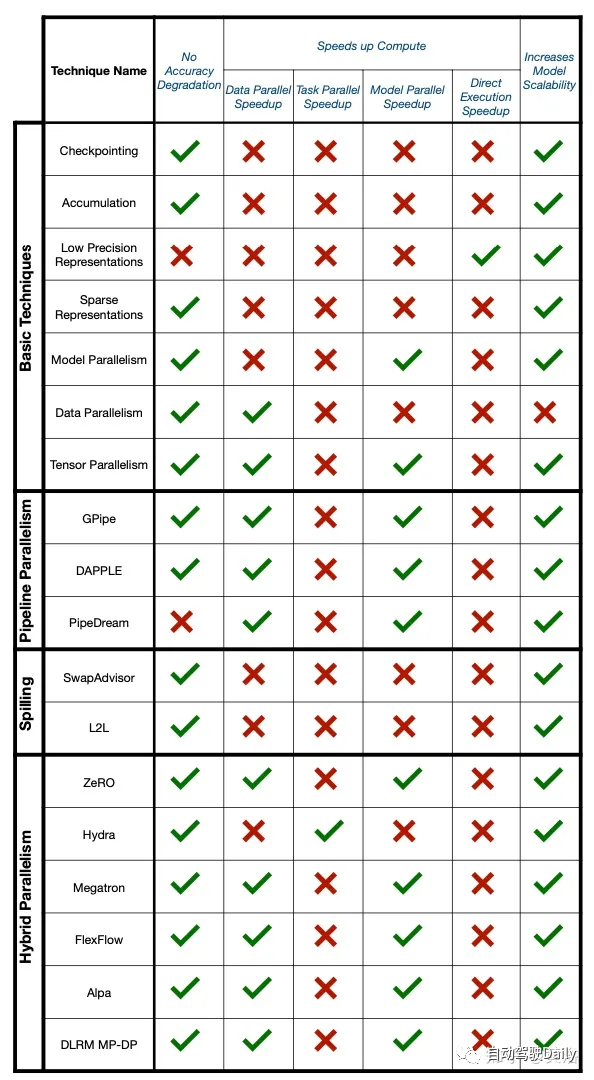
一些基本技術(shù),如再具體化,通常被用作更先進(jìn)大型模型訓(xùn)練系統(tǒng)的常見構(gòu)建塊。一般來說,這些技術(shù)對(duì)組織和結(jié)構(gòu)的影響很小,可以與其他方法集成。
再具體化,也稱為梯度檢查點(diǎn),試圖最大限度地減少反向傳播的內(nèi)存需求[15,19]。反向傳播需要保存中間算子輸出,以便正確應(yīng)用梯度計(jì)算的鏈?zhǔn)揭?guī)則。然而,中間輸出張量可能需要大量?jī)?nèi)存!一些分析[54]表明,激活占ResNet[22]內(nèi)存消耗的95%,占某些Transformer內(nèi)存使用的80%。最初先丟棄除少數(shù)檢查點(diǎn)之外的大多數(shù)激活,用檢查點(diǎn)重新計(jì)算反向傳播過程中丟棄的激活,再具體化以計(jì)算換取內(nèi)存。通過這種方式,在任何給定點(diǎn),只有檢查點(diǎn)之間的中間點(diǎn)需要存儲(chǔ)在內(nèi)存中。這種方法確實(shí)會(huì)產(chǎn)生計(jì)算開銷——前向傳播有效地進(jìn)行了兩次。然而,前向傳播中的算子通常比反向傳播中使用的自動(dòng)微分程序更快,因此開銷比看起來更小。一些梯度檢查點(diǎn)系統(tǒng)聲稱只有30%的開銷,可以節(jié)省6-7X內(nèi)存[15]。
累積,是針對(duì)反向傳播中分批梯度的內(nèi)存需求而言[25]。隨機(jī)梯度下降將樣本分批放入模型饋送的小批量中,反過來可以將參數(shù)更新生成的梯度視為每個(gè)樣本更新的聚合。累積延遲了這些聚合梯度的應(yīng)用,而是計(jì)算新的小批量梯度更新,并將它們累積到聚合梯度向量上。新梯度現(xiàn)在是2個(gè)小批量更新的總和,而不是1個(gè)。通過這種方式,可以擴(kuò)大有效的小批量大小和梯度影響,而無需實(shí)際訓(xùn)練更大的批量。將較小的單個(gè)批次稱為微批次(micro batch),并將有效的合計(jì)批次稱為小批次(mini-batch)。累積對(duì)于流水線并行性至關(guān)重要,并且經(jīng)常與其他技術(shù)結(jié)合使用。
大多數(shù)訓(xùn)練框架(例如TensorFlow、PyTorch)[8,42]使用梯度和參數(shù)的單精度浮點(diǎn)(32位)表示。雙精度表示(64位)相對(duì)不常見。減少訓(xùn)練模型的內(nèi)存需求的一種方法是使用數(shù)據(jù)的半精度(16位)表示,即低精度表征。自然地,當(dāng)數(shù)值被近似時(shí),這會(huì)導(dǎo)致精度損失[38]。然而,這種方法可以提供加速和內(nèi)存節(jié)省。為了嘗試和平衡這一點(diǎn),自動(dòng)混合精度(AMP)[3]將自動(dòng)嘗試并確定何時(shí)可以安全地將數(shù)據(jù)壓縮到16位,而不會(huì)造成精度損失。AMP在訓(xùn)練大型模型時(shí),精度損失很少甚至沒有損失,同時(shí)實(shí)現(xiàn)了高達(dá)5.5X的加速[3]。由于AMP直接在非常低的級(jí)別修改數(shù)值,因此該技術(shù)通常與用于大模型訓(xùn)練的實(shí)際系統(tǒng)方法正交。
