













Ruby 3發布,為何性能能提升3倍
對于所有Rubyists來說,2020年是特殊的一年。難道不是這樣么?Ruby 2于2013年發布,我們使用Ruby 2.x已有7年之久,我們一直在等待Ruby 3的發布。
終于,等待結束了。我們終于在圣誕期間迎來了Ruby 3.0.0,它為這種高級通用編程語言提供了更高的性能和其他功能,這不啻給我們最好的圣誕節禮物。現在是時候拆開禮品盒了,看看我們得到的所有Ruby 3功能。

Ruby 3.0的開發著眼于更高的性能、并發性和類型,并成功實現了比Ruby 2.0的性能快3.0倍的目標。3.0倍速是在使用新的Ruby 3.0的Just-In-Time(JIT)運行時編譯器時實現的,但與Ruby 2相比,就其VM實現而言,仍然是相當可觀的提速。
也許有人會問,為什么把Ruby 3.0的性能提速跟Ruby 2.0對比,而不是諸如Ruby 2.7?請去官網閱讀發行說明,將性能提高3倍是2015年的既定目標。
Ruby3.0的JIT表現出非常出色的性能,非常適合需要多次調用幾種方法的工作負載。Ruby 3.1有望為需要更多調用方法的工作負載提高JIT性能。
Ruby 3.0還為并行執行功能提供了實驗性的"Ractor",而無需考慮線程安全性;Fiber Scheduler允許攔截阻塞操作、改進靜態分析、改進的單行模式匹配以及許多其他更改。
Ruby 3主要更新
數字3在Ruby 3版本中非常有意義。它是發布版本號,使性能提高了3倍,核心貢獻者(Matz,TenderLove和Koichi)也是三人組。同樣,Ruby 3有3個主要目標:更快、并發性更好并確保正確性。
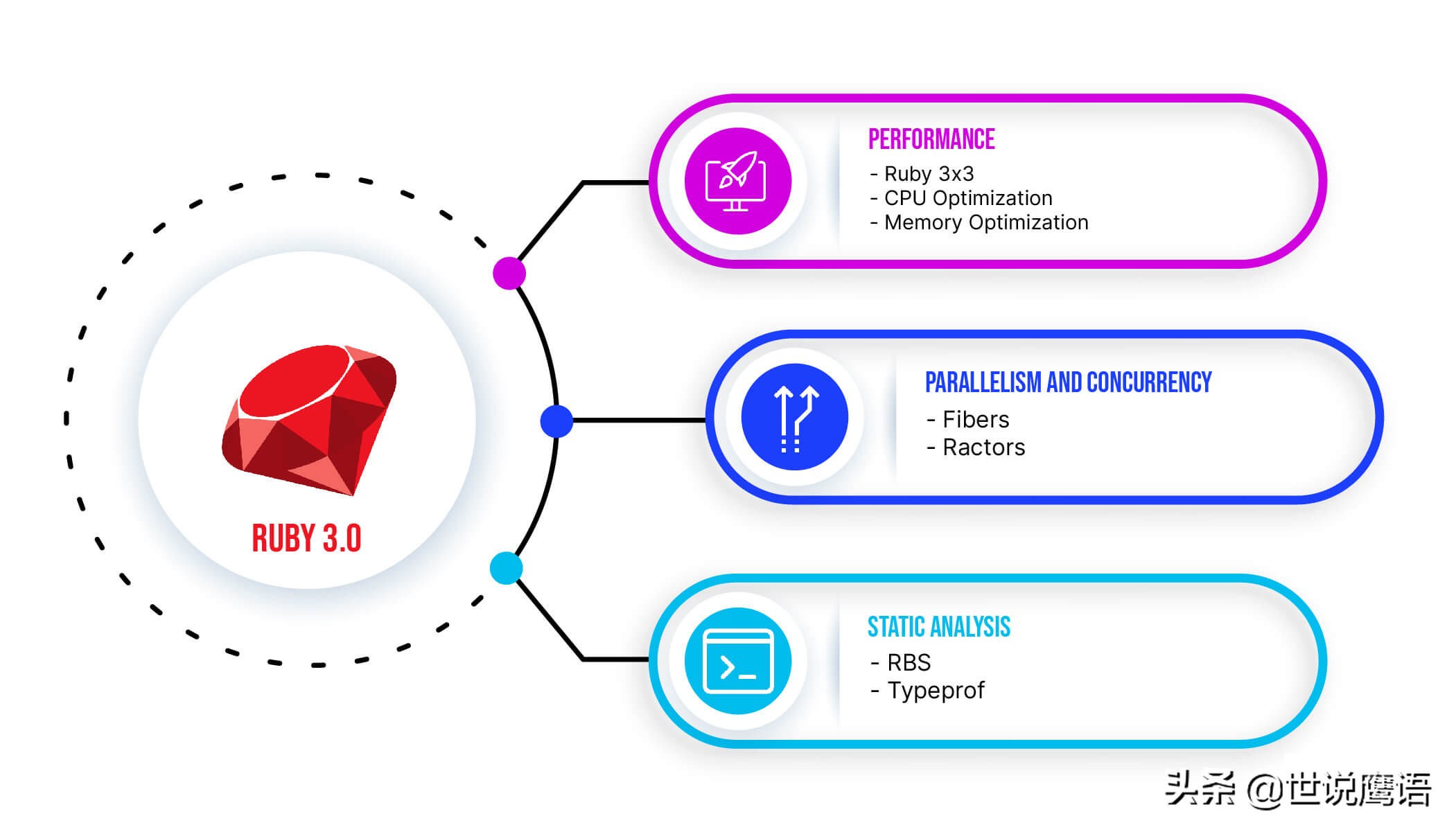
1. Ruby 3性能
性能是Ruby 3的主要關注重點之一。實際上,圍繞Ruby 3,開發者團隊內部最初就進行了討論。Ruby創始人Matz(松本行弘)于2015年設定了一個雄心勃勃的目標,就是將Ruby的速度提高3倍。
什么是Ruby 3x3?
在討論這一點之前,讓我們重新審視Ruby的核心理念。
Matz說到:"我希望看到Ruby幫助世界上的每個程序員提高生產力,享受編程并感到幸福。"
關于Ruby 3x3,有人問是否目標是使Ruby成為最快的語言?答案是不。Ruby 3x3的主要目標是使Ruby的速度比Ruby 2快3倍。
Matz談到:"沒有一種語言足夠快。"
Ruby并非為追求速度最快而設計,如果這是目標,那么Ruby將不會是今天這種局面。隨著Ruby語言性能的提高,它無疑有助于我們的應用程序更快且可擴展。
Matz坦承:"在Ruby語言的設計中,我們主要集中在生產力和編程樂趣上。結果,Ruby太慢了。"
可以衡量性能的區域有兩個:內存和CPU。
CPU優化
Ruby中已進行了一些增強,以提高速度。Ruby團隊從以前的版本中優化了JIT(Just In Time)編譯器。Ruby MJIT編譯器最早是在Ruby 2.6中引入的。Ruby 3 MJIT具有更好的安全性,并且似乎在很大程度上提高了Web應用程序的性能。
