Hadoop大數(shù)據(jù)通用處理平臺
Hadoop是一款開源的大數(shù)據(jù)通用處理平臺,其提供了分布式存儲和分布式離線計算,適合大規(guī)模數(shù)據(jù)、流式數(shù)據(jù)(寫一次,讀多次),不適合低延時的訪問、大量的小文件以及頻繁修改的文件。
*Hadoop由HDFS、YARN、MapReduce組成。
如果想學(xué)習(xí)Java工程化、高性能及分布式、深入淺出。微服務(wù)、Spring,MyBatis,Netty源碼分析的朋友可以加我的Java高級交流:854630135,群里有阿里大牛直播講解技術(shù),以及Java大型互聯(lián)網(wǎng)技術(shù)的視頻免費分享給大家。
Hadoop的特點:
- 高擴展(動態(tài)擴容):能夠存儲和處理千兆字節(jié)數(shù)據(jù)(PB),能夠動態(tài)的增加和卸載節(jié)點,提升存儲能力(能夠達到上千個節(jié)點)
- 低成本:只需要普通的PC機就能實現(xiàn),不依賴高端存儲設(shè)備和服務(wù)器。
- 高效率:通過在Hadoop集群中分化數(shù)據(jù)并行處理,使得處理速度非常快。
- 可靠性:數(shù)據(jù)有多份副本,并且在任務(wù)失敗后能自動重新部署。
Hadoop的使用場景:
- 日志分析,將數(shù)據(jù)分片并行計算處理。
- 基于海量數(shù)據(jù)的在線應(yīng)用。
- 推薦系統(tǒng),精準(zhǔn)營銷。
- 搜索引擎。
Hadoop生態(tài)圈:
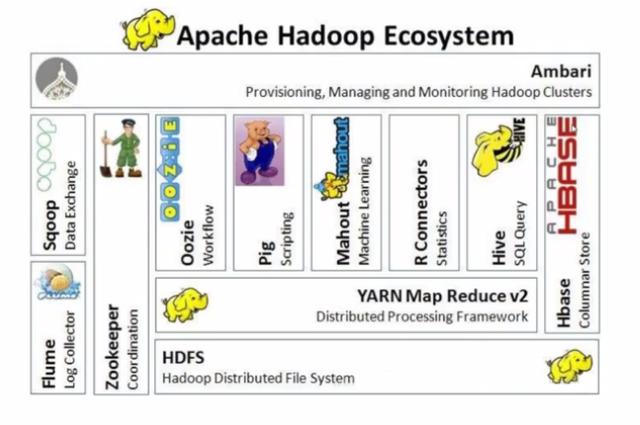
- Hive:利用Hive可以不需要編寫復(fù)雜的Hadoop程序,只需要寫一個SQL語句,Hive就會把SQL語句轉(zhuǎn)換成Hadoop的任務(wù)去執(zhí)行,降低使用Hadoop離線計算的門檻。
- HBase:海量數(shù)據(jù)存儲的非關(guān)系型數(shù)據(jù)庫,單個表中的數(shù)據(jù)能夠容納百億行x百萬列。
- ZooKeeper:監(jiān)控Hadoop集群中每個節(jié)點的狀態(tài),管理整個集群的配置,維護節(jié)點間數(shù)據(jù)的一致性。
- Flume:海量日志采集系統(tǒng)。
2.內(nèi)部結(jié)構(gòu)
2.1 HDFS
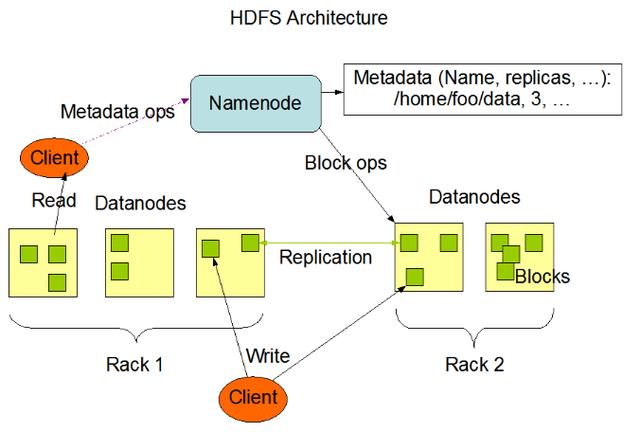
HDFS是分布式文件系統(tǒng),存儲海量的文件,其中HDFS中包含NameNode、DataNode、SecondaryNameNode組件等。
Block數(shù)據(jù)塊
- HDFS中基本的存儲單元,1.X版本中每個Block默認是64M,2.X版本中每個Block默認是128M。
- 一個大文件會被拆分成多個Block進行存儲,如果一個文件少于Block的大小,那么其實際占用的空間為文件自身大小。
- 每個Block都會在不同的DataNode節(jié)點中存在備份(默認備份數(shù)是3)
DataNode
- 保存具體的Blocks數(shù)據(jù)。
- 負責(zé)數(shù)據(jù)的讀寫操作和復(fù)制操作。
- DataNode啟動時會向NameNode匯報當(dāng)前存儲的數(shù)據(jù)塊信息。
NameNode
- 存儲文件的元信息和文件與Block、DataNode的關(guān)系,NameNode運行時所有數(shù)據(jù)都保存在內(nèi)存中,因此整個HDFS可存儲的文件數(shù)受限于NameNode的內(nèi)存大小。
- 每個Block在NameNode中都對應(yīng)一條記錄,如果是大量的小文件將會消耗大量內(nèi)存,因此HDFS適合存儲大文件。