在某些情況下,DL訓(xùn)練中使用的向量非常稀疏。例如,嵌入表查找通常只涉及表的幾個(gè)索引。應(yīng)用于表的梯度向量將僅在使用的索引處具有非零值,而其余部分置零。實(shí)際上,在內(nèi)存中保留所有這些零是不必要的,并且會(huì)浪費(fèi)內(nèi)存。稀疏表示試圖將這些向量壓縮直至非零值,同時(shí)避免任何信息丟失。默認(rèn)情況下,通常用于嵌入表的最簡(jiǎn)單方法是將梯度表示為將索引映射到梯度值的K-V對(duì)。當(dāng)將稀疏表示與假設(shè)標(biāo)準(zhǔn)向量表示的操作相結(jié)合時(shí),會(huì)出現(xiàn)一些復(fù)雜情況,例如all-reduce通信模式。一些工作[35]展示了如何通過替代通信模式或?qū)?shù)據(jù)轉(zhuǎn)換回標(biāo)準(zhǔn)表示來解決這一問題。稀疏向量表示解決了一個(gè)非常具體的問題,但對(duì)于一些算子(如寬嵌入表)的有效訓(xùn)練至關(guān)重要。
流水線并行性針對(duì)“序列深度模型”設(shè)置[25]。它是模型并行訓(xùn)練范式的直接擴(kuò)展。模型并行性創(chuàng)建一個(gè)分階段的片序列,創(chuàng)建一個(gè)自然的“流水線”結(jié)構(gòu)。流水線只是通過嘗試用執(zhí)行操作填充階段來利用這種流水線結(jié)構(gòu),從而減少純序列模型并行性中存在的空閑。每片都可以被視為流水線的一個(gè)階段,因此一個(gè)在三個(gè)GPU上三次分區(qū)的模型現(xiàn)在是一個(gè)三階段流水線。
在CPU流水線中,用發(fā)送到CPU的各種指令填充流水線[52]。對(duì)于DL流水線,用微批次填充流水線,就像在梯度累積中一樣[25,27]。從本質(zhì)上講,流水線并行是梯度累積和模型并行的結(jié)合。獨(dú)立的微批次在分片流水線中穿梭,然后為每個(gè)流水線階段積累每個(gè)微批次的梯度。一旦整個(gè)小批次(所有微批次的組合)的梯度全部聚合,就可以將其應(yīng)用于模型。這種設(shè)計(jì)幾乎就像一個(gè)模型-并行-數(shù)據(jù)-并行的混合,其中數(shù)據(jù)片是并行處理的,但在不同的模型-并行片上。如圖對(duì)此進(jìn)行了說明:輸入的小批次被劃分為微批次,然后在流水線階段中運(yùn)送。, 指的是帶有小批量 的片 前階段, 雖然 , 指的是小批量 的片 后階段, 通過這種方式,實(shí)現(xiàn)了一種“流水線式”數(shù)據(jù)并行,即在不同的模型并行級(jí)之間并行處理數(shù)據(jù)。請(qǐng)注意,在反向傳播之前,必須清除正向流水線。

反向傳播對(duì)流水線并行訓(xùn)練提出了挑戰(zhàn)。中間輸出必須可用于反向傳播。然而,當(dāng)與累積相結(jié)合時(shí),這將要求為每個(gè)微批次存儲(chǔ)不同的中間輸出集,從而剝奪了累積提供的任何可擴(kuò)展性優(yōu)勢(shì)。GPipe[25]是最早的流水線并行訓(xùn)練系統(tǒng)之一,提出了將累積與檢查點(diǎn)相結(jié)合來解決這個(gè)問題。激活將僅存儲(chǔ)在片/流水線階段的綁定中,在反向傳播過程中,隨著梯度在流水線中向后移動(dòng),將進(jìn)行重新計(jì)算。檢查點(diǎn)方法現(xiàn)在是大多數(shù)(如果不是全部的話)流水線并行訓(xùn)練系統(tǒng)的標(biāo)準(zhǔn)方法[21]。另一個(gè)挑戰(zhàn)是流水線的結(jié)構(gòu)。片流水線必須是雙向的。輸入和激活在預(yù)測(cè)期間向前流動(dòng),梯度在反向傳播期間向后流動(dòng)。這導(dǎo)致了一個(gè)問題——流水線中的數(shù)據(jù)在兩個(gè)方向上流動(dòng)時(shí)會(huì)在階段“碰撞”。因此,在預(yù)測(cè)和反向傳播之間會(huì)發(fā)生流水線沖洗(flush)。如果管理不當(dāng),沖洗可能會(huì)嚴(yán)重影響性能。上圖展示了一個(gè)流水線并行化模型。請(qǐng)注意,很大一部分時(shí)間都花在了“氣泡”期,即必須完全沖洗流水線的時(shí)間。
