













13倍性能,3倍穩定性提升!UCloud云硬盤做了這些事
近期,我們推出高性能SSD云盤,滿足用戶對高性能的場景需求。SSD云盤相比普通云盤,IOPS提升了13倍,穩定性提升了3倍,平均時延降低了10倍。為了做到這些,我們從去年10月份開始對云盤的架構進行了重新設計,充分減少時延和提升IO能力;并通過復用部分架構和軟件,提供性能更好、更穩定的普通云盤;同時逐步引入Stack/Kernel Bypass技術,打造下一代超高性能存儲。新架構推出后,已服務了現網用戶的3400多個云盤實例,總存儲容量達800TB,集群每秒IOPS均值31萬。
架構升級要點
通過對現階段問題和需求的分析,我們整理了這次架構升級的具體要點:
1、解決原有軟件架構不能充分發揮硬件能力的局限;
2、支持SSD云盤,提供QOS保證,充分發揮后端NVME物理盤的IOPS和帶寬性能,單個云盤IOPS可達2.4W;
3、支持更大容量云盤,32T甚至更大;
4、充分降低IO流量的熱點問題;
5、支持并發創建幾千塊云盤,支持并發掛載幾千塊云盤;
6、支持老架構云盤在線向新架構遷移,支持普通云盤在線遷移至SSD云盤。
新架構改造實踐
改造一:IO路徑優化
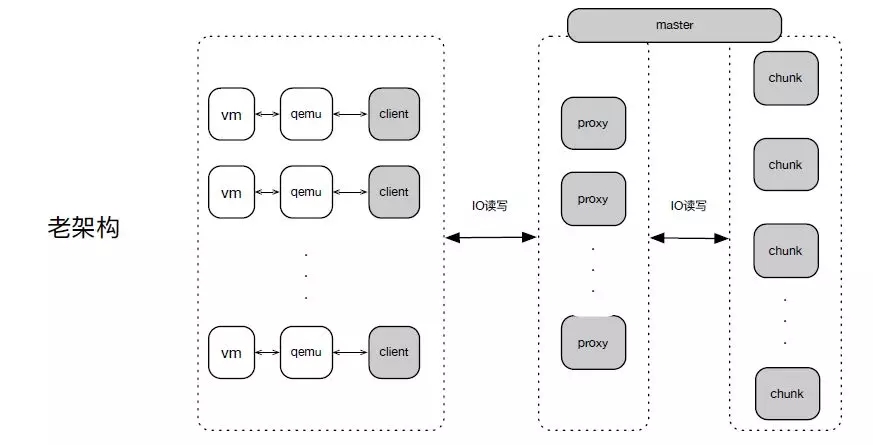
老架構中,整個IO路徑有三大層,第一層宿主Client側,第二層Proxy側,第三層存儲Chunk層。Proxy負責IO的路由獲取以及緩存;IO的讀寫轉發到下一層存儲層,負責IO寫三份復制。
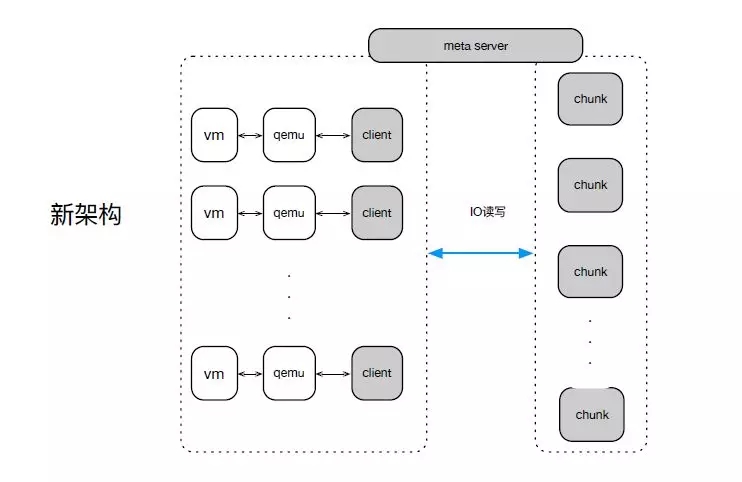
