公交車總遲到?你大概掉進了“等待時間悖論”
大數據文摘出品
編譯:李雷、小蔣、錢天培
如果你經常坐公交車,相信下面這一場景對你絕不陌生。
你到了車站,準備搭乘聲稱每10分鐘一班的公交車。你盯著你的手表留意著時間,結果公交車終于在11分鐘后到來。
這時你不由得感嘆:為什么今天運氣這么差!
想想也是。如果公交車每10分鐘一班,而你到達的時間是隨機的,那么你的平均等待時間難道不是5分鐘嘛?
但實際上,等待公交車的時間似乎永遠要比你預估的久。
究竟是你錯了?還是公交運營系統出了問題?
事實證明,在一些合理的假設下,你可以得出一個驚人的結論:
在等待平均10分鐘一班的公交車時,你的平均等待時間將為10分鐘。
這就叫等待時間悖論。
等待時間悖論
如果公交車精確每10分鐘來一輛,那么你的平均等待時間就是這個間隔的一半:5分鐘。
可是,如果我們給這個10分鐘加上一點隨機成分呢?
這時,等待時間悖論就出現了。
等待時間悖是檢驗悖論的一種。那么,什么是檢驗悖論呢?
簡言之,只要觀察量的概率與觀察量有關,就會出現檢驗悖論。比如說,我們做了一個調查大學生班級平均人數的調查。雖然學校確實保證每班平均有30名學生,但實際調查下來的平均班級規模通常會大得多。
原因是,較大的班級中就有更多的學生,因此在計算學生的平均體驗時,你會對大班進行過度地抽樣。極端得講,如果有一個班一個學生也沒有,那你壓根不會抽樣到這個班級的學生。
對于通常10分鐘一班的公交線路,有時兩班車的間隔會超過10分鐘,有時則短點。如果你在隨機時間到達,那你會有更多機會遇到更長的等待間隔,而不是較短的。
因此,乘客所經歷的平均等待時間間隔將比公交車之間的平均到達時間間隔更長,因為較長的間隔是被過度采樣了的。
但等待時間悖論提出了一個比這更震撼的主張。
當兩班車的平均間隔是N分鐘時,搭乘者所經歷的平均等待時間也是N分鐘,而非N/2分鐘。
這是真的嗎?
模擬等待時間
為了證明等待時間悖論的合理性,讓我們首先模擬平均每10分鐘到達一班的公交車流。
我們將模擬大量的公交車到達的情況:100萬輛(或大約19年中全天不間斷的10分鐘來一輛車的間隔),以保證實驗的準確性。
- import numpy as np
- N = 1000000 # number of buses
- tau = 10 # average minutes between arrivals
- rand = np.random.RandomState(42) # universal random seed
- bus_arrival_times = N * tau * np.sort(rand.rand(N))
為了確認我們做的是對的,讓我們檢查一下平均間隔是否接近τ= 10:
- intervals = np.diff(bus_arrival_times)
- intervals.mean()
輸出:
- 9.9999879601518398
通過模擬這些公交車到達,我們現在可以模擬大量乘客在此期間到達公交車站,并計算他們每個人經歷的等待時間。讓我們將它封裝在一個函數中供以后使用:
- def simulate_wait_times(arrival_times,
- rseed=8675309, # Jenny's random seed
- n_passengers=1000000):
- rand = np.random.RandomState(rseed)
- arrival_times = np.asarray(arrival_times)
- passenger_times = arrival_times.max() * rand.rand(n_passengers)
- # find the index of the next bus for each simulated passenger
- i = np.searchsorted(arrival_times, passenger_times, side='right')
- return arrival_times[i] - passenger_times
然后我們可以模擬一些等待時間并計算平均值:
- wait_times = simulate_wait_times(bus_arrival_times)
- wait_times.mean()
輸出:
- 10.001584206227317
平均等待時間接近10分鐘。正如等待時間悖論預測的那樣。
深入挖掘:概率和泊松過程
我們如何理解這一現象呢?
