十年雙11:阿里數據庫變遷“三部曲”
2018 年,雙 11 迎來了十周年。十年間,依賴于迅速崛起的互聯網技術以及各項新興技術的沉淀,阿里巴巴締造了全球數字經濟時代的第一“操作系統”。
在這個操作系統上,讓全球消費者和商家買、賣、逛、聽、看、游得順心、放心、舒心。
十年間,阿里巴巴的技術同學和全球開發者們,一起把互聯網前沿技術轉化為全球消費者、全球數字經濟參與者可以感知的便利。
如今,它已不僅僅是全球消費者的狂歡節,更是名副其實的全球互聯網技術的演練場。
從“雙 11 的技術”到“技術的雙 11”,每一次化“不可能”為“可能”的過程,都是阿里人對技術的不懈追求。
在第十個雙 11 來臨之際,有幸邀請到參與多年雙 11 備戰的核心技術大牛——雙11技術保障部大隊長、數據庫事業部研究員張瑞,通過這篇萬字長文,帶領大家回顧雙 11 這十年來數據庫領域的技術變遷。
十年使命:推動中國數據庫技術變革
再過幾天,我們即將迎來第十個雙 11。過去十年,阿里巴巴技術體系的角色發生了轉變,從雙 11 推動技術的發展,變成了技術創造新商業。
很多技術通過云計算開始對外輸出,變成了普惠的技術,服務于各個行業,真正做到了推動社會生產力的發展。
這十年,阿里巴巴數據庫團隊一直有一個使命:推動中國數據庫技術變革。從商業數據庫到開源數據庫再到自研數據庫,我們一直在為這個使命而努力奮斗。
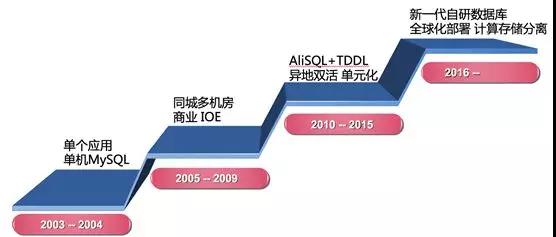
如果將阿里數據庫發展歷史分為三個階段的話,分別是:
- 2005 年-2009 年:商業數據庫時代。
- 2010 年-2015 年:開源數據庫時代。
- 2016 年-至今:自研數據庫時代。
商業數據庫時代就是大家所熟知的 IOE 時代,后來發生了一件大事就是“去 IOE”。
通過分布式數據庫中間件 TDDL、開源數據庫 AliSQL(阿里巴巴的 MySQL 分支)、高性能 X86 服務器和 SSD,并通過 DBA 和業務開發同學的共同努力,成功地替換了商業數據庫 Oracle、IBM 小型機和 EMC 高端存儲,從此進入了開源數據庫時代。
去 IOE 帶來了三個重大的意義:
- 解決了擴展性的問題,讓數據庫具備了橫向擴展(彈性)的能力,為未來很多年雙11零點交易峰值打下了很好的基礎。
- 自主可控,我們在 AliSQL 中加入了大量的特性,比如:庫存熱點補丁,SQL 限流保護,線程池等等,很多特性都是來源于雙 11 對于數據庫的技術要求,這在商業數據庫時代是完全不可能的。
- 穩定性,原來在商業數據庫時代,就如同把所有的雞蛋放在一個籃子里(小型機),去 IOE 之后不僅僅解決了單機故障,更是通過異地多活的架構升級讓數據庫跨出了城市的限制,可以實現數據庫城市間的多活和容災,大大提升了系統的可用性。
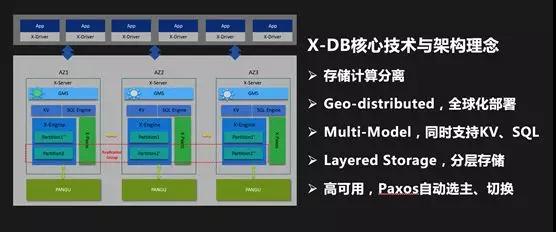
進入 2016 年,我們開始自研數據庫,代號 X-DB。大家一定會問:為什么要自研數據庫?有以下幾個原因:
- 我們需要一個能夠全球部署的原生分布式數據庫,類似于 Google Spanner。