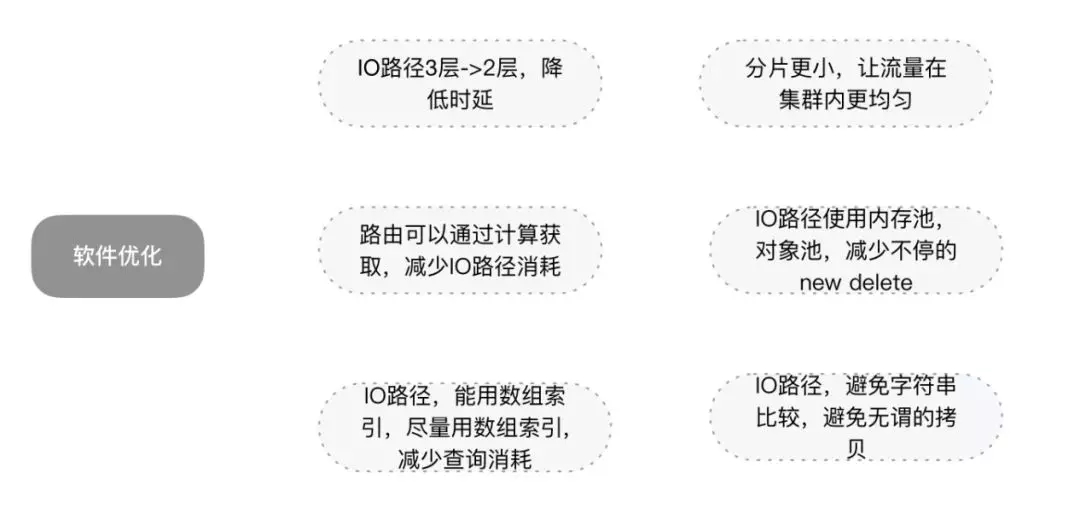
而新架構中,路由獲取交給了Client,IO讀寫Client可直接訪問存儲Chunk層,寫三份復制也交給了Chunk。整個IO路徑變成了2層,一層是宿主Client側, 另一層存儲Chunk層。
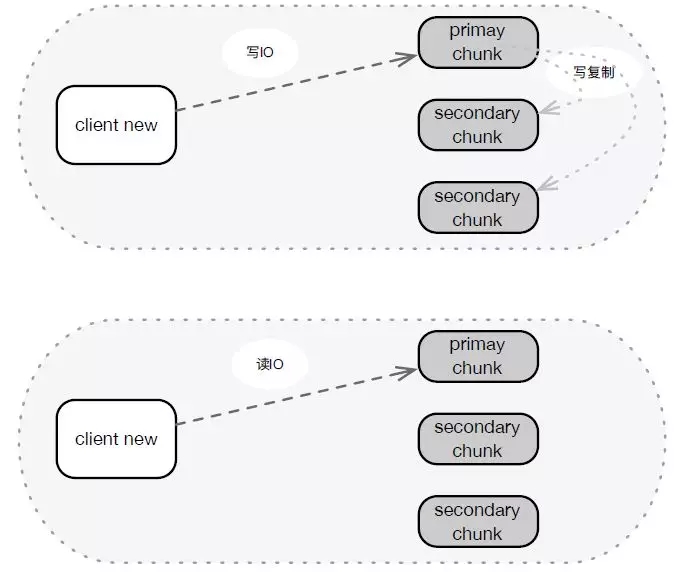
架構升級之后,對讀IO,一次網絡請求直達到后端存儲節點,老架構都是2次。對寫IO,主副本IO一次網絡請求直達后端存儲節點,另外2副本經過主副本,經歷兩次網絡轉發,而老架構三個副本均為兩次。讀IO時延平均降低0.2-1ms,寫尾部時延減低,也有效的降低總體時延。
改造二:元數據分片
分布式存儲中,會將數據進行分片,從而將每個分片按多副本打散存儲于集群中。如下圖,一個200G的云盤,如果分片大小是1G,則有200個分片。老架構中,分片大小是1G,在實際業務過程中我們發現,部分業務的IO熱點集中在較小范圍內,如果采用1G分片,普通SATA磁盤性能會很差。并且在SSD云盤中,也不能均勻的將IO流量打散到各個存儲節點上。

新架構中,我們支持了1M大小的分片。1M分片,可以充分使用整個集群的能力。高性能存儲中,因為固態硬盤性能較好,業務IO熱點集中在較小范圍內,也能獲得較好的性能。
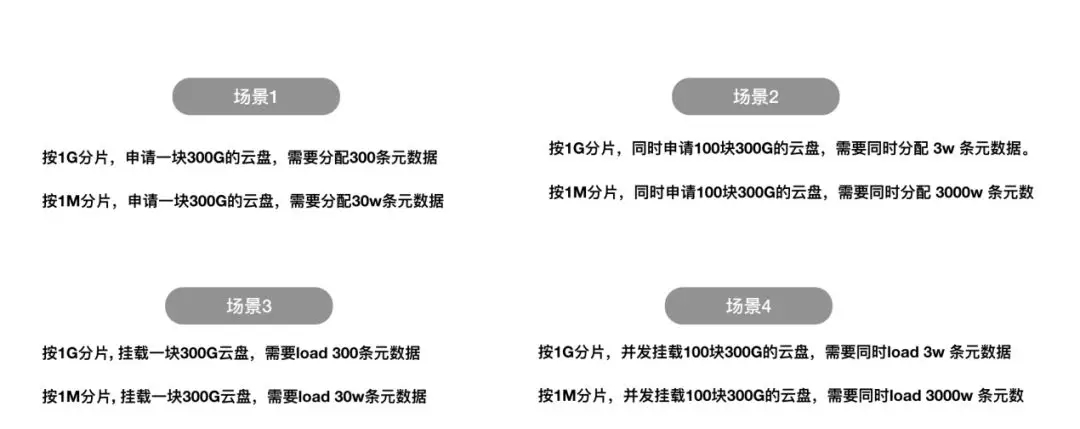
但UCloud元數據采用的是預分配和掛載方案,申請云盤時系統直接分配所有元數據并全部加載到內存。分片過小時,需要同時分配或掛載的元數據量會非常大,容易超時并導致部分請求失敗。
