我們常說的內存是怎么分配的,如何減少內存浪費是大難題
說到內存的分配方式,就不得不提連續分配方式。這種方式是指為一個用戶程序分配一個連續的內存空間,它曾被廣泛的用于20世紀60~70年代的OS中,至今仍被使用。連續分配方式可以進一步分為單一連續分配、固定分配方式、動態分區分配以及動態重定位分配。
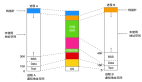
單一連續分配,是最簡單的一種存儲管理方式,只能用于單用戶、單任務的OS中。它將內存分為系統區和用戶區,系統區僅提供給OS使用,除了系統區之外的內存空間全部都是用戶區,用戶區通常放在高址部分,系統區則放在低址部分。
固定分區分配,這是在多道程序環境下最簡單的存儲管理方式。將內存分成多個固定大小的區域,每個區域只裝入一道作業,便能允許幾道作業并發運行。有空閑分區時,就能從后備隊列選擇一個裝入該分區。
固定分區分配有兩種劃分分區的方式:分區大小相等,不過由于缺乏靈活性,程序過小會浪費內存,過大則無法運行。不過在控制多個相同的對象的場合還說可以使用的;分區大小不等,則是將分區劃分時含有多個較小的分區、適量的中等分區以及少量大分區,可根據程序大小分配適當的分區。
我們為了便于內存分配,通常將分區按大小進行排隊,并為之建立一張分區使用表,表項報告各分區的初始地址、大小及狀態。固定分區是最早的多道程序的存儲管理方式,現在雖然過時了,不過在某些控制多個相同對象的系統中還會使用。
動態分區分配,這是根據進程的實際需要,動態地為之分配內存空間。主要涉及分區分配中所用的數據結構、分區分配算法和分區的分配與回收這三個問題。
分區分配中的數據結構,主要用來描述空閑分區和已分配分區的情況,為分配提供依據。常用的數據結構有兩種形式:空閑分區表,用于記錄每個空閑分區的全靠,每個空閑分區占一個表目;空閑分區鏈,也是為了方便使用空閑分區,在每個分區的起始位置和尾部添加前向和后向指針。
分區分配算法,將一個新罪業裝入內存,須按照一定的分配算法,從空閑分區表或空閑分區鏈中選出一空閑分區給該作業。目前大致有五種分配算法。
***適應算法,將空閑分區鏈以地址遞增的次序鏈接,分配內存時從頭開始查找,只要找到一塊空閑區域滿足作業大小要求,就將其分配,余下的空閑分區仍留在空閑鏈。由于此算法傾向利用低址部分的空閑分區,所以低址部分會不斷被劃分,留下許多難以利用的空閑分區。
循環***適應算法,在***適應算法的基礎上,不會每次都從鏈首開始查找,而是從上次找到的空閑分區的下一個空閑分區開始查找。需要設置起始查尋指針,指示下一次起始查詢的空閑分區,并采用循環查找方式。這種算法雖然減少了查找空閑分區時的開銷,但是會缺乏大的空閑分區。
***適應算法,總是能把滿足要求、又是最小的空閑分區分配給作業。為實現此算法,需要將空閑分區按從小到大的順序形成一空閑分區鏈。但是,每次分割所留下的剩余部分總是最小的,***會留下許多難以利用的小空閑區。
最壞適應算法,會掃描整個空閑分區表,總是挑選***的空閑分區分割給作業,要求空閑區按從大到小排列。優點是可使剩下的空閑區不至于太小,產生碎片的幾率最小,同時查找效率***。缺點是會使存儲器缺乏大的空閑分區。
以上四種算法被稱為順序搜索法,而下面這個算法被稱為分類搜索法。
快速適應算法,先將空閑分區按容量大小分類,每一類單獨設立空閑分區鏈表。同時在內存中設立一張管理索引表,每一表項對應一種空閑分區類型。而且空閑分區的分類是根據進程常用的空間大小劃分的,方便分配空閑分區。此算法的優點是查找效率高,而且不會對分區產生分割,能保留大的分區,也不會產生內存碎片。缺點是分區歸還主存時算法復雜,系統開銷較大。另外此算法分配時以進程為單位,一個分區屬于一個進程,在分配的一個分區中,或多或少存在一定的浪費。空閑分區劃分越細,浪費越嚴重。
分區的分配與回收,系統利用某種分配算法從空閑分區表找到所需大小的分區,裝入空閑分區的作業占用空間后,剩余的部分很小則不再切割,反之則將其劃分出去。當作業或者進程運行完畢后釋放內存,系統根據回收區的首址,從空閑區鏈表中找到相應的插入點,將其與相鄰空閑區合并。