- NameNode中的數(shù)據(jù)會定時保存到本地磁盤中(只有元數(shù)據(jù)),但不保存文件與Block、DataNode的位置信息,這部分數(shù)據(jù)由DataNode啟動時上報和運行時維護。
*NameNode不允許DataNode具有同一個Block的多個副本,所以創(chuàng)建的副本數(shù)量是當(dāng)時DataNode的總數(shù)。
*DataNode會定期向NameNode發(fā)送心跳信息,一旦在一定時間內(nèi)NameNode沒有接收到DataNode發(fā)送的心跳則認為其已經(jīng)宕機,因此不會再給它任何IO請求。
*如果DataNode失效造成副本數(shù)量下降并且低于預(yù)先設(shè)置的閾值或者動態(tài)增加副本數(shù)量,則NameNode會在合適的時機重新調(diào)度DataNode進行復(fù)制。
SecondaryNameNode
- 定時與NameNode進行同步,合并HDFS中系統(tǒng)鏡像,定時替換NameNode中的鏡像。
HDFS寫入文件的流程
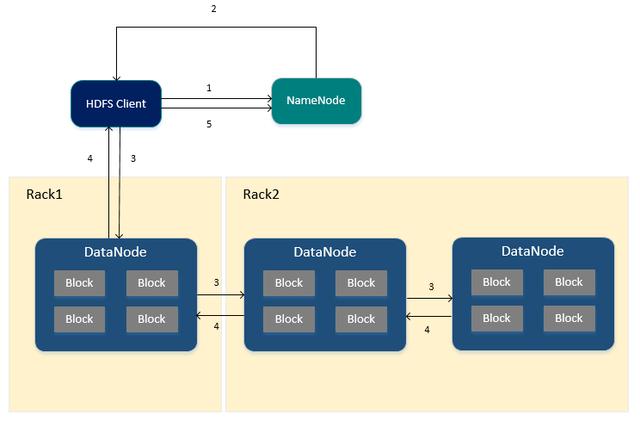
- HDFS Client向NameNode申請寫入文件。
- NameNode根據(jù)文件大小,返回文件要寫入的DataNode列表以及Block id (此時NameNode已存儲文件的元信息、文件與DataNode、Block之間的關(guān)系)
- HDFS Client收到響應(yīng)后,將文件寫入第一個DataNode中,第一個DataNode接收到數(shù)據(jù)后將其寫入本地磁盤,同時把數(shù)據(jù)傳遞給第二個DataNode,直到寫入備份數(shù)個DataNode。
- 每個DataNode接收完數(shù)據(jù)后都會向前一個DataNode返回寫入成功的響應(yīng),最終第一個DataNode將返回HDFS Client客戶端寫入成功的響應(yīng)。
- 當(dāng)HDFS Client接收到整個DataNodes的確認請求后會向NameNode發(fā)送最終確認請求,此時NameNode才會提交文件。
*當(dāng)寫入某個DataNode失敗時,數(shù)據(jù)會繼續(xù)寫入其他的DataNode,NameNode會重新尋找DataNode繼續(xù)復(fù)制,以保證數(shù)據(jù)的可靠性。
*每個Block都會有一個校驗碼并存放在獨立的文件中,以便讀的時候來驗證數(shù)據(jù)的完整性。
*文件寫入完畢后,向NameNode發(fā)送確認請求,此時文件才可見,如果發(fā)送確認請求之前NameNode宕機,那么文件將會丟失,HDFS客戶端無法進行讀取。
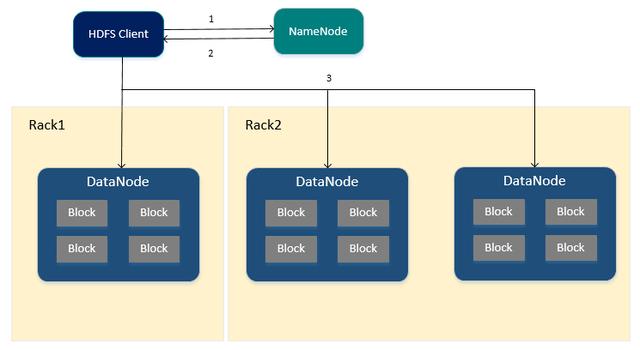
HDFS讀取文件的流程
如果想學(xué)習(xí)Java工程化、高性能及分布式、深入淺出。微服務(wù)、Spring,MyBatis,Netty源碼分析的朋友可以加我的Java高級交流:854630135,群里有阿里大牛直播講解技術(shù),以及Java大型互聯(lián)網(wǎng)技術(shù)的視頻免費分享給大家。
- HDFS Client向NameNode申請讀取指定文件。
- NameNode返回文件所有的Block以及這些Block所在的DataNodes中(包括復(fù)制節(jié)點)
- HDFS Client根據(jù)NameNode的返回,優(yōu)先從與HDFS Client同節(jié)點的DataNode中直接讀取(若HDFS Client不在集群范圍內(nèi)則隨機選擇),如果從DataNode中讀取失敗則通過網(wǎng)絡(luò)從復(fù)制節(jié)點中進行讀取。
機架感知
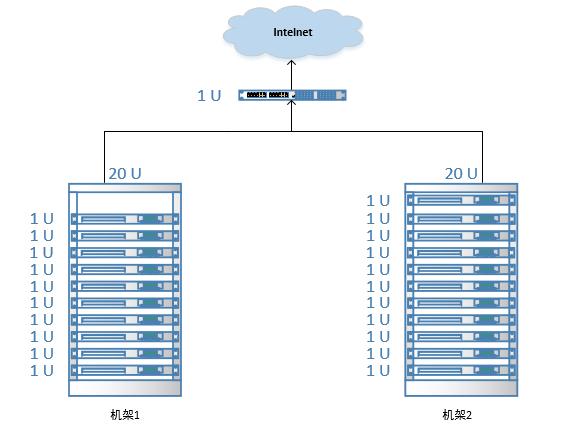