例如,同時申請100塊300G的云盤,如果按1G分片,需要同時分配3W條元數據;如果按照1M分片,則需要同時分配3000W條元數據。
為了解決分片變小導致的元數據分配/掛載失敗問題,我們嘗試改變IO時的分配策略,即云盤掛載時,將已分配的元數據加載到內存中。IO時,如果IO范圍命中已經分配路由,則按內存中的路由進行IO;如果IO范圍命中未分配路由,則實時向元數據模塊請求分配路由,并將路由存儲在內存中。
按IO時分配,如果同時申請100塊300G的云盤, 同時掛載、同時觸發IO,大約會產生1000 IOPS,偏隨機。最壞情況會觸發1000* 100 = 10W 元數據分配。在IO路徑上,還是存在較大消耗。
最終,新架構中我們放棄了中心節點存儲分片元數據的方案,采用了以一套統一規則去計算獲取路由的方案。
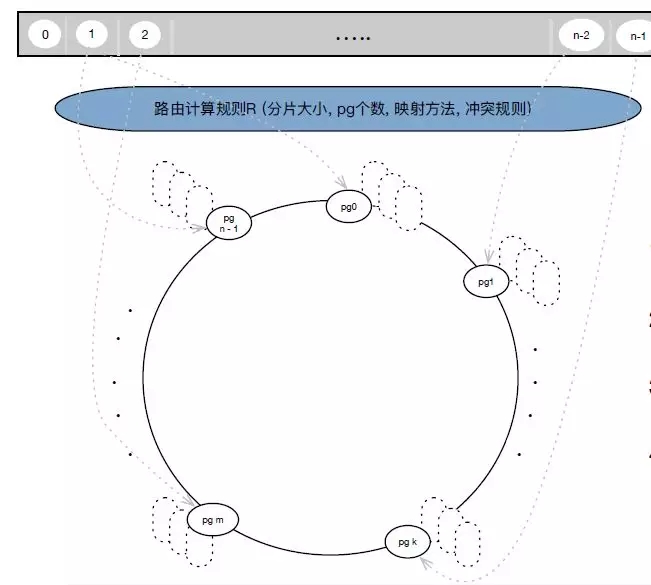
該方案中,Client 端和集群后端采用同樣的計算規則R(分片大小、pg個數、映射方法、沖突規則);云盤申請時,元數據節點利用計算規則四元組判斷容量是否滿足;云盤掛載時,從元數據節點獲取計算規則四元組; IO時,按計算規則R(分片大小、pg個數、映射方法、沖突規則)計算出路路由元數據然后直接進行IO。通過這種改造方案,可以確保在1M數據分片的情況下,元數據的分配和掛載暢通無阻,并節省IO路徑上的消耗。
改造三:支持SSD高性能云盤
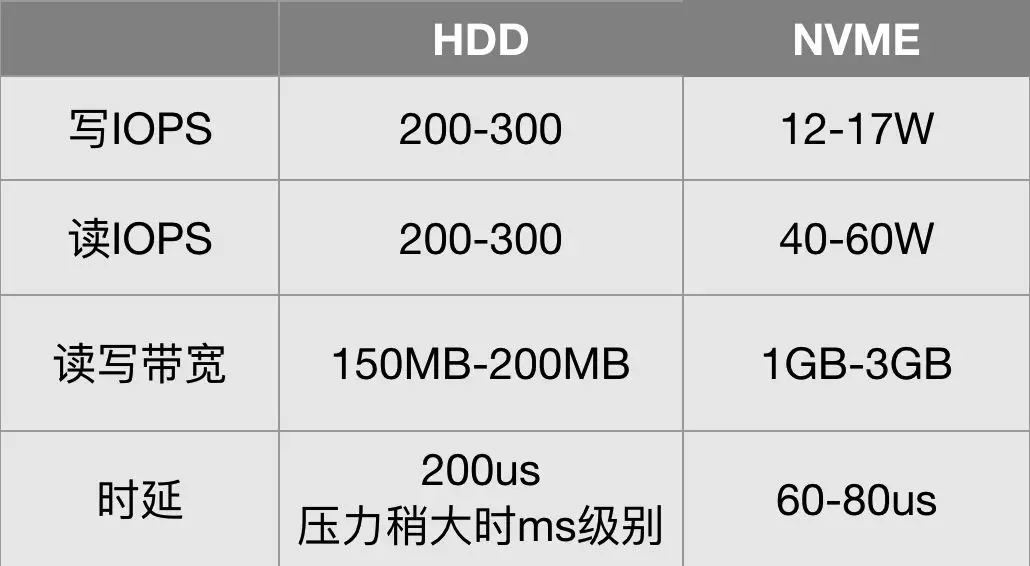
通過上述對比可以看到,NVME固態硬盤性能百倍于機械盤,但需要軟件的配套設計,才能利用NVME固態硬盤的能力。
