大數(shù)據(jù)分析師的日常,聽起來高大上,其實干的活四個字臟亂差累
哇,互聯(lián)網(wǎng)大數(shù)據(jù)分析師,聽起來好高大上哦,其實不然,做的事情都是***層的事情,打雜的,是業(yè)務的仆人,為全公司的人服務。
在你的眼里他們待遇好,白領,掙的錢多!
錢是人力堆出來的
在你的眼里他們制作報表,看起來好高大上,很炫酷,很漂亮!
在你的眼里他們是大數(shù)據(jù)領域的工作者,處于時代的前列,很潮!
數(shù)據(jù)種類多,量大,變化快
其實他們就是一群搬磚的。
般的是磚,賣的是苦力
- 臟:是數(shù)據(jù)很臟,什么空值啊,亂碼啊,數(shù)據(jù)重復啊,什么情況都有。
- 亂:也是數(shù)據(jù)亂,數(shù)據(jù)源很多比如來源于app的,web端的,日志,外部api等等,要理清邏輯,清洗數(shù)據(jù),清晰的分層,需要下很多功夫。
- 差:首先是公司條件'差',然后是狀態(tài)差,因為經(jīng)常加班,***是業(yè)務多('差')。
- 累:清洗數(shù)據(jù),制作報表和分析報告,很累,過程很漫長,而且需要加班。
他們天天要用hue跑數(shù)據(jù),對數(shù)據(jù),有時候還會碰到數(shù)據(jù)傾斜問題,如果沒找到原因,會跑一天時間,還沒驗證數(shù)據(jù);
有時候為了驗證數(shù)據(jù)和倉庫工程師吵架,有時候是為了取數(shù)口徑,有時候為了調(diào)度,數(shù)據(jù)為什么還沒出來,各種扯皮的事情;
有時候?qū)?shù)據(jù)和業(yè)務還有運營吵架,有可能是為了需求,有可能是為了口徑;
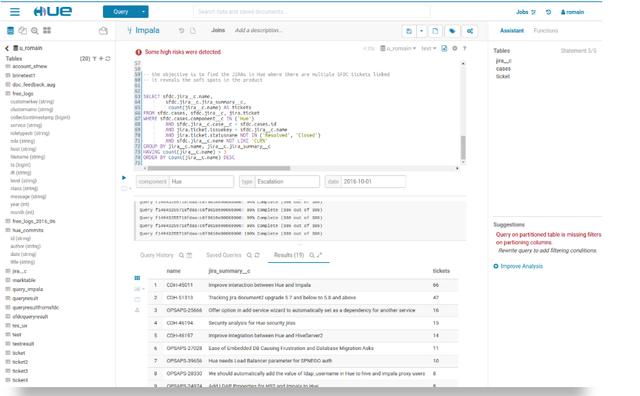
Hadoop組建hue
記得一次為了趕公司的kpi報表,公司從大數(shù)據(jù)平臺組,大數(shù)據(jù)倉庫組,大數(shù)據(jù)分析組和大數(shù)據(jù)挖掘組都在加班,確保萬無一失,他們是這樣分工的:
- 大數(shù)據(jù)平臺組:負責大數(shù)據(jù)集群穩(wěn)定運行,負責大數(shù)據(jù)產(chǎn)品的后端開發(fā)。
- 大數(shù)據(jù)倉庫組:負責數(shù)據(jù)倉庫的開發(fā),把各個指標從底層ods開始計算到dm應用層。
- 大數(shù)據(jù)分析組:負責取數(shù)口徑的確認,倉庫工程師開發(fā)的報表驗證,有時候自己開發(fā)。
- 大數(shù)據(jù)挖掘組:對有些指標需要機器學習分析出來的,所以他們也要加班。
經(jīng)過一個星期的加班加點,成果終于出來的,然額并沒有什么卵用嗎,老板不一定認可。
重來,重來,重來,老板說了三遍,我們很尷尬,分析師更尷尬,因為口徑都是這里來的。
不僅做的事情有時候得不到認可,而且沒有成就感。
在我們團隊中,分析組加班是最多的,有時候還要做倉庫的事情,有時候還要管調(diào)度,驗證數(shù)據(jù)。
有時候?qū)懘a的時候還是***興的,我們用的工具主要是pycharm,hive,sparksql,shell ,網(wǎng)易有數(shù),這個時候犯錯了還能改,bug可以修復。
python功能還是很強大的,我們既可以用來做報表,又可以用來發(fā)郵件,又可以用來運維,又可以用來挖掘,簡直是全能王。
功能強大的python,什么都可以做
shell是我們部署腳本線上運行的利器。
sparksql基于內(nèi)存運算的大數(shù)據(jù)組建,有事給我們驗證數(shù)據(jù)帶來方便,我們很是喜歡。
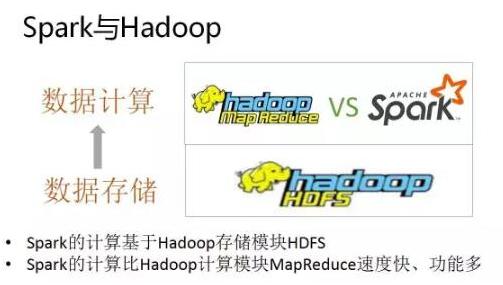
spark和hadoop比較
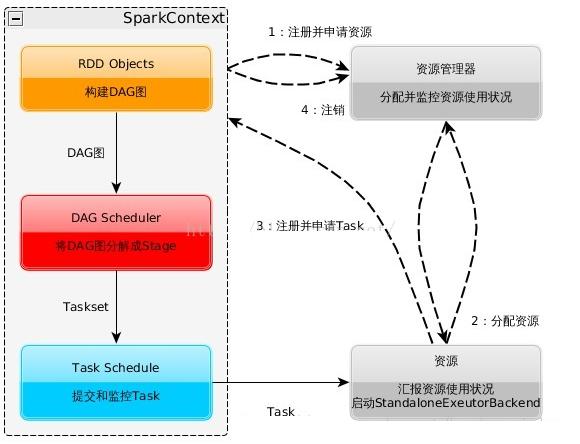
spark 原理
分析工作看起來簡單,做起來很難,需要掌握的很多,路漫漫其修遠兮,吾將上下而求索。
想進入這個行業(yè)的同學做好心里準備,加班多,待遇不一定好,等有了經(jīng)驗可能會好一些。