從本質上說,這是檢驗悖論的一個例子,其中觀察值的概率與觀察值本身有關。 讓我們用p(T)表示公交車到達車站時間隔T的分布。 在這種表示法中,到達時間的期望值是:
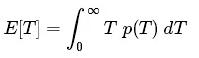
在上面的模擬中,我們選擇了E [T] =τ= 10分鐘。
當乘客隨機到達公交車站時,他們所經歷的時間間隔的概率將受到p(T)的影響,但也受到T本身的影響:間隔時間越長,乘客遇到這一間隔的概率就越大。
所以我們可以得出乘客所經歷的到達時間分布:
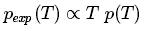
比例常數來自正態化分布:
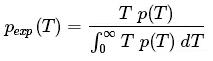
與上面相比,我們可以將它簡化為
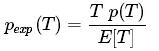
預計等待時間E [W]將是乘客所經歷的預期間隔的一半,所以我們可以寫作
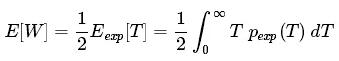
或者可以寫得更清楚一點:
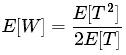
現在,讓我們為p(T)選擇一個表格并計算積分。
(1) 選擇p(T)
如果我們這種公式推導可行,那用于p(T)的合理分布是什么?
我們可以通過繪制兩班車間隔的直方圖來獲得模擬到達中的p(T)分布的圖片:
- %matplotlib inline
- import matplotlib.pyplot as plt
- plt.style.use('seaborn')
- plt.hist(intervals, bins=np.arange(80), density=True)
- plt.axvline(intervals.mean(), color='black', linestyle='dotted')
- plt.xlabel('Interval between arrivals (minutes)')
- plt.ylabel('Probability density');
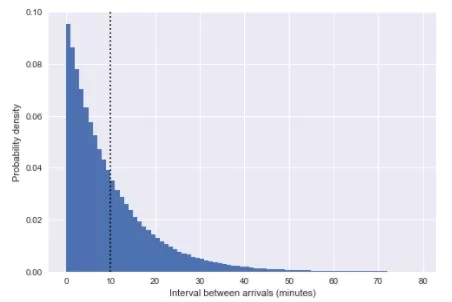
這里的垂直虛線表示平均的間隔大約為10分鐘。這看起來非常像指數分布,而且并非偶然:我們將公交車的到達時間模擬為均勻隨機數,這非常接近于泊松過程,對于這樣的過程,可以證明到達之間的間隔分布是呈指數分布的。
注:實際上,在區間Nτ內均勻采樣N個點,點之間的間隔T遵循β分布:T /(Nτ)〜Bet [1,N],當N很大的時候這個極限趨于T~Exp [1 /τ]。
區間的指數分布意味著到達時間遵循泊松過程。
通過再次檢查這個推斷,我們可以確認它與泊松過程的另一個屬性的相匹配:在固定時間范圍內到達公交的數量將是泊松分布的。讓我們將模擬到達的時間按小時分桶檢查一下:
- from scipy.stats import poisson
- # count the number of arrivals in 1-hour bins
- binsize = 60
- binned_arrivals = np.bincount((bus_arrival_times // binsize).astype(int))
- x = np.arange(20)
- # plot the results
- plt.hist(binned_arrivals, bins=x - 0.5, density=True, alpha=0.5, label='simulation')
- plt.plot(x, poisson(binsize / tau).pmf(x), 'ok', label='Poisson prediction')
- plt.xlabel('Number of arrivals per hour')
- plt.ylabel('frequency')
- plt.legend();
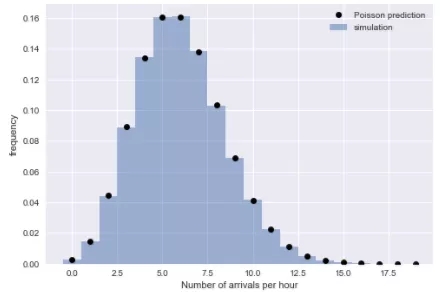
經驗值和理論值緊密匹配,這讓我們相信我們的解釋是正確:對于大N,柏松過程可以很好地描述我們模擬的公交到達時間,其到達間隔是指數分布的。
這意味著概率分布如下:
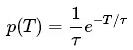
將此概率分布代入上面的公式,我們發現一個人的平均等待時間為
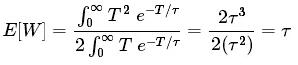
乘客的預期等待時間與公交到達的平均間隔相同!