SSD云盤提供QoS保證,單盤IOPS:min{1200+30*容量,24000} 對于SSD云盤,傳統的單線程模式會是瓶頸,難以支持后端NVME硬盤幾十萬的IOPS以及1-2GB的帶寬,所以我們采用了多線程模型。
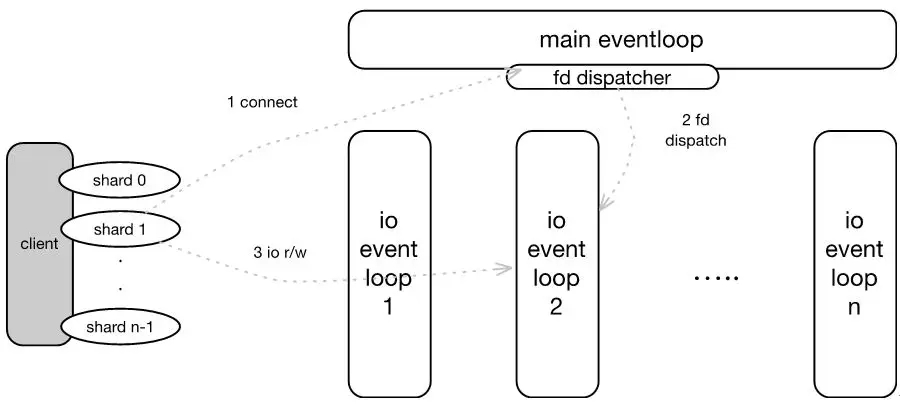
為了較快推出SSD云盤,我們還是采用了傳統TCP網絡編程模型,未使用KernelBypass。同時,通過一些軟件細節的優化,來減少CPU消耗。
目前,單個線程寫可達6WIOPS,讀可達8W IOPS,5個線程可以基本利用NVME固態硬盤的能力。目前我們能提供云盤IO能力如下:

改造四:防過載能力
對于普通云盤,新架構的軟件不再是瓶頸,但一般的機械硬盤而言,隊列并發大小只能支持到32-128左右。100塊云盤,持續同時各有幾個IO命中一塊物理HDD磁盤時,因為HDD硬盤隊列并發布較小,會出現較多的io_submit耗時久或者失敗等問題。Client側判斷IO超時后,會重試IO發送,造成Chunk端TCP緩沖區積壓越來越多的IO包,越來越多的超時積壓在一起,最終導致系統過載。
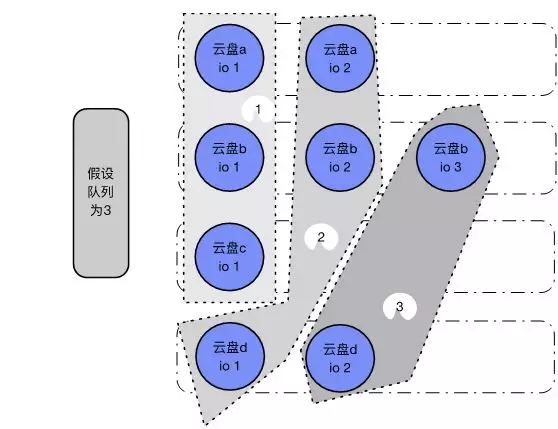
對于普通云盤,需控制并發提交隊列大小,按隊列大小,依次遍歷所有云盤,下發各云盤的IO,如上圖的1、2、3。實際代碼邏輯里,還需要考慮云盤大小的權重。
對于SSD云盤來說,傳統的單個線程會是瓶頸,難以支持幾十萬的IOPS以及1-2GB的帶寬。
壓測中,我們模擬了熱點集中在某個線程上的場景,發現該線程CPU基本處于99%-100%滿載狀態,而其它線程則處于空閑狀態。后來,我們采用定期上報線程CPU以及磁盤負載狀態的方式,當滿足某線程持續繁忙而有線程持續空閑時,選取部分磁盤分片的IO切換至空閑線程,來規避部分線程過載。