- 雙 11 的場景對數據庫提出了極高的要求:在雙 11 零點需要數據庫提供非常高的讀寫能力。
數據庫使用 SSD 來存儲數據,而數據存在明顯的冷熱特性,大量冷的歷史數據和熱的在線數據存放在一起,日積月累,占用了大量寶貴的存儲空間,存儲成本的壓力越來越大。
- 我們經過認真評估后發現,如果繼續在開源數據庫基礎上進行改進已經無法滿足業務需求。
- 新的硬件技術的出現,如果說 SSD 的大規模使用和 X86 服務器性能的極大提升推動了去 IOE 的進程,那么NVM非易失內存,FPGA 異構計算,RDMA 高速網絡等技術將第二次推動數據庫技術的變革。
伴隨著每一年的雙 11 備戰工作,機器資源的準備都是非常重要的一個環節。如何降低雙 11 的機器資源成本一直是阿里技術人不斷挑戰自我的一個難題。
第一個解決方案就是使用云資源,數據庫從 2016 年初開始就嘗試使用高性能 ECS 來解決雙 11 的機器資源問題。
通過這幾年的雙 11 的不斷磨練,2018 年雙 11,我們可以直接使用公有云 ECS,并通過 VPC 網絡與阿里巴巴集團內部環境組成混合云,實現了雙 11 的彈性大促。
第二個方案就是在線離線混部,日常讓離線任務跑在在線(應用和數據庫)的服務器上,雙 11 大促在線應用使用離線的計算資源,要實現這種彈性能力,數據庫最核心要解決一個技術問題就是:存儲計算分離。
存儲計算分離后,數據庫可以在雙 11 使用離線的計算資源,從而實現極致的彈性能力。通過使用云資源和混部技術,可以最大程度降低雙 11 交易峰值帶來的成本。

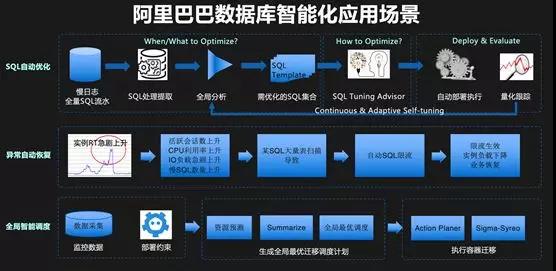
雙 11 備戰中另外一個重要的技術趨勢就是:智能化。數據庫和智能化相結合也是我們一直在探索的一個方向,比如 Self-driving Database 等。
2017 年,我們第一次使用智能化的技術對 SQL 進行自動優化,2018 年,我們計劃全網推廣 SQL 自動優化和空間自動優化,希望可以使用這些技術降低 DBA 的工作負擔,提升開發人員效率,并有效提升穩定性。
相信未來,在雙 11 的備戰工作中,會有越來越多的工作可以交給機器來完成。
我從 2012 年開始參加雙 11 的備戰工作,多次作為數據庫的隊長和技術保障部總隊長,在這么多年的備戰工作中,我也經歷了很多有意思的故事,在這里分享一些給大家。
2012 年:我的第一次雙 11
2012 年是我的第一次雙 11,在此之前,我在 B2B 的數據庫團隊,2012 年初,整個集團的基礎設施團隊都合并到了技術保障部,由振飛帶領。
我之前從來沒有參加過雙 11,第一年參加雙 11 后羿(數據庫團隊的負責人)就把隊長的職責給了我,壓力可想而知。
那時候備戰雙 11 的工作非常長,大概從 5、6 月份就開始準備了,最重要的工作就是識別風險,并準確評估出每個數據庫的壓力。
我們需要把入口的流量轉換為每個業務系統的壓力 QPS,然后我們根據業務系統的 QPS 轉換為數據庫的 QPS。
2012 年還沒有全鏈路壓測的技術,只能靠每個業務系統的線下測試,以及每個專業線隊長一次又一次的開會 Review 來發現潛在的風險。