MJIT的實現不同于通常的JIT。當方法被反復調用(例如10000次)時,MJIT將選擇可以編譯為本機代碼的方法并將其放入隊列。稍后MJIT將獲取隊列并將其轉換為本地代碼。
內存優化
Ruby 3帶有增強的垃圾收集器。它具有類似python的緩沖區的API,有助于更好地利用內存。從Ruby 1.8開始,Ruby在垃圾回收算法方面不斷進步。
自動垃圾壓縮
垃圾收集的最新變化是垃圾壓縮。它是在Ruby 2.7中引入的,該過程有點手動。但是在版本3中,它是全自動的,適當調用壓縮程序以確保適當的內存利用率。
對象分組
垃圾壓縮器移動堆中的對象。它將分散的對象組合在一起放在內存中的某個位置,以便后面更大的對象可以有效利用內存。
2. Ruby 3中的并行性和并發性
并發是任何編程語言的重要關注點之一。Matz認為Ruby程序員未能正確地使用線程這一抽象層。
Matz表示:"我很遺憾添加線程。"
Ruby 3使應用程序并發運行變得容易得多。Ruby 3中增加了一些與并發相關的功能和改進。
Fibers
在Ruby 3中,Fibers的引進被認為是突破性的。Fibers是輕量級工作線程,看起來像線程,但具有一些優勢。它比線程消耗更少的內存。它為程序員提供了更大的控制權,使其可以定義可以暫停或恢復的代碼段,從而實現更好的I/O處理。
Fiber Scheduler
Fiber Scheduler是Ruby 3中添加的一項實驗性功能。它被引入來攔截諸如I/O之類的阻塞操作。可喜的是,它允許輕量級并發,并且可以輕松集成到現有代碼庫中,而無需更改原始代碼邏輯。這是一個接口,可以通過諸如EventMachine或Async之類的gem創建包裝器來引入,此接口設計允許事件循環實現與應用程序代碼之間的關注點分離。
以下是HTTP使用并發發送多個請求的示例Async。
- require 'async'
- require 'net/http'
- require 'uri'
- LINKS = [
- 'https://xmyy.com',
- 'https://www.xmyy.com'
- ]
- Async do
- LINKS.each do |link|
- Async do
- Net::HTTP.get(URI(link))
- end
- end
- end
Ractors(Guilds)
眾所周知,Ruby的globalVM lock(GVL)阻止大多數Ruby線程并行計算。Ractor可以解決此問題,GVL可以提供更好的并行性。Ractor是類似于Actor-Model的并發抽象,旨在提供并行執行而無需擔心線程安全。
Ractors允許不同Ractor中的線程同時計算。每個Ractor具有至少一個線程,該線程可以包含多個Fibers。在Ractor中,在給定的時間只允許執行一個線程。
以下程序返回一個非常大的平方根。它并行計算兩個數字的結果。
- # Math.sqrt(number) in ractor1, ractor2 run in parallel
- ractor1, ractor2 = *(1..2).map do
- Ractor.new do
- number = Ractor.recv
- Math.sqrt(number)
- end
- end