改造五:在線遷移
老架構普通云盤性能較差,部分普通云盤用戶業務發展較快,希望從普通云盤遷移至SSD云盤,滿足更高的業務發展需要。目前線上存在2套老架構,為了快速達到在線遷移的目的,我們第一期決定從系統外圍支持在線遷移。
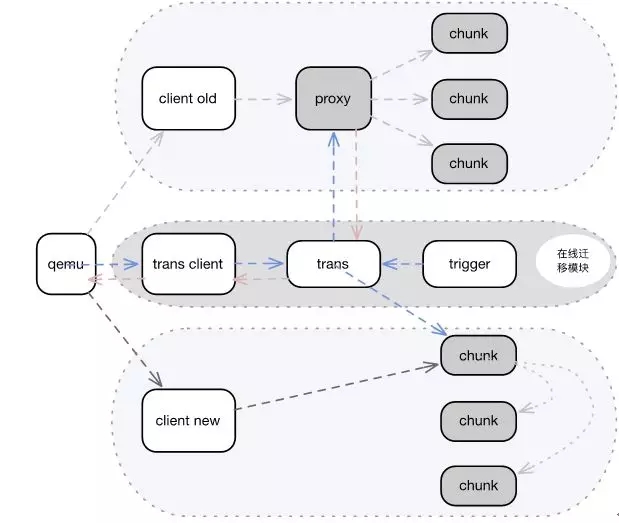
遷移流程如下:
1、后端設置遷移標記;
2、Qemu連接重置到Trans Client;
3、寫IO流經過Trans Client到Trans模塊,Trans模塊進行雙寫:一份寫老架構,一份寫新架構;
4、Trigger遍歷磁盤, 按1M大小觸發數據命令給Trans觸發數據后臺搬遷。未完成搬遷前,IO讀經Trans向舊架構Proxy讀取;
5、當全部搬遷完成后,Qemu連接重置到新架構Client,完成在線遷移。
加一層Trans及雙寫,使遷移期間存在一些性能損耗。但對于普通云盤,遷移期間可以接受。我們目前對于新架構也正在建設基于Journal的在線遷移能力,目標在遷移期間,性能影響控制在5%以下。
經過上述系列改造,新的云硬盤架構基本完成了最初的升級目標。目前,新架構已經正式上線并成功運用于日常業務當中。在這里,也談談我們正在研發的幾項工作。
1、容量具備無限擴展能力
每個可用區,會存在多個存儲集群Set. 每個Set可提供1PB左右的存儲(我們并沒有讓集群無限擴容)。當Set1的云盤需要從1T擴容至32T 、100T時,可能會碰到Set1的容量不足的問題。