可想而知,這里面存在巨大的不確定性,每個人都不想自己負責的業務成為短板,而機器資源往往是有限的,這時,就完全靠隊長的經驗了,所以,每個隊長所承擔的壓力都非常巨大。
我記得當年雙 11 的大隊長是李津,據說他當時的壓力大到無法入睡,只能在晚上開車去龍井山頂,打開車窗才能小憩一會。
而我,由于是第一年參加雙 11,經驗為零,完全處于焦慮到死的狀態,幸好當年有一群很靠譜的兄弟和我在一起。
他們剛剛經歷了去 IOE 的洗禮,并且長期與業務開發浸淫在一起,對業務架構和數據庫性能如數家珍,了若指掌。
通過他們的幫助,我基本摸清了交易整套系統的架構,這對我未來的工作幫助非常大。
經過幾個月緊張的準備,雙 11 那天終于到來了,我們做好了最充分的準備,但是一切都是那么地不確定。
我們懷著忐忑不安的心情,當零點到來的時候,最壞的情況還是發生了:庫存數據庫的壓力完全超過了容量,同時 IC(商品)數據庫的網卡也被打滿了。
我記得很清楚,當時我們看著數據庫上的監控指標,束手無策。這里有一個小細節:由于我們根本沒有估算到這么大的壓力,當時監控屏幕上數據庫的壓力指標顯示超過了 100%。
正在這時,技術總指揮李津大喊一聲:“大家都別慌!”這時我們才抬頭看到交易的數字不斷沖上新高,心里才稍微平靜下來。
事實上,對于 IC 數據庫網卡被打滿,庫存數據庫超過容量,都超出了我們的預期,所以最終我們什么預案也沒做,就這樣度過了零點的高峰。
因為這些原因,2012 年的的雙 11 產生了大量的超賣,給公司帶來了很大的損失。
那一年的雙 11 后,庫存、商品、退款和相應數據庫的同學,為了處理超賣導致的問題,沒日沒夜加了兩周的班。
而且,我周圍很多朋友,都在抱怨高峰時的用戶體驗實在太糟糕了。我們下決心要在第二年的雙 11 解決這些問題。
2013 年:庫存熱點優化和不起眼的影子表
2012 年的雙 11 結束后,我們就開始著手解決庫存數據庫的性能提升。
庫存扣減場景是一個典型的熱點問題,即多個用戶去爭搶扣減同一個商品的庫存(對數據庫來說,一個商品的庫存就是數據庫內的一行記錄),數據庫內對同一行的更新由行鎖來控制并發。
我們發現當單線程(排隊)去更新一行記錄時,性能非常高,但是當非常多的線程去并發更新一行記錄時,整個數據庫的性能會跌到慘不忍睹,趨近于零。
當時數據庫內核團隊做了兩個不同的技術實現:一個是排隊方案,另一個是并發控制方案。
兩者各有優劣,解決的思路都是要把無序的爭搶變為有序的排隊,從而提升熱點庫存扣減的性能問題。
兩個技術方案通過不斷的完善和 PK,最終都做到了成熟穩定,滿足業務的性能要求,最終為了萬無一失,我們把兩個方案都集成到了 AliSQL(阿里巴巴的 MySQL 分支)中,并且可以通過開關控制。
最終,我們通過一整年的努力,在 2013 年的雙 11 解決了庫存熱點的問題,這是第一次庫存的性能提升。
在這之后的 2016 年雙 11,我們又做了一次重大的優化,把庫存扣減性能在 2013 年的基礎上又提升了十倍,稱為第二次庫存性能優化。
2013 年堪稱雙 11 歷史上里程碑式的一年,因為這一年出現了一個突破性的技術-全鏈路壓測。
我非常佩服第一次提出全鏈路壓測理念的人-李津,他當時問我們:有沒有可能在線上環境進行全仿真的測試?
