Java程序性能優化之編程技巧總結
程序的性能受代碼質量的直接影響。在本文中,主要介紹一些代碼編寫的小技巧和慣例,這些技巧有助于在代碼級別上提升系統性能。
1、慎用異常
在Java軟件開發中,經常使用 try-catch 進行錯誤捕獲,但是,try-catch 語句對系統性能而言是非常糟糕的。雖然在一次 try-catch中,無法察覺到它對性能帶來的損失,但是,一旦try-catch被應用于循環之中,就會給系統性能帶來極大的傷害。
以下是一段將try-catch應用于for循環內的示例
- public void test() {
- int a = 0;
- for (int i = 0; i < 1000000; i++) {
- try {
- a = a + 1;
- System.out.println(i);
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- }
這段代碼我運行時間是 27211 ms。如果將try-catch移到循環體外,那么就能提升系統性能,如下代碼
- public void test() {
- int a = 0;
- try {
- for (int i = 0; i < 1000000; i++) {
- a = a + 1;
- System.out.println(i);
- }
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
運行耗時 15647 ms。可見tyr-catch對系統性能的影響。
2、使用局部環境
調用方法時傳遞的參數以及在調用中創建的臨時變量都保存在棧(Stack)中,速度較快。其他變量,如靜態變量、實例變量等,都在堆(Heap)中創建,速度較慢。
下面是一段測試用例
- // private static int a = 0;
- public static void main(String[] args) {
- int a = 0;
- long start = System.currentTimeMillis();
- for (int i = 0; i < 1000000; i++) {
- a = a + 1;
- System.out.println(i);
- }
- System.out.println(System.currentTimeMillis() - start);
- }
運行結果很明顯,使用靜態變量耗時15677ms,使用局部變量耗時13509ms。由此可見,局部變量的訪問速度高于類的成員變量。
3、位運算代替乘除法
在所有的運算中,位運算是最為高效的。因此,可以嘗試使用位運算代替部分算術運算,來提高系統的運行速度。
比如在HashMap的源碼中使用了位運算
- static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
- static final int MAXIMUM_CAPACITY = 1 << 30;
對于整數的乘除運算優化
- a*=2
- a/=2
用位運算可以寫為
- a<<=1a>>=1
4、替換switch
關鍵字 switch 語句用于多條件判斷, switch 語句的功能類似于 if-else 語句,兩者性能也差不多。因此,不能說 switch 語句會降低系統的性能。但是,在絕大部分情況下,switch 語句還是有性能提升空間的。
來看下面的例子:
- public static void main(String[] args) {
- long start = System.currentTimeMillis();
- int re = 0;
- for (int i = 0;i<1000000;i++){
- re = switchInt(i);
- System.out.println(re);
- }
- System.out.println(System.currentTimeMillis() - start+"毫秒");//17860
- }
- public static int switchInt(int z){
- int i = z%10+1;
- switch (i){
- case 1:return 3;
- case 2:return 6;
- case 3:return 7;
- case 4:return 8;
- case 5:return 10;
- case 6:return 16;
- case 7:return 18;
- case 8:return 44;
- default:return -1;
- }
- }
就分支邏輯而言,這種 switch 模式的性能并不差。但是如果換一種新的思路替代switch,實現相同的程序功能,性能就能有很大的提升空間。
- public static void main(String[] args) {
- long start = System.currentTimeMillis();
- int re = 0;
- int[] sw = new int[]{0,3,6,7,8,10,16,18,44};
- for (int i = 0;i<1000000;i++){
- re = arrayInt(sw,i);
- System.out.println(re);
- }
- System.out.println(System.currentTimeMillis() - start+"毫秒");//12590
- }
- public static int arrayInt(
- int[] sw,int z){
- int i = z%10+1;
- if (i>7 || i<1){
- return -1;
- }else {
- return sw[i];
- }
- }
以上代碼使用全新的思路,使用一個連續的數組代替了 switch 語句。因為對數據的隨機訪問是非常快的,至少好于 switch 的分支判斷。通過實驗,使用switch的語句耗時17860ms,使用數組的實現只耗時12590ms,提升了5s多。在軟件開發中,換一種思路可能會取得更好的效果,比如使用數組替代switch語句就是就是一個很好的例子。
5、一維數組代替二維數組
由于數組的隨機訪問的性能非常好,許多JDK類庫,如ArrayList、Vector等都是使用了數組作為其數組實現。但是,作為軟件開發人員也必須知道,一位數組和二維數組的訪問速度是不一樣的。一位數組的訪問速度要優于二維數組。因此,在性能敏感的系統中要使用二維數組的,可以嘗試通過可靠地算法,將二維數組轉為一維數組再進行處理,以提高系統的響應速度。
6、提取表達式
在軟件開發過程中,程序員很容易有意無意讓代碼做一些“重復勞動”,在大部分情況下,由于計算機的告訴運行,這些“重復勞動”并不會對性能構成太大的威脅,但若將系統性能發揮到***,提取這些“重復勞動”相當有意義。