主要的流水線并行技術(shù)如下。
GPipe[25]建議在保持加速器計(jì)數(shù)不變的同時(shí)增加微批次的數(shù)量,這樣流水線可以更長(zhǎng)時(shí)間保持滿狀態(tài)。這不會(huì)消除沖洗,但會(huì)提高整體效率。然而,這種方法將需要更多的內(nèi)存來存儲(chǔ)很多具備檢查點(diǎn)的微批次激活。DAP-PLE[17]提出了一種可替代的流水線調(diào)度,該調(diào)度可以保持GPipe的收斂行為,但空閑時(shí)間較少。不幸的是,它還同時(shí)保持更多的微批次“活躍”而大幅增加了內(nèi)存成本,這使得調(diào)度對(duì)于已經(jīng)突破內(nèi)存邊界的應(yīng)用程序來說是不可行的。
異步流水線并行的形式還有另一種解決方案,以保持嚴(yán)格的收斂行為為代價(jià),重新排列流水線階段和反向傳播以消除沖洗。這種序列的“解耦”將問題放松為更有效的——以影響數(shù)據(jù)消費(fèi)和消費(fèi)順序?yàn)榇鷥r(jià)[21,32,39,59]。例如,PipeDream[21]提出的1F1B模式,為每個(gè)后階段(在不同的微批次上)運(yùn)行一個(gè)前階段,保持完美的比例和利用率。但它的設(shè)計(jì)需要更仔細(xì)的分區(qū)和打包,而緩解陳舊權(quán)重更新導(dǎo)致的準(zhǔn)確性下降,需要存儲(chǔ)多個(gè)權(quán)重副本[21],從而增加了內(nèi)存成本。雖然像1F1B這樣的異步流水線可以很好地執(zhí)行,但它并不是一個(gè)通用的解決方案——精度損失是特定情況下的,通常可能是巨大的。精度至關(guān)重要且收斂行為必須可復(fù)制(例如模型選擇)的應(yīng)用程序不適合異步流水線并行。
雖然模型并行性著眼于在多個(gè)GPU上執(zhí)行分布內(nèi)存需求,但一些系統(tǒng)試圖利用主系統(tǒng)內(nèi)存(DRAM),而不是在更多GPU上橫向擴(kuò)展。這種方法的主要?jiǎng)訖C(jī)是,雖然GPU內(nèi)存有限且昂貴,但DRAM實(shí)際上更便宜且可訪問。
最初的工作[23,30,34,49,56]將卸載(offloading)視為一個(gè)“交換”問題——決定何時(shí)將張量從GPU內(nèi)存交換到DRAM上。大多數(shù)使用圖分析算法來確定在哪里“注入”交換操作,這取決于激活、梯度或參數(shù)下一次可能在執(zhí)行圖(execution graph)中使用的時(shí)間。SwapAdvisor是這些交換系統(tǒng)中最先進(jìn)的,它使用并行遺傳搜索算法來分析交換算子應(yīng)該放在哪里以獲得最佳性能。它也是最早支持卸載參數(shù)和激活的系統(tǒng)之一,這對(duì)于訓(xùn)練十億參數(shù)模型架構(gòu)至關(guān)重要。
這些復(fù)雜的交換過程可能很難設(shè)置——SwapAdvisor的搜索算法大約需要一個(gè)小時(shí)才能完成。此外,它們很難擴(kuò)展到多GPU訓(xùn)練,因?yàn)闆]有明確的方法來擴(kuò)展交換注入圖的技術(shù)來覆蓋多GPU并行性。