所有人的回答都是:不可能!當然,我認為這對于數據庫是更加不可能的,最大的擔心是壓測流量產生的數據該如何處理,從來沒聽說過哪家公司敢在線上系統做壓測,萬一數據出現問題,這個后果將會非常嚴重。
我記得在 2013 年某天一個炎熱的下午,我正在庫存數據庫的問題中焦頭爛額的時候,叔同(全鏈路壓測技術負責人)來找我商量全鏈路壓測數據庫的技術方案。
就在那個下午,我們兩個人討論出了一個“影子表”的方案,即在線上系統中建立一套“影子表”來存儲和處理所有的壓測數據,并且由系統保證兩套表結構的同步。
但是,我們對這件事心里都沒底,我相信在雙 11 的前幾周,沒有幾個人相信全鏈路壓測能夠落地,我們大部分的準備工作還是按照人工 Review+線下壓測的方式進行。
但是,經過所有人的努力,這件事竟然在雙 11 前兩周取得了突破性進展,當第一次全鏈路壓測成功的時候,所有人都覺得不敢相信。
最后,雙 11 的前幾個晚上,幾乎每天晚上都會做一輪全鏈路壓測,每個人都樂此不疲,給我留下的印象實在太深刻了。
但這個過程,也并不是一帆風順,我們壓出了很多次故障,多次寫錯了數據,甚至影響了第二天的報表,長時間高壓力的壓測甚至影響了機器和 SSD 的壽命。
即便出現了如此多的問題,大家依然堅定地往前走,我覺得這就是阿里巴巴與眾不同的地方,因為我們相信所以看見。
事實也證明,全鏈路壓測變成了雙 11 備戰中最有效的大殺器。

如今,全鏈路壓測技術已經成為阿里云上的一個產品,變成了更加普惠的技術服務更多企業。
2015 年:大屏背后的故事
2015 年,我從數據庫的隊長成為整個技術保障部的總隊長,負責整個技術設施領域的雙 11 備戰工作,包括 IDC、網絡、硬件、數據庫、CDN,應用等所有技術領域。
我第一次面對如此多的專業技術領域,對我又是一次全新的挑戰。但是,這一次我卻被一個新問題難倒了:大屏。
2015 年,我們第一次舉辦天貓雙 11 晚會,這一年晚會和媒體中心第一次不在杭州園區,而是選擇在北京水立方,媒體中心全球 26 小時直播。
全球都在關注我們雙 11 當天的盛況,需要北京杭州兩地協同作戰,困難和挑戰可想而知!
大家都知道對媒體直播大屏來說最最重要的兩個時刻,一個是雙 11 零點開始的時刻,一個是雙 11 二十四點結束的時刻,全程要求媒體直播大屏上跳動的 GMV 數字盡可能的不延遲。
那一年我們為了提升北京水立方現場的體驗及和杭州總指揮中心的互動,在零點前有一個倒計時環節,連線杭州光明頂作戰指揮室,逍遙子會為大家揭幕 2015 雙 11 啟動,然后直接切換到我們的媒體大屏,所以對 GMV 數字的要求基本上是零延遲,這個挑戰有多大不言而喻!
然而,第一次全鏈路壓測時卻非常不盡人意,延時在幾十秒以上,當時的總指揮振飛堅決的說:GMV 第一個數字跳動必須要在 5 秒內。
既要求 5 秒內就拿到實時的交易數字,又要求這個數字必須是準確的,所有人都覺得這是不可能完成的任務。
當時,導演組也提了另外一個預案,可以在雙 11 零點后,先顯示一個數字跳動的特效(不是真實的數字)。
等我們準備好之后,再切換到真實的交易數字,但對媒體大屏來說所有屏上的數據都必須是真實且正確的(這是阿里人的價值觀)。
所以我們不可能用這個兜底的方案,所有人想的都是如何把延遲做到 5 秒內,當天晚上,所有相關的團隊就成立一個大屏技術攻關組,開始封閉技術攻關。
別看一個小小的數字,背后涉及應用和數據庫日志的實時計算、存儲和展示等全鏈路所有環節,是真正的跨團隊技術攻關。

最終不負眾望,我們雙 11 零點 GMV 第一個數字跳動是在 3 秒,嚴格控制在 5 秒內,是非常非常不容易的!
