













菲數科技解決方案
公司名稱: 菲數科技
公司介紹:
杭州菲數科技有限公司是創建于2015年的研發型公司,是國內最早一批專注于FPGA異構加速解決方案的專業公司,OpenPOWER基金會成員,Xilinx公司的國內官方合作伙伴。
菲數科技目前是FPGA異構加速領域的主流供應商,已經獲得了多個國內一線互聯網數據中心認可并批量使用,可以提供從硬件板卡,開發設計環境,驅動及應用接口,到FPGA邏輯設計及算法實現的整套的加速解決方案。
菲數科技致力于為客戶提供多元的數據處理加速服務,包括深度學習,高性能計算,邊緣計算,數據壓縮/加解密,網絡安全等多方面,尤其在CNN卷積網絡的加速方案上,性能指標突出。
解決方案介紹: 通用型CNN卷積神經網絡FPGA加速解決方案
CNN卷積神經網絡是一種深度的監督學習下的機器學習模型,具有極強的適應性,善于挖掘數據局部特征,提取全局訓練特征和分類,它的權值共享結構網絡使之更類似于生物神經網絡,在模式識別各個領域都取得了很好的成果。最近在多層卷積神經網絡的突破導致了識別任務(如大量圖片分類和自動語音識別)準確率的大幅提升。
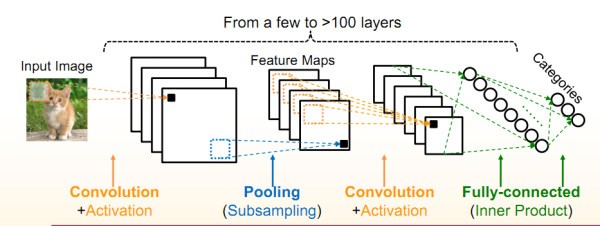
卷積神經網絡是一種多層的監督學習神經網絡,隱含層的卷積層和池采樣層是實現卷積神經網絡特征提取功能的核心模塊。卷積神經網絡結構包括:卷積層,降采樣層,全鏈接層。每一層有多個特征圖,每個特征圖通過一種卷積濾波器提取輸入的一種特征,每個特征圖有多個神經元。可以看到CNN算法主要由conv ,pooling,norm等幾個部分組成,工作時將image跟weight灌進去,最終得到預測結果。在CNN里面主要耗時的就是conv二維卷積了。性能瓶頸也主要在于卷積時需要大量乘加運算,參與計算的大量weight參數會帶來的很多訪存請求。這些多層神經網絡很大,很復雜,需要大量計算資源來訓練和評估。
人工智能行業發展ABC三要素:算法(Algorithm)、大數據(Big Data)和計算力(Computing),大數據和算法可以分別比作人工智能的燃料和發動機,計算力則是制約人工智能成“人”還是“成神”的基礎硬件—處理器芯片。實現計算力的提升有四種方案:CPU、GPU、FPGA、ASIC。FPGA正是作為一種AI芯片呈現在人們的面前,準確的說,FPGA不僅僅是芯片,它能夠通過軟件的方式定義,所以更像是AI芯片領域的變形金剛。
利用FPGA做計算加速在可編程性,實時性和互聯性上的優勢十分明顯,相較于CPU/GPU有足夠競爭力的低延時高性能,然而其短板也非常的明顯,FPGA使用HDL硬件描述語言來進行開發,開發周期長,入門門檻高,需要FPGA的開發周期跟上深度學習算法的迭代周期。
菲數科技設計開發的通用型CNN FPGA加速解決方案,采用通用架構設計,無須更改底層設計文件,通過配置文件即可獲得對各種主流算法模型的支持,可以支持在線模型切換。同時,對于新興的深度學習算法,在此通用基礎版本上進行相關算子的快速開發迭代,模型加速開發時間從之前的數月降低到現在的一到兩周之內。
通過Caffe/Tensorflow/Mxnet等框架訓練出來的CNN模型,通過菲數的加速庫ANN生成相應的配置文件;同時,對圖片數據和模型權重數據按照優化規則進行預處理,以及壓縮后通過PCIe下發到FPGA加速器中。FPGA加速器根據配置,進行加速工作,加速器執行一遍完整緩沖區中的配置則完成一張圖片深度模型的計算加速工作。每個功能模塊各自相對獨立,只對每一次單獨的模塊計算請求負責。加速器與深度學習模型相對抽離,各個layer的數據依賴以及前后執行關系均在配置文件中進行控制。
解決方案優勢/帶給客戶的好處:
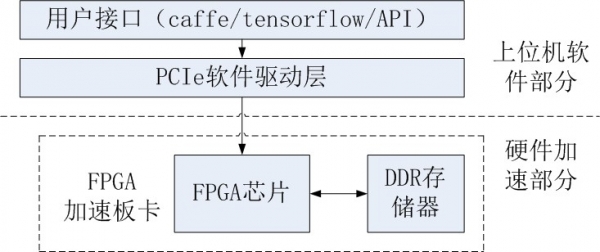
菲數科技支持通用卷積神經網路的加速庫ANN的FX613Q加速板卡,采用了Xilinx的Xilinx VU13P芯片,性能領先, 使用方便,且從硬件板卡,FPGA IP方案到用戶API,形成完整產品方案:
• 支持caffe/tensorflow開源環境下直接使用,自動解析網絡拓撲和權重文件并自動配置FPGA
• 支持通用cnn加速應用,即可同時支持Resnet,SSD,VGG和YOLO等等網絡拓撲
• 性能超越同級別的GPU,能耗比突出
•解決方案使用場景和案例:
菲數科技的通用卷積神經網路的加速庫ANN應用于直播場景的圖片審定,很好地滿足了項目對于大批量和實時性的要求。
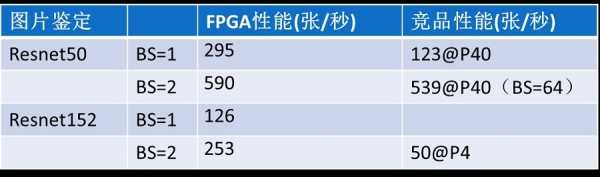
在Caffe環境下,Resnet50的架構,Batch Size=2的情況下,每秒可處理規格為224x224x3的圖片590張,超過了同類GPU P40的性能。而在Resnet152架構下,每秒可以處理253張,約為P40的兩倍。