ZeRO-R[46]提出了另一種方法,這是一種向DRAM動(dòng)態(tài)發(fā)送激活和參數(shù)的卸載系統(tǒng)。這種方法“在需要時(shí)卸載”,而不是預(yù)先計(jì)劃卸載。設(shè)計(jì)的不規(guī)則性可能會(huì)引入內(nèi)存碎片等問題,但與基于圖的設(shè)計(jì)相比,它增加了很大的靈活性。在后來的版本中,ZeRO Infinity[47]將其擴(kuò)展到卸載到非易失性快速存儲(chǔ)(NVMe)/磁盤存儲(chǔ),實(shí)現(xiàn)進(jìn)一步的可擴(kuò)展性。
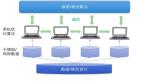
Hydra[37]選擇了“獨(dú)立塊”策略,將模型體系結(jié)構(gòu)劃分為子模型(如模型并行)然后可以在DRAM和GPU存儲(chǔ)器之間自由地溢出。可以將其與RDBMS中的溢出進(jìn)行類比,在RDBMS中,獨(dú)立的數(shù)據(jù)塊可以向下發(fā)送到較低級(jí)別的內(nèi)存。與其他溢出系統(tǒng)不同,Hydra的執(zhí)行模式與模型并行性相同,并完全分離每個(gè)模型片的執(zhí)行。它仍然試圖重疊通信和計(jì)算,但忽略了其他CPU卸載技術(shù)所探索的細(xì)粒度張量卸載的復(fù)雜性。這種泛化使其不太適合單GPU執(zhí)行,但使其更適合與多GPU并行化技術(shù)混合。
如圖所示:Hydra的溢出策略只是簡(jiǎn)單地提升和降級(jí)進(jìn)出GPU內(nèi)存的模型并行分片。其他溢流設(shè)計(jì),如ZeRO Offload使用的,雖然結(jié)構(gòu)不太嚴(yán)格,但也類似。

L2L[45]使用了類似于Hydra的設(shè)計(jì),但在其分片方法上受到了更多限制。它專門針對(duì)Transformer架構(gòu),并將自注意塊(標(biāo)準(zhǔn)Transformer運(yùn)算器)與專門為其目標(biāo)模型類選擇的啟發(fā)式方法進(jìn)行交換。這使它能夠在Transformer架構(gòu)上表現(xiàn)出色,但無法實(shí)現(xiàn)Hydra的靈活性或ZeRO-R的動(dòng)態(tài)通用性。
請(qǐng)注意,這些技術(shù)通常用于深度大模型分布其內(nèi)存需求,因?yàn)樗鼈冊(cè)趫?zhí)行中都利用了某種次序。一個(gè)非常寬的算子(例如嵌入表)如果沒有性能的大幅降低就無法串行化,也不容易在DRAM和GPU內(nèi)存中溢出。寬算子在混合設(shè)備執(zhí)行的唯一選項(xiàng)是串行化并行算子(在表的情況下即索引查找),并將一系列操作重寫為一個(gè)深度,而不是寬闊的模型,或者在CPU上實(shí)際執(zhí)行寬闊算子。
有些系統(tǒng)更甚,實(shí)際上是在CPU上執(zhí)行操作。通常,最好完全使用GPU或TPU計(jì)算來運(yùn)行模型,因?yàn)榇蠖鄶?shù)DL操作符在支持高度并行的加速器上運(yùn)行得更快。然而,通過卸載,數(shù)據(jù)無論如何都會(huì)在CPU上——因此,GPU操作并行地執(zhí)行CPU操作不應(yīng)增加開銷。