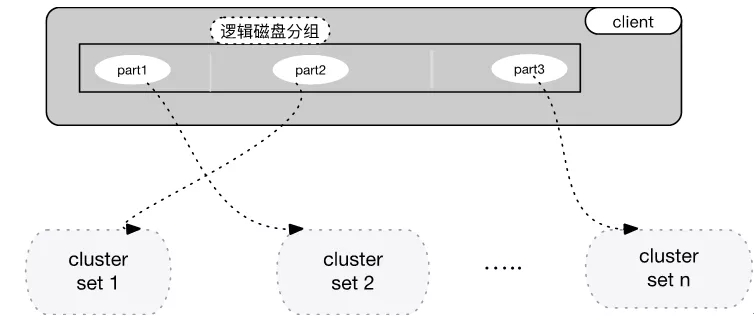
因此,我們計劃將用戶申請的邏輯盤,進行分Part, 每個Part可以申請再不用的Set中,從而具備容量可以無限擴展的能力。
2、超高性能存儲
近10年,硬盤經過 HDD -> SATA SSD -> NVME SSD的發展。同時,網絡接口也經歷了10G -> 25G -> 100G的跨越式發展。然而CPU主頻幾乎沒有較大發展,平均在2-3GHZ,我們使用的一臺物理機可以掛6-8塊NVME盤,意味著一臺物理機可以提供300-500萬的IOPS。
傳統應用服務器軟件模式下,基于TCP的Epoll Loop, 網卡的收發包,IO的讀寫要經過用戶態、內核態多層拷貝和切換,并且需要靠內核的中斷來喚醒,軟件很難壓榨出硬件的全部能力。例如在IOPS和時延上,只能靠疊加線程去增加IOPS,然而,IOPS很難隨著線程的增加而線性增長,此外時延抖動也較高。
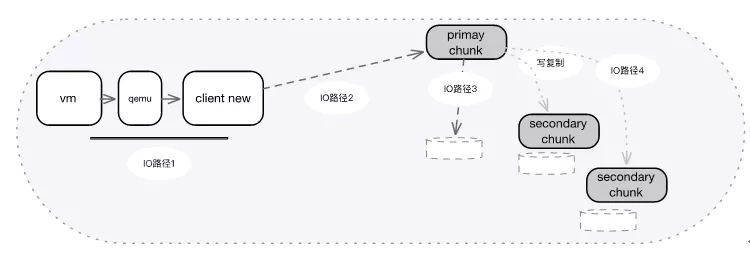
我們希望通過引入零拷貝、用戶態、輪詢的技術方案來優化上圖中的三種IO路徑,從而減少用戶態、內核態、協議棧的多層拷貝和切換,并結合輪詢一起壓榨出硬件的全部能力。
最終,我們選擇了RDMA,VHOST,SPDK三個技術方案。
- 方案一:超高性能存儲-VHOST
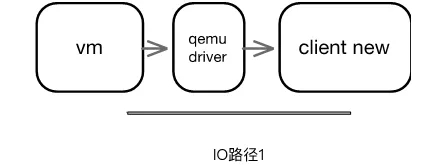
傳統模式如下,IO經過虛機和Qemu驅動,再經過UnixDomain Socket到Client。經過多次用戶態內核態,以及IO路徑上的拷貝。
