Python爬取房產數據,在地圖上展現!
作者:歐巴
小伙伴,我又來了,這次我們寫的是用python爬蟲爬取烏魯木齊的房產數據并展示在地圖上,地圖工具我用的是 BDP個人版-免費在線數據分析軟件,數據可視化軟件 ,這個可以導入csv或者excel數據。

小伙伴,我又來了,這次我們寫的是用python爬蟲爬取烏魯木齊的房產數據并展示在地圖上,地圖工具我用的是 BDP個人版-免費在線數據分析軟件,數據可視化軟件 ,這個可以導入csv或者excel數據。
- 首先還是分析思路,爬取網站數據,獲取小區名稱,地址,價格,經緯度,保存在excel里。再把excel數據上傳到BDP網站,生成地圖報表
本次我使用的是scrapy框架,可能有點大材小用了,主要是剛學完用這個練練手,再寫代碼前我還是建議大家先分析網站,分析好數據,再去動手寫代碼,因為好的分析可以事半功倍,烏魯木齊樓盤,2017烏魯木齊新樓盤,烏魯木齊樓盤信息 - 烏魯木齊吉屋網 這個網站的數據比較全,每一頁獲取房產的LIST信息,并且翻頁,點進去是詳情頁,獲取房產的詳細信息(包含名稱,地址,房價,經緯度),再用pipelines保存item到excel里,最后在bdp生成地圖報表,廢話不多說上代碼:
JiwuspiderSpider.py
- # -*- coding: utf-8 -*-
- from scrapy import Spider,Request
- import re
- from jiwu.items import JiwuItem
- class JiwuspiderSpider(Spider):
- name = "jiwuspider"
- allowed_domains = ["wlmq.jiwu.com"]
- start_urls = ['http://wlmq.jiwu.com/loupan']
- def parse(self, response):
- """
- 解析每一頁房屋的list
- :param response:
- :return:
- """
- for url in response.xpath('//a[@class="index_scale"]/@href').extract():
- yield Request(url,self.parse_html) # 取list集合中的url 調用詳情解析方法
- # 如果下一頁屬性還存在,則把下一頁的url獲取出來
- nextpage = response.xpath('//a[@class="tg-rownum-next index-icon"]/@href').extract_first()
- #判斷是否為空
- if nextpage:
- yield Request(nextpage,self.parse) #回調自己繼續解析
- def parse_html(self,response):
- """
- 解析每一個房產信息的詳情頁面,生成item
- :param response:
- :return:
- """
- pattern = re.compile('<script type="text/javascript">.*?lng = \'(.*?)\';.*?lat = \'(.*?)\';.*?bname = \'(.*?)\';.*?'
- 'address = \'(.*?)\';.*?price = \'(.*?)\';',re.S)
- item = JiwuItem()
- results = re.findall(pattern,response.text)
- for result in results:
- item['name'] = result[2]
- item['address'] = result[3]
- # 對價格判斷只取數字,如果為空就設置為0
- pricestr =result[4]
- pattern2 = re.compile('(\d+)')
- s = re.findall(pattern2,pricestr)
- if len(s) == 0:
- item['price'] = 0
- else:item['price'] = s[0]
- item['lng'] = result[0]
- item['lat'] = result[1]
- yield item
item.py
- # -*- coding: utf-8 -*-
- # Define here the models for your scraped items
- #
- # See documentation in:
- # http://doc.scrapy.org/en/latest/topics/items.html
- import scrapy
- class JiwuItem(scrapy.Item):
- # define the fields for your item here like:
- name = scrapy.Field()
- price =scrapy.Field()
- address =scrapy.Field()
- lng = scrapy.Field()
- lat = scrapy.Field()
- pass
pipelines.py 注意此處是吧mongodb的保存方法注釋了,可以自選選擇保存方式
- # -*- coding: utf-8 -*-
- # Define your item pipelines here
- #
- # Don't forget to add your pipeline to the ITEM_PIPELINES setting
- # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
- import pymongo
- from scrapy.conf import settings
- from openpyxl import workbook
- class JiwuPipeline(object):
- wb = workbook.Workbook()
- ws = wb.active
- ws.append(['小區名稱', '地址', '價格', '經度', '緯度'])
- def __init__(self):
- # 獲取數據庫連接信息
- host = settings['MONGODB_URL']
- port = settings['MONGODB_PORT']
- dbname = settings['MONGODB_DBNAME']
- client = pymongo.MongoClient(host=host, port=port)
- # 定義數據庫
- db = client[dbname]
- self.table = db[settings['MONGODB_TABLE']]
- def process_item(self, item, spider):
- jiwu = dict(item)
- #self.table.insert(jiwu)
- line = [item['name'], item['address'], str(item['price']), item['lng'], item['lat']]
- self.ws.append(line)
- self.wb.save('jiwu.xlsx')
- return item
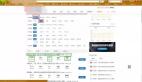
最后報表的數據

mongodb數據庫

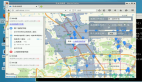
地圖報表效果圖:https://me.bdp.cn/share/index.html?shareId=sdo_b697418ff7dc4f928bb25e3ac1d52348
責任編輯:未麗燕
來源:
知乎