













Python基礎知識大全:集合用法、文件操作、字符編碼轉換、函數(shù)
作者:編程python新視野
人工智能時代,該學學python了!既然確定學習Python了,那么就要一步一步從基礎開始學習嘛~!
人工智能時代,該學學python了!
既然確定學習Python了,那么就要一步一步從基礎開始學習嘛~!
下面我們來看看基礎知識
集合(Set)及其函數(shù)
集合是一個無序的、無重復元素的序列。
- list = {1, 3, 6, 5, 7, 9, 11, 3, 7} # 定義集合方式一
- list1 = set([1, 3, 6, 5, 7, 9, 11, 3, 7]) # 定義集合方式二
- list2 = set() # 定義一個空集合
- print(list1, list) # 打印后可看到,集合中的元素已自動去重
- print(3 in list) # 判斷一個元素是否在集合中,返回bool值
- print(20 not in list1) # 判斷一個元素是否不在集合中,返回bool值
- list1.add(99) # 新增元素
- list1.update([10, 20, 30, 2]) # 新增多項
- list1.remove(3) # 刪除一個元素,若元素不存在則報錯
- print(list1.discard(8)) # 刪除一個元素,若元素不存在則不做任何操作
- print(len(list1)) # 計算集合中元素的個數(shù)
- print(list1.pop()) # 從集合中隨機彈出一個元素
- list.clear() # 清空集合
集合的運算
- list1 = set([1, 3, 6, 5, 7, 9, 11, 3, 7])
- list2 = set([2, 4, 6, 8, 3, 5])
- print(list1, list2)
- # 交集
- print(list1.intersection(list2))
- print(list1 & list2)
- # 并集
- print(list1.union(list2))
- print(list1 | list2)
- # 差集
- print(list1.difference(list2))
- print(list1 - list2)
- # 對稱差集
- print(list1.symmetric_difference(list2))
- print(list1 ^ list2)
- # 是否為子集 是否為父集
- list3 = set([9, 11])
- print(list3.issubset(list1))
- print(list1.issuperset(list3))
- # 若兩個集合的交集為空 返回true
- list4 = set([20, 30])
- print(list1.isdisjoint(list4))
- print(list1.isdisjoint(list2))
文件(File)操作
在開發(fā)中經(jīng)常會有讀寫文件的需求,相關的代碼實現(xiàn)如下:
文件的打開模式
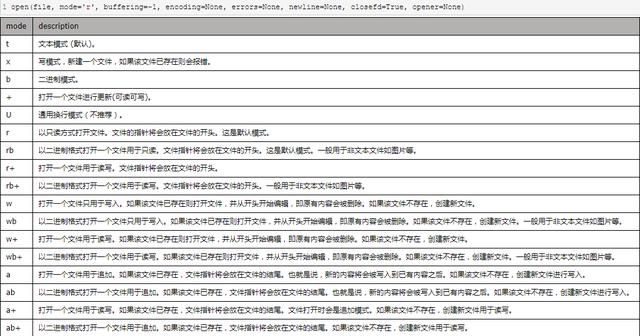
文件的讀操縱、寫操作、追加操作、按行讀取文件
- # read 直接讀文件全文
- f = open('test', 'r', encoding='utf-8') # 文件句柄
- data = f.read()
- print(data)
- # write 向文件中寫
- f = open('test1', 'w', encoding='utf-8')
- f.write('我愛北京天安門,
- 天安門上太陽升')
- # append 在文件***追加內容
- f = open('test1', 'a', encoding='utf-8')
- f.write('呀呼嘿')
- # loop 按行讀取文件
- # high bigger 將文件作為迭代器 讀一行打印一行 內存中只緩存一行
- f = open('test', 'r', encoding='utf-8')
- count = 0
- for l in f:
- if count == 9:
- print('----------')
- count += 1
- continue
- print(l.strip())
- count += 1
- # low loop 將文件內容全部讀取至內存,效率低
- f = open('Sonnet', 'r', encoding='utf-8')