ZeRO[48]提出在GPU執(zhí)行期間在CPU上運(yùn)行參數(shù)更新,特別是針對(duì)流行的Adam優(yōu)化器[28]。Adam優(yōu)化器保存一些狀態(tài)參數(shù)(通常是32位),需要在32位參數(shù)上運(yùn)行以避免精度下降。不幸的是,這阻止了用戶為了減少內(nèi)存需求而部署16位表示的工作。Adam優(yōu)化器的ZeRO版本在DRAM上保持32位版本的參數(shù),在GPU上保持低精度的16位版本,消耗更少的內(nèi)存。在執(zhí)行過程中,系統(tǒng)將梯度和優(yōu)化器狀態(tài)溢出到DRAM上,然后使用CPU處理對(duì)32位參數(shù)運(yùn)行參數(shù)更新。在與CPU-GPU通信和GPU計(jì)算重疊的第二步驟中,更新被傳播到16位參數(shù)。
混合CPU-GPU計(jì)算在非常大的推薦模型中也很常見。嵌入表是非常廣泛的內(nèi)存密集型算子,通常會(huì)輸入一些較小的DNN進(jìn)行進(jìn)一步處理。如果沒有任何優(yōu)化,嵌入表的龐大規(guī)模將迫使只執(zhí)行CPU[9]。或者,用戶可以將嵌入表放置在CPU上,而DNN位于GPU內(nèi)存中,并享受GPU加速的好處。一些工作,如Hotline[10]嘗試和流水線數(shù)據(jù)通過模型,從基于CPU的嵌入表到GPU加速的DNN。他們證明,這種混合計(jì)算方法甚至可以比寬度方向的多GPU模型并行更快,因?yàn)樗薬ll-to-all通信步驟的需求。
并行化技術(shù)可以以不同的方式進(jìn)行組合。各種系統(tǒng)試圖將各種“基本”并行方法(如數(shù)據(jù)并行、模型并行)的優(yōu)點(diǎn)結(jié)合起來,為用戶提供更高的性能和可擴(kuò)展性。混合并行技術(shù)可以分為兩大類——“真正的”混合,從底層開始集成并行技術(shù),以及自上而下的混合,在不同的執(zhí)行階段選擇不同的策略。
接地式混合
傳統(tǒng)上,從一開始就將模型并行性與其他技術(shù)相結(jié)合是一項(xiàng)具有挑戰(zhàn)性的任務(wù)。模型并行性提高了GPU對(duì)標(biāo)準(zhǔn)執(zhí)行的要求,這可能會(huì)使與基于復(fù)制或多實(shí)例的并行技術(shù)(如數(shù)據(jù)并行性、任務(wù)并行性)的組合變得不切實(shí)際,因?yàn)樗鼈冞M(jìn)一步擴(kuò)大了模型并行性的設(shè)備要求。
為了解決這個(gè)問題,Hydra[37]建議使用溢出技術(shù)來減少可擴(kuò)展模型并行訓(xùn)練所需的GPU數(shù)量,然后在頂部應(yīng)用任務(wù)并行性一層來支持高效的多模型訓(xùn)練。然后,Hydra系統(tǒng)利用模型并行性的分段特性,實(shí)現(xiàn)混合的“細(xì)粒度并行”日程,可以優(yōu)于標(biāo)準(zhǔn)的任務(wù)并行性和模型并行。如圖對(duì)此進(jìn)行了說明。目前,Hydra是唯一一個(gè)明確針對(duì)大模型設(shè)置多模型的系統(tǒng),但隨著從業(yè)者努力解決模型選擇和多用戶集群管理的成本,這一領(lǐng)域的重要性可能會(huì)增加。

最初由ZeRO[46]引入的完全分片數(shù)據(jù)并行性(FSDP,F(xiàn)ully Sharded Data Parallelism)提供了模型并行性和數(shù)據(jù)并行性的混合。與Hydra不同的是,Hydra仍然以模型并行分片的方式執(zhí)行,F(xiàn)SDP只使用模型并行性將模型分布在數(shù)據(jù)并行的實(shí)例上,每個(gè)數(shù)據(jù)并行克隆都持有一個(gè)層組的部分參數(shù)集。當(dāng)執(zhí)行一個(gè)層組時(shí),F(xiàn)SDP運(yùn)行一個(gè)all-together步驟,在每個(gè)數(shù)據(jù)并行實(shí)例上生成完整的、未分片的層組。然后層組以純數(shù)據(jù)并行方式執(zhí)行。在執(zhí)行該層之后,可以立即對(duì)其進(jìn)行重新丟棄,重新分配內(nèi)存占用空間。反向傳播也采用了類似的方法。