一種補充的推斷方式是:泊松過程是一個無記憶過程,這意味著事件發生的歷史情況與下一個事件的預期時間無關。所以當你到達公交站后,等到下一班公交的平均等待時間總是一樣的:在我們的案例中,它是10分鐘,這與上一班車走了多久無關!
同樣的原理,你已經等待了多久并不重要:下一輛公交預計的到達時間總是10分鐘:對泊松過程來說,你花費在等待的時間沒用。
實際的等待時間
如果通過泊松過程確實描述了真實世界的公交到達時間,上述分析是正確的,但事實真的如此嗎?
為了確定等待時間悖論是否描述了現實情況,我們深入研究了一些可供下載的數據:arrival_times.csv(3MB的CSV文件)
https://gist.githubusercontent.com/jakevdp/82409002fcc5142a2add0168c274a869/raw/1bbabf78333306dbc45b9f33662500957b2b6dc3/arrival_times.csv
該數據集包含2016年第二季度記錄的西雅圖市中心3rd & Pike公交站的西雅圖Rapid Ride C、D、E線的預定和實際到達時間。
- import pandas as pd
- df = pd.read_csv('arrival_times.csv')
- dfdf = df.dropna(axis=0, how='any')
- df.head()
我特意選擇Rapid Ride路線的數據是因為,在一天的大部分時間里,公交車的間隔很規律,通常在10到15分鐘之間。
(1) 數據清洗
首先,讓我們進行一下數據清洗,將其轉換為更易于使用的表單:
- # combine date and time into a single timestamp
- df['scheduled'] = pd.to_datetime(df['OPD_DATE'] + ' ' + df['SCH_STOP_TM'])
- df['actual'] = pd.to_datetime(df['OPD_DATE'] + ' ' + df['ACT_STOP_TM'])
- # if scheduled & actual span midnight, then the actual day needs to be adjusted
- minute = np.timedelta64(1, 'm')
- hour = 60 * minute
- diff_hrs = (df['actual'] - df['scheduled']) / hour
- df.loc[diff_hrs > 20, 'actual'] -= 24 * hour
- df.loc[diff_hrs < -20, 'actual'] += 24 * hour
- df['minutes_late'] = (df['actual'] - df['scheduled']) / minute
- # map internal route codes to external route letters
- df['route'] = df['RTE'].replace({673: 'C', 674: 'D', 675: 'E'}).astype('category')
- df['direction'] = df['DIR'].replace({'N': 'northbound', 'S': 'southbound'}).astype('category')
- # extract useful columns
- dfdf = df[['route', 'direction', 'scheduled', 'actual', 'minutes_late']].copy()
- df.head()
(2) 公交車晚了多少?
該表中主要有六個不同的數據集:C、D和E線的北行和南行。為了了解它們的特性,讓我們繪制這六條線路的實際與預定到達時間差的直方圖:
- import seaborn as sns
- g = sns.FacetGrid(df, row="direction", col="route")
- g.map(plt.hist, "minutes_late", bins=np.arange(-10, 20))
- g.set_titles('{col_name} {row_name}')