分布式集群中通常包含非常多的機器,由于受到機架槽位和交換機網(wǎng)口的限制,通常大型的分布式集群都會跨好幾個機架,由多個機架上的機器共同組成一個分布式集群。
機架內(nèi)的機器之間的網(wǎng)絡(luò)速度通常都會高于跨機架機器之間的網(wǎng)絡(luò)速度,并且機架之間機器的網(wǎng)絡(luò)通信通常受到上層交換機間網(wǎng)絡(luò)帶寬的限制。
Hadoop默認沒有開啟機架感知功能,默認情況下每個Block都是隨機分配DataNode,需要進行相關(guān)的配置,那么在NameNode啟動時,會將機器與機架的對應(yīng)信息保存在內(nèi)存中,用于在HDFS Client申請寫文件時,能夠根據(jù)預(yù)先定義的機架關(guān)系合理的分配DataNode。
Hadoop機架感知默認對3個副本的存放策略為:
- 第1個Block副本存放在和HDFS Client所在的節(jié)點中(若HDFS Client不在集群范圍內(nèi)則隨機選取)
- 第2個Block副本存放在與第一個節(jié)點不同機架下的節(jié)點中(隨機選擇)
- 第3個Block副本存放在與第2個副本所在節(jié)點的機架下的另一個節(jié)點中,如果還有更多的副本則隨機存放在集群的節(jié)點中。
*使用此策略可以保證對文件的訪問能夠優(yōu)先在本機架下找到,并且如果整個機架上發(fā)生了異常也可以在另外的機架上找到該Block的副本。
2.2 YARN
YARN是分布式資源調(diào)度框架(任務(wù)計算框架的資源調(diào)度框架),主要負責(zé)集群中的資源管理以及任務(wù)調(diào)度并且監(jiān)控各個節(jié)點。
ResourceManager
- 是整個集群的資源管理者,管理并監(jiān)控各個NodeManager。
- 處理客戶端的任務(wù)請求。
- 啟動和監(jiān)控ApplicationMaster。
- 負責(zé)資源的分配以及調(diào)度。
NodeManager
- 是每個節(jié)點的管理者,負責(zé)任務(wù)的執(zhí)行。
- 處理來自ResourceManager的命令。
- 處理來自ApplicationMaster的命令。
ApplicationMaster
- 數(shù)據(jù)切分,用于并行計算處理。
- 計算任務(wù)所需要的資源。
- 負責(zé)任務(wù)的監(jiān)控與容錯。
任務(wù)運行在YARN的流程
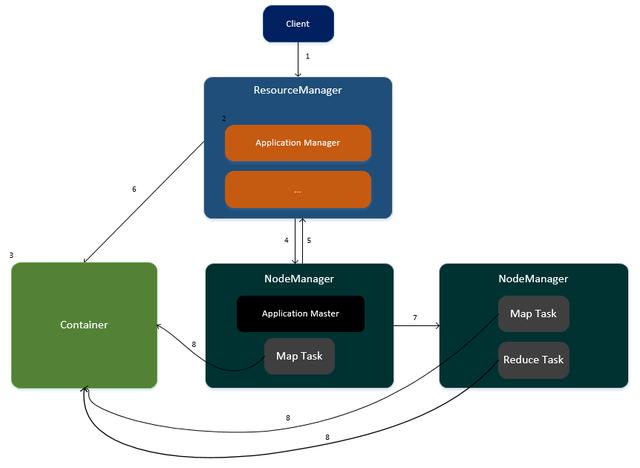
客戶端提交任務(wù)請求到ResourceManager。
- ResourceManager生成一個ApplicationManager進程,用于任務(wù)的管理。
- ApplicationManager創(chuàng)建一個Container容器用于存放任務(wù)所需要的資源。
- ApplicationManager尋找其中一個NodeManager,在此NodeManager中啟動一個ApplicationMaster,用于任務(wù)的管理以及監(jiān)控。
- ApplicationMaster向ResourceManager進行注冊,并計算任務(wù)所需的資源匯報給ResourceManager(CPU與內(nèi)存)
- ResourceManager為此任務(wù)分配資源,資源封裝在Container容器中。
- ApplicationMaster通知集群中相關(guān)的NodeManager進行任務(wù)的執(zhí)行。
- 各個NodeManager從Container容器中獲取資源并執(zhí)行Map、Reduce任務(wù)。
2.3 MapReduce