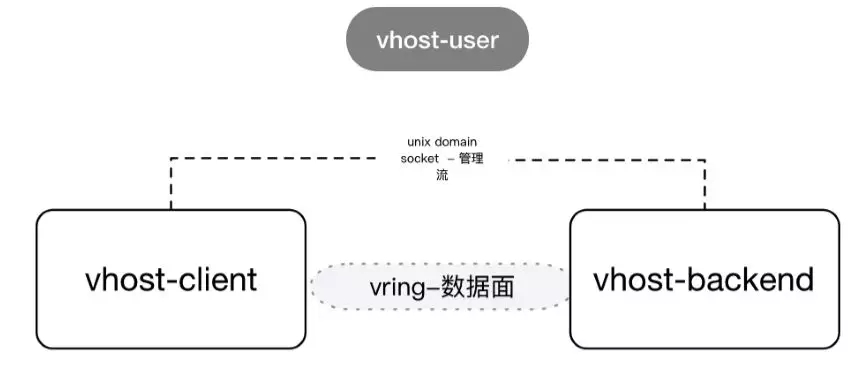
而利用VHOST User模式,可以利用共享內存進行用戶態的VM到Client側的數據傳輸。在實際中,我們利用了SPDK VHOST。

研發環境中,我們將Client收到IO請求后立即模擬返回給VM,也就是不向存儲后端發送數據,得到的數據如上圖。單隊列時延可以降低90us,IOPS有幾十倍的提升。
- 方案二:超高性能存儲-RDMA+SPDK
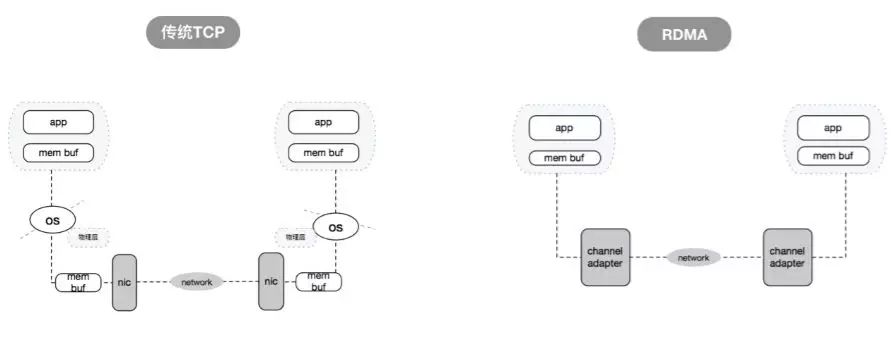
RDMA提供了一種消息服務,應用程序利用RDMA可以直接訪問遠程計算機上的虛擬內存,RDMA減少了CPU占用以及內存帶寬瓶頸,提供了很高的帶寬,并利用Stack Bypass和零拷貝技術,提供了低延遲的特性。

SPDK可以在用戶態高并發零拷貝地以用戶態驅動直接訪問NVME 固態硬盤。并利用輪詢模式避免了內核上下文切換和中斷處理帶來的開銷。
目前團隊正在研發利用RDMA和SPDK的存儲引擎框架,研發測試環境中,后端用一塊NVME固態盤,我們在單隊列和IOPS上可以提升如下:
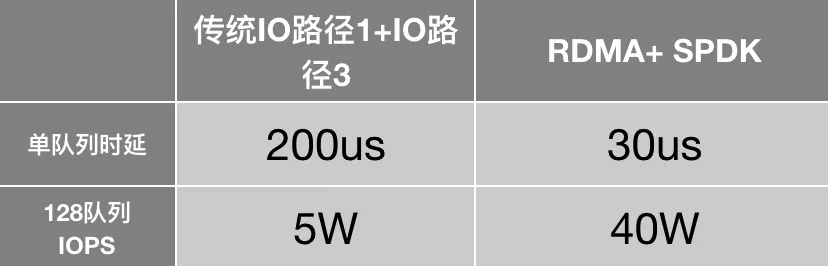
包括SPDK VHOST USER的Client側,以及RDMA+SPDK的存儲側方案,預計12月會推出公測版。
總結
過去的一年時間里,我們重新設計和優化了云盤的存儲架構,解決了過去老架構的諸多問題,并大幅提升了性能。經過4個月公測,SSD云盤和新架構普通云盤都于8月份全量上線,并保持了極高的穩定性,目前單盤可提供2.4W IOPS。





