在FSDP中,每個(gè)加速器的內(nèi)存需求,減少到單層的最小footprint加上其余部分的分區(qū)內(nèi)存需求。將單層需求分解為一個(gè)常數(shù)因子,可以將其表示為 ( / )減少,其中 是原始模型內(nèi)存占用, 是數(shù)據(jù)并行實(shí)例的數(shù)量。這使得用戶能夠同時(shí)受益于數(shù)據(jù)并行性的性能和模型并行性的可擴(kuò)展性。請(qǐng)注意,這確實(shí)增加了大量的通信開銷——對(duì)每一層都運(yùn)行all-gather——而且與基于溢出的技術(shù)不同,這仍然需要橫向擴(kuò)展以實(shí)現(xiàn)可擴(kuò)展性。
ZeRO Offload[48]提出將FSDP與每個(gè)加速器溢出相結(jié)合,卸載在近期不會(huì)使用的分片層參數(shù)。這提供了更好的可擴(kuò)展性,但通過CPU-GPU通信引入了更多的通信開銷。ZeRO的工作是將通信與計(jì)算重疊,但一些速度減慢通常是不可避免的。分析表明,F(xiàn)SDP比標(biāo)準(zhǔn)數(shù)據(jù)并行性慢(盡管更具可擴(kuò)展性,并且能夠運(yùn)行更大的模型)。FSDP的支持者聲稱,用戶可以利用其更高的可擴(kuò)展性來增加批次大小(從而使執(zhí)行時(shí)間與分布數(shù)據(jù)并行DDP性能保持一致),但批次大小會(huì)影響準(zhǔn)確性收斂行為。為了獲得更好的FSDP性能而規(guī)模化批次大小,可能會(huì)導(dǎo)致與異步流水線相同的問題(盡管不那么極端)。3D并行性將FSDP與流水線并行性和張量并行性相結(jié)合,利用可擴(kuò)展的數(shù)據(jù)并行性以及并行的深度和寬度分片執(zhí)行操作。通常采取的形式,是在模型的某些部分應(yīng)用FSDP,在另一個(gè)部分應(yīng)用流水線,在更適合寬度分片的另一個(gè)分段中應(yīng)用張量并行。3D并行通常需要基于模型架構(gòu)進(jìn)行大量定制——它不能像Hydra或FSDP那樣開箱即用。也就是說,它已經(jīng)使用Megatron[53]等系統(tǒng)成功地應(yīng)用于許多非常大規(guī)模的模型的訓(xùn)練,如Megatron-LM[5]和BLOOM[12]。未來,將3D并行混合與Hydra的分片任務(wù)并行相結(jié)合,一種新的“4D并行”成為可能。
策略發(fā)現(xiàn)
策略發(fā)現(xiàn)系統(tǒng)試圖自動(dòng)化在模型中組合并行化技術(shù)的過程。最近的幾個(gè)例子是FlexFlow[26]和Alpa[60]。
FlexFlow是在開發(fā)高級(jí)DL并行技術(shù)(如流水線并行、FSDP和分片任務(wù)并行)之前構(gòu)建的,它只探索數(shù)據(jù)、張量和模型并行,主要針對(duì)卷積神經(jīng)網(wǎng)絡(luò)。FlexFlow構(gòu)建了一個(gè)設(shè)備拓?fù)鋱D,將加速器建模為節(jié)點(diǎn),將互連(例如NVLink、PCIe、Infiniband網(wǎng)絡(luò))建模為邊緣。這允許它產(chǎn)生混合并行執(zhí)行策略,該策略考慮了給定設(shè)備配置中邊緣之間的數(shù)據(jù)移動(dòng)成本。