MapReduce是分布式離線并行計算框架,高吞吐量,高延時,原理是將分析的數(shù)據(jù)拆分成多份,通過多臺節(jié)點并行處理,相對于Storm、Spark任務(wù)計算框架而言,MapReduce是最早出現(xiàn)的計算框架。
MapReduce、Storm、Spark任務(wù)計算框架對比:

MapReduce執(zhí)行流程
MapReduce將程序劃分為Map任務(wù)以及Reduce任務(wù)兩部分。
Map任務(wù)處理流程
- 讀取文件中的內(nèi)容,解析成Key-Value的形式 (Key為偏移量,Value為每行的數(shù)據(jù))
- 重寫map方法,編寫業(yè)務(wù)邏輯,生成新的Key和Value。
- 對輸出的Key、Value進行分區(qū)(Partitioner類)
- 對數(shù)據(jù)按照Key進行排序、分組,相同key的value放到一個集合中(數(shù)據(jù)匯總)
*處理的文件必須要在HDFS中。
Reduce任務(wù)處理流程
- 對多個Map任務(wù)的輸出,按照不同的分區(qū),通過網(wǎng)絡(luò)復(fù)制到不同的reduce節(jié)點。
- 對多個Map任務(wù)的輸出進行合并、排序。
- 將reduce的輸出保存到文件,存放在HDFS中。
3.Hadoop的使用
3.1 安裝
由于Hadoop使用Java語言進行編寫,因此需要安裝JDK。

從CDH中下載Hadoop 2.X并進行解壓,CDH是Cloudrea公司對各種開源框架的整合與優(yōu)化(較穩(wěn)定)
- etc目錄:Hadoop配置文件存放目錄。
- logs目錄:Hadoop日志存放目錄。
- bin目錄、sbin目錄:Hadoop可執(zhí)行命令存放目錄。
etc目錄
bin目錄
sbin目錄
3.2 Hadoop配置
1.配置環(huán)境
編輯etc/hadoop/hadoop-env.sh的文件,修改JAVA_HOME配置項為本地JAVA的HOME目錄,此文件是Hadoop啟動時加載的環(huán)境變量。

編輯/etc/hosts文件,添加主機名與IP的映射關(guān)系。
2.配置Hadoop公共屬性(core-site.xml)
- <configuration>
- <!-- Hadoop工作目錄,用于存放Hadoop運行時產(chǎn)生的臨時數(shù)據(jù) -->
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/usr/hadoop/hadoop-2.9.0/data</value>
- </property>
- <!-- NameNode的通信地址,1.x默認9000,2.x可以使用8020 -->
- <property>
- <name>fs.default.name</name>
- <value>hdfs://192.168.1.80:8020</value>
- </property>
- </configuration>
3.配置HDFS(hdfs-site.xml)
- <configuration>
- <!--指定block的副本數(shù)量(將block復(fù)制到集群中備份數(shù)-1個節(jié)點的DataNode中)-->
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <!-- 關(guān)閉HDFS的訪問權(quán)限 -->
- <property>
- <name>dfs.permissions.enabled</name>
- <value>false</value>
- </property>
- </configuration>
4.配置YARN(yarn-site.xml)
- <configuration>
- <!-- 配置Reduce取數(shù)據(jù)的方式是shuffle(隨機) -->