來看下面的測試用例:
- @Test
- public void test(){
- long start = System.currentTimeMillis();
- ArrayList list = new ArrayList();
- for (int i = 0;i<100000;i++){
- System.out.println(list.add(i));
- } //以上是為了做準備
- for (int i = 0;i<list.size();i++){
- System.out.println(list.get(i));
- }
- System.out.println(System.currentTimeMillis() - start);//5444
- }
如果我們把list.size()方法提取出來,優化后的代碼如下:
- @Test
- public void test(){
- long start = System.currentTimeMillis();
- ArrayList list = new ArrayList();
- for (int i = 0;i<100000;i++){
- System.out.println(list.add(i));
- } //以上是為了做準備
- int n = list.size();
- for (int i = 0;i<n;i++){
- System.out.println(list.get(i));
- }
- System.out.println(System.currentTimeMillis() - start);//3514
- }
在我的機器上,前者耗時5444ms,后者耗時3514ms,相差2s左右,可見,提取重復的操作是相當有意義的。
7、展開循環
與前面所介紹的優化技巧略有不同,筆者認為展開循環是一種在極端情況下使用的優化手段,因為展開循環很可能會影響代碼的可讀性和可維護性,而這兩者對軟件系統來說也是極為重要的。但是,當性能問題成為系統主要矛盾時,展開循環絕對是一種值得嘗試的技術。
8、布爾運算代替位運算
雖然位運算的速度遠遠高于算術運算,但是在條件判斷時,使用位運算替代布爾運算卻是非常錯誤的選擇。
在條件判斷時,Java會對布爾運算做相當充分的優化。假設有表達式 a,b,c 進行布爾運算“a&&b&&c” ,根據邏輯與的特點,只要在整個布爾表達式中有一項返回false,整個表達式就返回false,因此,當表達式a為false時,該表達式將立即返回 false ,而不會再去計算表達式b 和c。同理,當計算表達式為“a||b||c”時,也是一樣。
若使用位運算(按位與”&“、按位或”|“)代替邏輯與和邏輯或,雖然位運算本身沒有性能問題,但是位運算總是要將所有的子表達式全部計算完成后,再給出最終結果。因此,從這個角度來說,使用位運算替代布爾運算會使系統進行很多無效計算。
9、使用arrayCopy()
數組復制是一項使用頻率很高的功能,JDK中提供了一個高效的API來實現它:
如果在應用程序需要進行數組復制,應該使用這個函數,而不是自己實現。
方法代碼:
- public static native void arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
它的用法是將源數組 src 從索引 srcPos 處復制到目標數組 dest 的 索引destPos處,復制的長度為 length。
System.arraycopy() 方法是 native 方法,通常 native 方法的性能要優于普通的方法。僅出于性能考慮,在軟件開發中,盡可能調用 native 方法。
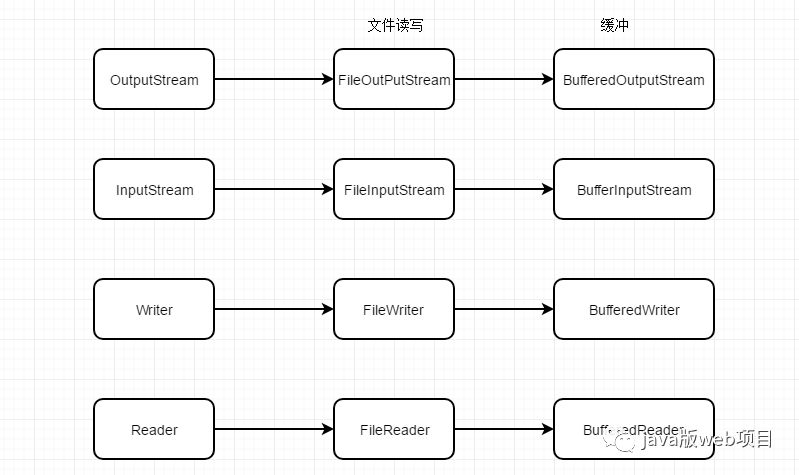
10、使用Buffer進行I/O流操作
除NIO外,使用 Java 進行 I/O操作有兩種基本方法:
- 使用基于InputStream 和 OutputStream 的方式;(字節流)
- 使用 Writer 和 Reader。(字符流)
無論使用哪種方式進行文件 I/O,如果能合理地使用緩沖,就能有效的提高I/O的性能。
11、使用clone()代替new
在Java中新建對象實例最常用的方法是使用 new 關鍵字。JDK對 new 的支持非常好,使用 new 關鍵字創建輕量級對象時,速度非常快。但是,對于重量級對象,由于對象在構造函數中可能會進行一些復雜且耗時的操作,因此,構造函數的執行時間可能會比較長。導致系統短期內無法獲得大量的實例。為了解決這個問題,可以使用Object.clone() 方法。
Object.clone() 方法可以繞過構造函數,快速復制一個對象實例。但是,在默認情況下,clone()方法生成的實例只是原對象的淺拷貝。
這里不得不提Java只有值傳遞了,關于這點,我的理解是基本數據類型引用的是值,普通對象引用的也是值,不過這個普通對象引用的值其實是一個對象的地址。代碼示例:
- int i = 0; int j = i; //i的值是0
- User user1 = new User();
- User user2 = user1; //user1值是new User()的內存地址
如果需要深拷貝,則需要重新實現 clone() 方法。下面看一下ArrayList實現的clone()方法:
- public Object clone() {
- try {
- ArrayList<?> v = (ArrayList<?>) super.clone();
- v.elementData = Arrays.copyOf(elementData, size);
- v.modCount = 0;
- return v;
- } catch (CloneNotSupportedException e) {
- // this shouldn't happen, since we are Cloneable
- throw new InternalError(e);
- }
- }
在ArrayList的clone()方法中,首先使用 super.clone() 方法生成一份淺拷貝對象。然后拷貝一份新的elementData數組讓新的ArrayList去引用。使克隆后的ArrayList對象與原對象持有不同的引用,實現了深拷貝。
12、靜態方法替代實例方法
使用 static 關鍵字描述的方法為靜態方法。在Java中,由于實例方法需要維護一張類似虛函數表的結構,以實現對多態的支持。與靜態方法相比,實例方法的調用需要更多的資源。因此,對于一些常用的工具類方法,沒有對其進行重載的必要,那么將它們聲明為 static,便可以加速方法的調用。同時,調用 static 方法不需要生成類的實例。比調用實例方法更為方便、易用。