- for index, line in enumerate(f.readlines()):
- if index == 9:
- print('------------')
- continue
- print(line.strip())
文件的函數(shù)
- f = open('test', 'r', encoding='utf-8') # 文件句柄 讀模式打開文件
- print(f.tell()) # 獲取當前光標位置
- print(f.readline())
- print(f.readline())
- print(f.tell())
- print(f.readline())
- f.seek(10) # 跳轉光標到第10個字符
- print(f.readline())
- print(f.encoding) # 獲取文件編碼
- print(f.fileno()) # i don't know what it is
- print(f.isatty()) # 判斷文件是否是tty終端
- print(f.readable()) # 判斷文件是否是可讀
- print(f.writable()) # 判斷文件是否是可寫
- print(f.seekable()) # 判斷文件是否是可跳轉光標 (tty不可跳轉
- f.flush() # 當用寫模式打開文件時 并不是寫一句系統(tǒng)就會調用一次io 若需要及時刷新硬盤中的文件內容 可以調用該函數(shù)
- f.close() # 關閉文件
- print(f.closed) # 判斷文件是否關閉
文件的修改
- # 文件的修改 直接修改文件本身比較困難 可以將修改寫入另一個文件中 如有需求可以再寫回文件本身
- f = open('test', 'r', encoding='utf-8')
- f_new = open('test.bak', 'w', encoding='utf-8')
- for line in f:
- if '我曾千萬次夢見' in line:
- line = line.replace('我曾千萬次夢見', '我不想千萬次夢見')
- f_new.writelines(line)
- f.close()
- f_new.close()
一個進度條實例 用于理解flush函數(shù)的機制 該實例可以實現(xiàn)進度條效果
- import sys
- import time
- f = open('Sonnet1', 'w', encoding='utf-8') # 文件句柄 寫模式打開文件 會新建一個文件 若同名文件存在 則直接覆蓋
- for i in range(10):
- sys.stdout.write('#')
- sys.stdout.flush()
- time.sleep(0.2)
字符編碼轉換
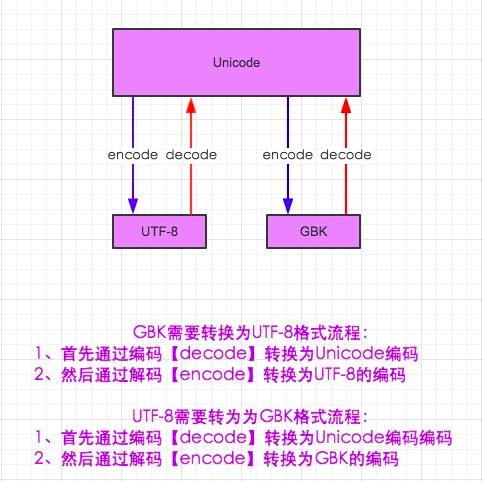
字符編碼轉換最重要的一點就是,切記unicode是編碼之間的中轉站,若unicode不是目標編碼或者原始編碼,那么任何兩個編碼相互轉換都需要經(jīng)過unicode(見下圖)。
需要注意的是,python的默認編碼是ASCII,python3的默認編碼是unicode。
在python3中encode,在轉碼的同時還會把string變成bytes類型,decode在解碼的同時還會把bytes變回string。
函數(shù)
函數(shù)是組織好的,可重復使用的,用來實現(xiàn)單一,或相關聯(lián)功能的代碼段。
函數(shù)能提高應用的模塊性,和代碼的重復利用率。python提供了許多內建函數(shù)(如print());也可以自己創(chuàng)建函數(shù),即用戶自定義函數(shù)。
定義一個有自己想要功能的函數(shù),需要遵循以下規(guī)則:
- 函數(shù)代碼塊以 def 關鍵詞開頭,后接函數(shù)標識符名稱和圓括號 ()。
- 任何傳入?yún)?shù)和自變量必須放在圓括號中間,圓括號之間可以用于定義參數(shù)。
- 函數(shù)的***行語句可以選擇性地使用文檔字符串——用于存放函數(shù)說明。
- 函數(shù)內容以冒號起始,并且縮進。
- return [表達式] 結束函數(shù),選擇性地返回一個值給調用方。不帶表達式的return相當于返回 None。
待補充知識:函數(shù)的參數(shù)、變量作用域、遞歸、高階函數(shù)。
責任編輯:龐桂玉
來源:
今日頭條