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- </configuration>
5.配置MapReduce(mapred-site.xml)
- <configuration>
- <!-- 讓MapReduce任務(wù)使用YARN進行調(diào)度 -->
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- </configuration>
6.配置SSH
由于在啟動hdfs、yarn時都需要對用戶的身份進行驗證,因此可以配置SSH設(shè)置免密碼登錄。
- //生成秘鑰
- ssh-keygen -t rsa
- //復(fù)制秘鑰到本機
- ssh-copy-id 192.168.1.80
3.3 啟動HDFS
1.格式化NameNode
2.啟動HDFS,將會啟動NameNode、DataNode、SecondaryNameNode三個進程,可以通過jps命令進行查看。


*若啟動時出現(xiàn)錯誤,則可以進入logs目錄查看相應(yīng)的日志文件。
當(dāng)HDFS啟動完畢后,可以訪問http://localhost:50070進入HDFS的可視化管理界面,可以在此頁面中監(jiān)控整個HDFS集群的狀況并且進行文件的上傳以及下載。
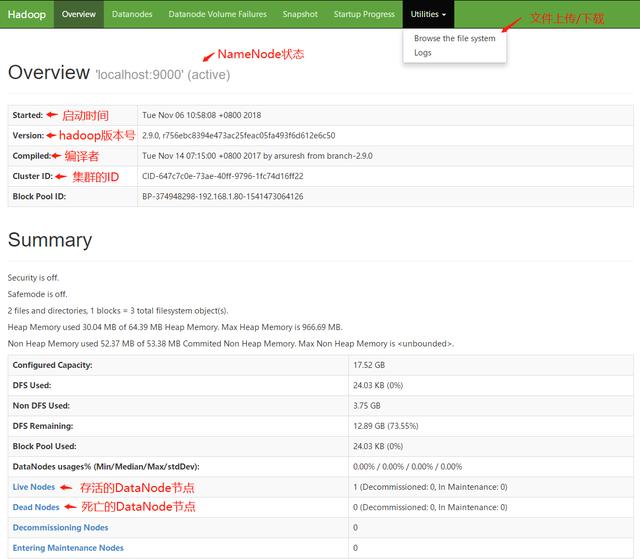
*進入HDFS監(jiān)控頁面下載文件時,會將請求重定向,重定向后的地址的主機名為NameNode的主機名,因此客戶端本地的host文件中需要配置NameNode主機名與IP的映射關(guān)系。
3.4 啟動YARN

啟動YARN后,將會啟動ResourceManager以及NodeManager進程,可以通過jps命令進行查看。

當(dāng)YARN啟動完畢后,可以訪問http://localhost:8088進入YARN的可視化管理界面,可以在此頁面中查看任務(wù)的執(zhí)行情況以及資源的分配。

3.5 使用Shell命令操作HDFS
HDFS中的文件系統(tǒng)與Linux類似,由/代表根目錄。
如果想學(xué)習(xí)Java工程化、高性能及分布式、深入淺出。微服務(wù)、Spring,MyBatis,Netty源碼分析的朋友可以加我的Java高級交流:854630135,群里有阿里大牛直播講解技術(shù),以及Java大型互聯(lián)網(wǎng)技術(shù)的視頻免費分享給大家。
- hadoop fs -cat <src>:顯示文件中的內(nèi)容。
- hadoop fs -copyFromLocal <localsrc> <dst>:將本地中的文件上傳到HDFS。
- hadoop fs -copyToLocal <src> <localdst>:將HDFS中的文件下載到本地。
- hadoop fs -count <path>:查詢指定路徑下文件的個數(shù)。
- hadoop fs -cp <src> <dst>:在HDFS內(nèi)對文件進行復(fù)制。
- hadoop fs -get <src> <localdst>:將HDFS中的文件下載到本地。
- hadoop fs -ls <path>:顯示指定目錄下的內(nèi)容。
- hadoop fs -mkdir <path>:創(chuàng)建目錄。
- hadoop fs -moveFromLocal <localsrc> <dst>:將本地中的文件剪切到HDFS中。
- hadoop fs -moveToLocal <src> <localdst> :將HDFS中的文件剪切到本地中。
- hadoop fs -mv <src> <dst> :在HDFS內(nèi)對文件進行移動。
- hadoop fs -put <localsrc> <dst>:將本地中的文件上傳到HDFS。
- hadoop fs -rm <src>:刪除HDFS中的文件。