不僅如此,為了保證整個大屏展示萬無一失,我們做了雙鏈路冗余,類似于飛機雙發動機,兩條鏈路同時計算,并可實時切換。
我想大家一定不了解大屏上一個小小的數字,背后還有如此多的故事和技術挑戰吧。雙 11 就是如此,由無數小的環節組成,背后凝聚了每個阿里人的付出。
2016 年:吃自己的狗糧
做過大規模系統的人都知道,監控系統就如同我們的眼睛一樣,如果沒有它,系統發生什么狀況我們都不知道。
我們數據庫也有一套監控系統,通過部署在主機上的 Agent,定期采集主機和數據庫的關鍵指標,包括:CPU 和 IO 利用率,數據庫 QPS、TPS 和響應時間,慢 SQL 日志等等。
并把這些指標存儲在數據庫中,進行分析和展示,最初這個數據庫也是 MySQL。
隨著阿里巴巴數據庫規模越來越大,整個監控系統就成為了瓶頸,比如:采集精度,受限于系統能力,最初我們只能做到 1 分鐘,后來經過歷年的優化,我們把采集精度提升到 10 秒。
但是,最讓人感到尷尬的是:每一年雙 11 零點前,我們通常都有一個預案,對監控系統進行降級操作,比如降低采集精度,關閉某些監控項等等。這是因為高峰期的壓力太大,不得已而為之。
另外一個業務挑戰來自安全部,他們對我們提出一個要求,希望能夠采集到每一條在數據庫上運行的 SQL,并能實時送到大數據計算平臺進行分析。
這個要求對我們更是不可能完成的任務,因為每一個時刻運行的 SQL 是非常巨大的,通常的做法只能做到采樣,現在要求是一條不漏的記錄下來,并且能夠進行分析,挑戰非常大。
2016 年雙 11,我們啟動了一個項目:對我們整個監控系統進行了重新設計。
目標:具備秒級監控能力和全量 SQL 的采集計算能力,且雙 11 峰值不降級。
第一是要解決海量監控數據的存儲和計算問題,我們選擇了阿里巴巴自研的時序數據庫 TSDB,它是專門針對 IOT 和 APM 等場景下的海量時序數據而設計的數據庫。
第二是要解決全量 SQL 的采集和計算的問題,我們在 AliSQL 內置了一個實時 SQL 采集接口,SQL 執行后不需要寫日志就直接通過消息隊列傳輸到流計算平臺上進行實時處理,實現了全量 SQL 的分析與處理。
解決了這兩個技術難題后,2016 年雙 11,我們達到了秒級監控和全量 SQL 采集的業務目標。
后來,這些監控數據和全量 SQL 成為了一個巨大的待挖掘的寶庫,通過對這些數據的分析,并與 AI 技術相結合,我們推出了 CloudDBA 數據庫智能化診斷引擎。
我們相信數據庫的未來是 Self-driving Database,它有四個特性:自診斷、自優化、自決策和自恢復。如前文所述,目前我們在智能化方向上已經取得了一些進展。
現在,TSDB 已經是阿里云上的一個產品,而 CloudDBA 除了服務阿里巴巴內部數萬工程師,也已經在云上為用戶提供數據庫優化服務。
我們不僅吃自己的狗糧,解決自己的問題,同時也用阿里巴巴的場景不斷磨練技術,服務更多的云上用戶。這就是雙 11 對技術的推動作用。
2016-2017:數據庫和緩存那點兒事
在雙 11 的歷史上,阿里巴巴自研緩存-Tair 是非常重要的技術產品,數據庫正是因為有了 Tair 的幫助,才扛起了雙 11 如此巨大的數據訪問量。
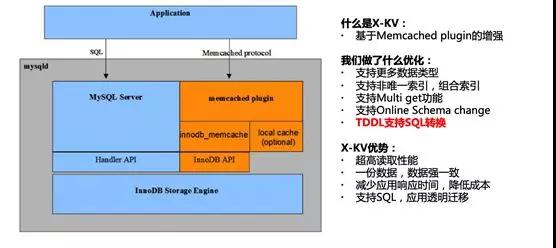