- g.set_axis_labels('minutes late', 'number of buses');
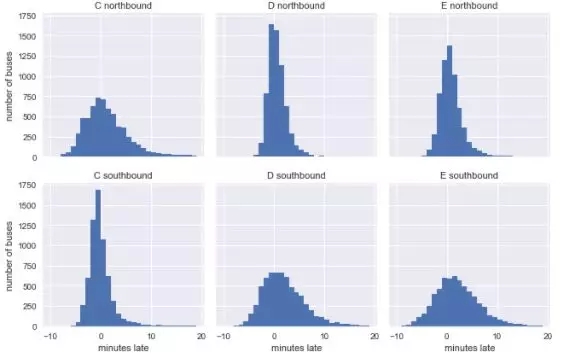
你可能會認為公交車每次在行程開始時與其時間表更接近,并且在快結束時有更多的差異,這在數據中得到了證實:南行(southbound)C線和北行(northbound) D線、E線都在各自路線的起點接近時間表,而其反方向在終點時更接近。
(3) 預定和觀察到的到達時間間隔
接下來讓我們來看看這六條路線觀察和預計的到達時間間隔。我們首先使用Pandas 的groupby功能分別計算這些間隔:
- def compute_headway(scheduled):
- minute = np.timedelta64(1, 'm')
- return scheduled.sort_values().diff() / minute
- grouped = df.groupby(['route', 'direction'])
- df['actual_interval'] = grouped['actual'].transform(compute_headway)
- df['scheduled_interval'] = grouped['scheduled'].transform(compute_headway)
- g = sns.FacetGrid(df.dropna(), row="direction", col="route")
- g.map(plt.hist, "actual_interval", bins=np.arange(50) + 0.5)
- g.set_titles('{col_name} {row_name}')
- g.set_axis_labels('actual interval (minutes)', 'number of buses');
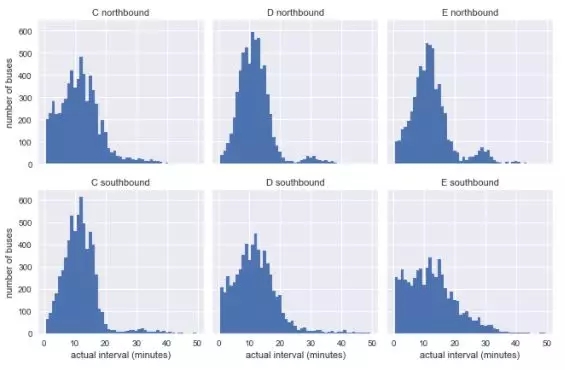
可以很清楚看出,這并不像我們模型的指數分布形式,此外,分布可能受到非恒定的預定到達間隔的影響。
讓我們重復上面的圖表,查看預定到達間隔的分布:
這表明公交車在整個星期都有不同的到達時間間隔,所以我們無法從原始到達時間數據的分布來評估等待時間悖論的準確性。
- g = sns.FacetGrid(df.dropna(), row="direction", col="route")
- g.map(plt.hist, "scheduled_interval", bins=np.arange(20) - 0.5)
- g.set_titles('{col_name} {row_name}')
- g.set_axis_labels('scheduled interval (minutes)', 'frequency');
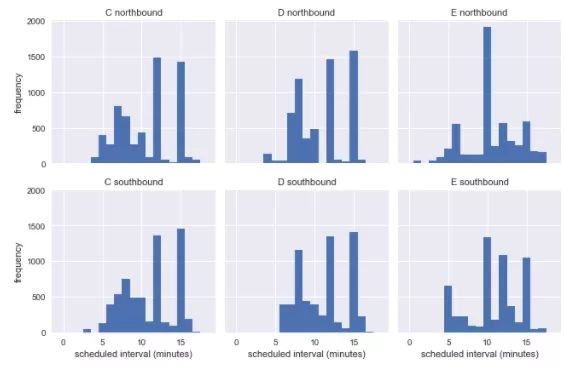
構建均勻分布的時間表
即使預定的到達間隔不均勻,也有一些特定的間隔有大量到達的數據:例如,有近2000個北行E線的預定間隔為10分鐘。為了探索等待時間悖論是否適用,讓我們按路線、方向和預定間隔對數據進行分組,然后將這些近似的到達時間重新堆疊在一起,就像它們按順序發生的一樣。這應該保持了原始數據所有的相關特征,同時更容易直接與等待時間悖論的預測比較。
- def stack_sequence(data):
- # first, sort by scheduled time
- datadata = data.sort_values('scheduled')
- # re-stack data & recompute relevant quantities
- data['scheduled'] = data['scheduled_interval'].cumsum()
- data['actual'] = data['scheduled'] + data['minutes_late']
- data['actual_interval'] = data['actual'].sort_values().diff()
- return data
- subset = df[df.scheduled_interval.isin([10, 12, 15])]