- # send parameters
- ractor1.send 3**71
- ractor2.send 4**51
- p ractor1.take #=> 8.665717809264115e+16
- p ractor2.take #=> 2.251799813685248e+15
3.靜態分析
我們需要測試以確保我們程序的正確性。但是,從本質上講,測試可能意味著重復的代碼工作。
Matz甚至吐槽:"我討厭測試,因為它不是人干的。"
為了確保程序的正確性,除了測試之外,靜態分析是個不錯的工具。
靜態分析依賴于內聯類型注釋。解決此難題的解決方案是使.rbs文件與我們的.rb文件平行。
RBS
RBS是一種描述Ruby程序結構的語言。它為我們提供了該程序的概述,以及如何定義整體類,方法等。使用RBS,我們可以編寫Ruby類、模塊、方法、實例變量、變量類型和繼承的定義。它支持Ruby代碼中的常用模式以及高級類型(如并集和鴨子duck typing類型)。
這些.rbs文件類似于.d.tsTypeScript中的文件。以下是一個.rbs文件外觀的小例子。具有類型定義的優點是可以針對實現和執行進行驗證。
下面的示例是不言自明的。我們需要在這里注意的一件事是each_post接受一個塊或返回一個枚舉器。
- # user.rbs
- class User
- attr_reader name: String
- attr_reader email: String
- attr_reader age: Integer
- attr_reader posts: Array[Post]
- def initialize: (name: String,
- email: String,
- age: Integer) -> void
- def each_post: () { (Post) -> void } -> void
- | () -> Enumerator[Post, void]
- end
其他值得注意的變化
- 粘貼到IRB中的速度要快得多。
- 回溯的順序已顛倒。首先打印錯誤消息和行號,然后打印其余的跟蹤信息。
- Hash#transform_keys 接受將舊密鑰與新密鑰映射的哈希。
- 插值字符串文字在# frozen-string-literal: true使用時不再凍結。
- Symbol#to_proc現在返回一個lambda Proc。
- 添加了Symbol#name ,它以凍結的字符串形式返回符號的名稱。
過渡
為了滿足Ruby 3的目標需求,許多核心庫已經作了修改。但這并不意味著我們的舊應用程序會突然停止工作。Ruby團隊已確保這些更改向后兼容。我們可能會在現有代碼中看到一些棄用警告。開發人員可以修復這些警告,以從舊版本平穩過渡到新版本。我們都準備使用新功能并希冀從新的性能改進中受益。
結論
隨著性能、內存利用率、靜態分析以及Ractors和Scheduler等新功能的極大改進,我們對Ruby的未來充滿信心。使用Ruby 3,應用程序可以具有更大的可伸縮性和更令人愉快的使用。即將到來的2021年不僅是所有Rubyists的新年,而且是一個新時代。