在大規模使用 Tair 的同時,開發同學也希望數據庫可以提供高性能的 KV 接口,并且通過 KV 和 SQL 兩個接口查詢的數據是一致的,這樣可以大大簡化業務開發的工作量,X-KV 因此因用而生。
它是 X-DB 的 KV 組件,通過繞過 SQL 解析的過程,直接訪問內存中的數據,可以實現非常高的性能以及比 SQL 接口低數倍的響應時間。
X-KV 技術在 2016 年雙 11 第一次得到了應用,用戶反饋非常好,QPS 可以做到數十萬級別。
在 2017 年雙 11,我們又做了一個黑科技,通過中間件 TDDL 自動來實現 SQL 和 KV 的轉換。
開發不再需要同時開發兩套接口,只需要用 SQL 訪問數據庫,TDDL 會自動在后臺把 SQL 轉換為 KV 接口,進一步提升了開發的效率,降低了數據庫的負載。
2016 年雙 11,Tair 碰到了一個業界技術難題:熱點。大家都知道緩存系統中一個 Key 永遠只能分布在一臺機器上。
但是雙 11 時,熱點非常集中,加上訪問量非常大,很容易就超出了單機的容量限制,CPU 和網卡都會成為瓶頸。
由于熱點無法預測,可能是流量熱點,也可能是頻率熱點,造成 2016 年雙 11 我們就像消防隊員一樣四處滅火,疲于奔命。
2017 年,Tair 團隊的同學就在思考如何解決這個業界的技術難題,并且創新性地提出了一種自適應熱點的技術方案:
- 智能識別技術, Tair 內部采用多級 LRU 的數據結構,通過將訪問數據 Key 的頻率和大小設定不同權值,從而放到不同層級的 LRU 上。
這樣淘汰時可以確保權值高的那批 Key 得到保留,最終保留下來且超過閾值設定的就會判斷為熱點 Key。
- 動態散列技術,當發現熱點后,應用服務器和 Tair 服務端就會聯動起來,根據預先設定好的訪問模型,將熱點數據動態散列到 Tair 服務端其他數據節點的 Hot Zone 存儲區域去訪問。
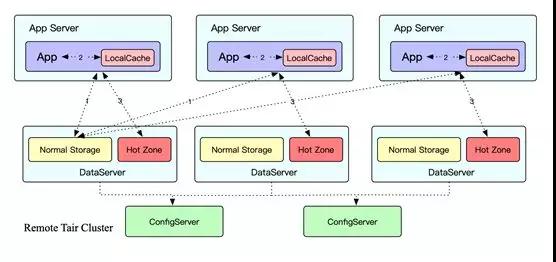
熱點散列技術在 2017 年雙 11 中取得了非常顯著的效果,通過將熱點散列到整個集群,所有集群的水位均降低到了安全線下。
如果沒有這個能力,那么 2017 年雙 11 很多 Tair 集群都可能出現問題。
可以看出,數據庫和緩存是一對互相依賴的好伙伴,他們互相借鑒,取長補短,共同撐起了雙11海量數據存儲和訪問的一片天。
2016-2017 年:如絲般順滑的交易曲線是如何做到的
自從有了全鏈路壓測這項技術后,我們希望每一年雙 11 零點的交易曲線都能如絲般順滑,但是事情往往不像預期的那樣順利。
2016 年雙 11 零點后,交易曲線出現了一些波動,才逐步攀升到最高點。
事后復盤時,我們發現主要的問題是購物車等數據庫在零點的一剎那,由于 Buffer pool 中的數據是“冷”的。
當大量請求在零點一瞬間到來時,數據庫需要先“熱”起來,需要把數據從 SSD 讀取到 Buffer pool 中,這就導致瞬間大量請求的響應時間變長,影響了用戶的體驗。
知道了問題原因后,2017 年我們提出了“預熱”技術,即在雙 11 前,讓各個系統充分“熱”起來,包括 Tair,數據庫,應用等等。
為此專門研發了一套預熱系統,預熱分為數據預熱和應用預熱兩大部分,數據預熱包括:數據庫和緩存預熱,預熱系統會模擬應用的訪問,通過這種訪問將數據加載到緩存和數據庫中,保證緩存和數據庫 BP 的命中率。