- grouped = subset.groupby(['route', 'direction', 'scheduled_interval'])
- sequenced = grouped.apply(stack_sequence).reset_index(drop=True)
- sequenced.head()
使用這些清理過的數據,我們可以繪制不同路線、方向和到達頻率的“實際”到達間隔的分布:
- for route in ['C', 'D', 'E']:
- g = sns.FacetGrid(sequenced.query(f"route == '{route}'"),
- row="direction", col="scheduled_interval")
- g.map(plt.hist, "actual_interval", bins=np.arange(40) + 0.5)
- g.set_titles('{row_name} ({col_name:.0f} min)')
- g.set_axis_labels('actual interval (min)', 'count')
- g.fig.set_size_inches(8, 4)
- g.fig.suptitle(f'{route} line', y=1.05, fontsize=14)
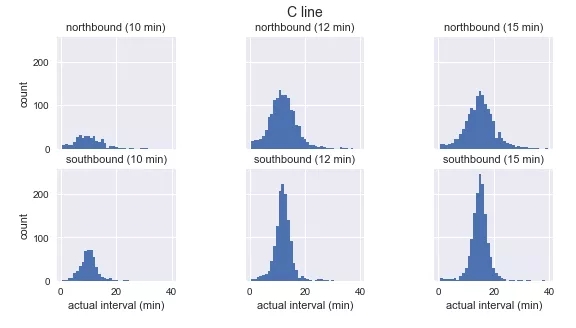
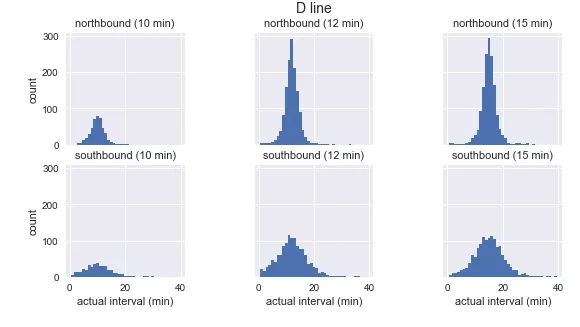
我們看到,每條路線和時間表的觀測到達間隔的分布接近高斯分布,在預定的到達間隔附近達到峰值,并且在路線開始附近具有較小的標準差(C的南行(southbound),D / E的北行(northbound)),以及在路線結束附近有更大的標準差。
即使不經過統計測試,我們也可以清楚地看到,實際的到達時間間隔肯定不是指數分布的,因而等待時間悖論所依賴的基本假設并不成立。
我們可以利用上面使用的等待時間模擬功能來找到每條公交路線、方向和時間表的平均等待時間:
- grouped = sequenced.groupby(['route', 'direction', 'scheduled_interval'])
- sims = grouped['actual'].apply(simulate_wait_times)
- sims.apply(lambda times: "{0:.1f} +/- {1:.1f}".format(times.mean(), times.std()))
輸出:

平均等待時間可能比預定時間間隔的一半長上一兩分鐘,但不等于等待時間悖論所暗示的預定時間間隔。換句話說,檢驗悖論得到了證實,但等待時間悖論似乎與現實不符。
結論
等待時間悖論是個非常有趣的現象。它涵蓋了模擬、概率以及統計假設與現實的比較。
雖然我們確認了,現實世界的公交線路確實遵循了一些版本的檢驗悖論,但上面的分析非常明確地顯示,等待時間悖論背后的核心假設(公交車的到達時間遵循泊松過程)并不是很有根據。
回想起來,這也并不令人驚訝:泊松過程是一個無記憶過程,它假設到達的概率完全獨立于自上次到達的時間。實際上,一個運行良好的公交系統將有一個有意安排的時間表,用以避免這種行為:公交車不會在一天中的隨機時間開始他們的路線,而是按照選擇能夠***服務公眾的時間表開始他們的路線。
這里更大的教訓是,你應該謹慎對待任何數據分析工作的假設。泊松過程可以良好地描述到達時間的數據 – 但只是在某些特定情況下。
僅僅因為一種類型的數據看起來像另一種類型的數據,并不能推導出對一種數據有效的假設必然對另一種有效。
通常那些看似正確的假設可能會導致與現實不符的結論。
***,你可以在這里下載本文全部代碼👇http://jakevdp.github.io/downloads/notebooks/WaitingTimeParadox.ipynb
相關報道:
http://jakevdp.github.io/blog/2018/09/13/waiting-time-paradox/?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
【本文是51CTO專欄機構大數據文摘的原創文章,微信公眾號“大數據文摘( id: BigDataDigest)”】