它使用模擬器來評(píng)估不同的劃分策略,使用試點(diǎn)通道(pilot passes)來建模運(yùn)營(yíng)商運(yùn)行時(shí)間,并基于邊緣帶寬進(jìn)行理論計(jì)算來建模通信開銷。使用模擬器作為啟示(oracle),它評(píng)估了劃分算子的不同方法。請(qǐng)注意,這種基于“分割”的并行表示不能支持在不同任務(wù)上利用獨(dú)立執(zhí)行的并行化技術(shù)(例如任務(wù)并行、流水線并行),盡管它可能支持FSDP。此外,它沒有明確說明內(nèi)存的可擴(kuò)展性或在特定配置中設(shè)備內(nèi)存耗盡的可能性[11]。
Alpa更明確地考慮了內(nèi)存可擴(kuò)展性,并考慮了算子間的并行性(例如,模型并行性、流水線并行性),而不僅僅是像FlexFlow那樣的算子內(nèi)分割。它使用指令級(jí)并行(ILP)公式來確定如何設(shè)置并行化策略,然后該階段將超過設(shè)備內(nèi)存限制時(shí)修改執(zhí)行規(guī)劃[60]。占據(jù)更廣闊的策略搜索空間,這種方法可以實(shí)現(xiàn)比FlexFlow更好的性能。
這些混合并行化策略非常適合靜態(tài)的、非數(shù)據(jù)依賴的執(zhí)行任務(wù)(例如非遞歸神經(jīng)網(wǎng)絡(luò))。然而,它們不能很好地?cái)U(kuò)展到更動(dòng)態(tài)的任務(wù),如多模型訓(xùn)練——它們是用于訓(xùn)練的編譯器,而不是調(diào)度器。未來的工作可以考慮彌合這一差距,構(gòu)建一個(gè)動(dòng)態(tài)混合并行執(zhí)行器。
推薦模型的模型數(shù)據(jù)并行性
DLRM給從業(yè)者帶來了獨(dú)特的挑戰(zhàn),因?yàn)樗鼈兘Y(jié)合了兩種不同的擴(kuò)展挑戰(zhàn)。嵌入表是非常明智的,并且保證了模型并行執(zhí)行的寬度分割。頂級(jí)DNN是計(jì)算密集型的,但規(guī)模較小,并且將從數(shù)據(jù)并行性中獲益最多。因此,將張量并行性應(yīng)用于模型的表格,并將數(shù)據(jù)并行性應(yīng)用到DNN,這種混合策略將在推薦模型上表現(xiàn)良好。這種方法已成為完全GPU加速DLRM訓(xùn)練的標(biāo)準(zhǔn)[41],盡管異構(gòu)CPU-GPU執(zhí)行也適用于訪問GPU資源較少的用戶。
混合并行DLRM訓(xùn)練在多個(gè)GPU上劃分嵌入表,并在每個(gè)GPU上放置頂部DNN的局部副本。分片的表處理在樣本維度上分片的輸入,然后運(yùn)行分區(qū)的all-gather來重新聚集表輸出,并在批次維度上為每個(gè)數(shù)據(jù)并行副本進(jìn)行分區(qū)。如圖對(duì)此進(jìn)行了說明。

這種方法使從業(yè)者能夠從神經(jīng)架構(gòu)中的數(shù)據(jù)和模型并行性中受益。通信步驟是密集的,通常會(huì)帶來沉重的開銷[35],但并行執(zhí)行的好處通常會(huì)超過這一點(diǎn)。
總的來說,混合并行性在適當(dāng)?shù)臅r(shí)候結(jié)合不同并行化策略的優(yōu)點(diǎn),為用戶提供了高效訓(xùn)練模型的能力。混合并行技術(shù),如分片任務(wù)并行和FSDP,從一開始就結(jié)合了可擴(kuò)展性和效率,而策略發(fā)現(xiàn)和DLRM混合并行可以幫助訓(xùn)練模型架構(gòu),其在這個(gè)圖的不同階段具有混合并行需求。

原文鏈接:https://mp.weixin.qq.com/s/vMg0vH4Vb_8pMUcGEWz8_w