應用預熱包括:預建連接和 JIT 預熱,我們會在雙 11 零點前預先建立好數據庫連接,防止在高峰時建立連接的開銷。
同時,因為業務非常復雜,而 Java 代碼是解釋執行的,如果在高峰時同時做 JIT 編譯,會消耗大量的 CPU,系統響應時間會拉長,通過 JIT 預熱,保證代碼可以提前充分編譯。
2017 年雙 11,因為系統有了充分的預熱,交易曲線在零點時劃出了一道完美的曲線。
2017-2018 年:存儲計算分離的技術突破
2017 年初,集團高年級技術同學們發起了一個技術討論:到底要不要做存儲計算分離?由此引發了一場擴日持久的大討論。
包括我在王博士的班上課時,針對這個問題也進行了一次技術辯論,由于兩方觀點勢均力敵,最終誰也沒有說服誰。
對于數據庫來說,存儲計算分離更加是一個非常敏感的技術話題,大家都知道在 IOE 時代,小型機和存儲之間通過 SAN 網絡連接,本質上就是屬于存儲計算分離架構。
現在我們又要回到這個架構上,是不是技術的倒退?另外,對于數據庫來說,IO 的響應延時直接影響了數據庫的性能,如何解決網絡延時的問題?各種各樣的問題一直困擾著我們,沒有任何結論。
當時,數據庫已經可以使用云 ECS 資源來進行大促彈性擴容,并且已經實現了容器化部署。
但是,我們無論如何也無法回避的一個問題就是:如果計算和存儲綁定在一起,就無法實現極致的彈性,因為計算節點的遷移必須“搬遷”數據。
而且,我們研究了計算和存儲的能力的增長曲線,我們發現在雙 11 高峰時,對于計算能力的要求陡增。
但是對于存儲能力的要求并沒有發生顯著變化,如果可以實現存儲計算分離,雙 11 高峰我們只需要擴容計算節點就可以了。
綜上所述,存儲計算分離是華山一條路,必須搞定。
2017 年中,為了驗證可行性,我們選擇在開源分布式存儲 Ceph 的基礎上進行優化,與此同時,阿里巴巴自研高性能分布式存儲盤古 2.0 也在緊鑼密鼓的開發中。
另外一方面,數據庫內核團隊也參與其中,通過數據庫內核優化減少網絡延遲對數據庫性能的影響。
經過大家的共同努力,最終基于盤古 2.0 的計算存儲分離方案都在 2017 年雙 11 落地,并且驗證了使用離線機頭掛載共享存儲的彈性方案。經過這次雙 11,我們證明了數據庫存儲計算分離是完全可行的。
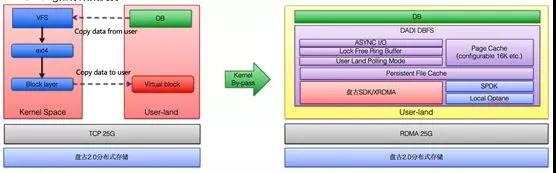
存儲計算分離的成功離不開一位幕后英雄:高性能和低延遲網絡,2017 年雙 11 我們使用了 25G 的 TCP 網絡。
為了進一步降低延遲,2018 年雙 11 我們大規模使用了 RDMA 技術,大幅度降低了網絡延遲,這么大規模的 RDMA 應用在整個業界都是獨一無二的。
為了降低 IO 延遲,我們在文件系統這個環節也做了一個大殺器-DBFS,通過用戶態技術,旁路 Kernel,實現 I/O 路徑的 Zero copy。
通過這些技術的應用,達到了接近于本地存儲的延時和吞吐。
2018 年雙 11,隨著存儲計算分離技術的大規模使用,標志著數據庫進入了一個新的時代。
總結
在 2012 年到 2018 年的這六年,我見證了零點交易數字的一次次提升,見證了背后數據庫技術的一次次突破,更見證了阿里人那種永不言敗的精神,每一次化“不可能”為“可能”的過程都是阿里技術人對技術的不懈追求。
感恩十年雙 11,期待下一個十年更美好。