3.6 JAVA中操作HDFS
- /**
- * @Auther: ZHUANGHAOTANG
- * @Date: 2018/11/6 11:49
- * @Description:
- */
- public class HDFSUtils {
- private static Logger logger = LoggerFactory.getLogger(HDFSUtils.class);
- /**
- * NameNode URL
- */
- private static final String NAMENODE_URL = "192.168.1.80:8020";
- /**
- * HDFS文件系統(tǒng)連接對象
- */
- private static FileSystem fs = null;
- static {
- Configuration conf = new Configuration();
- try {
- fs = FileSystem.get(URI.create(NAMENODE_URL), conf);
- } catch (IOException e) {
- logger.info("初始化HDFS連接失敗:{}", e);
- }
- }
- /**
- * 創(chuàng)建目錄
- */
- public static void mkdir(String dir) throws Exception {
- dir = NAMENODE_URL + dir;
- if (!fs.exists(new Path(dir))) {
- fs.mkdirs(new Path(dir));
- }
- }
- /**
- * 刪除目錄或文件
- */
- public static void delete(String dir) throws Exception {
- dir = NAMENODE_URL + dir;
- fs.delete(new Path(dir), true);
- }
- /**
- * 遍歷指定路徑下的目錄和文件
- */
- public static List<String> listAll(String dir) throws Exception {
- List<String> names = new ArrayList<>();
- dir = NAMENODE_URL + dir;
- FileStatus[] files = fs.listStatus(new Path(dir));
- for (FileStatus file : files) {
- if (file.isFile()) { //文件
- names.add(file.getPath().toString());
- } else if (file.isDirectory()) { //目錄
- names.add(file.getPath().toString());
- } else if (file.isSymlink()) { //軟或硬鏈接
- names.add(file.getPath().toString());
- }
- }
- return names;
- }
- /**
- * 上傳當(dāng)前服務(wù)器的文件到HDFS中
- */
- public static void uploadLocalFileToHDFS(String localFile, String hdfsFile) throws Exception {
- hdfsFile = NAMENODE_URL + hdfsFile;
- Path src = new Path(localFile);
- Path dst = new Path(hdfsFile);
- fs.copyFromLocalFile(src, dst);
- }
- /**
- * 通過流上傳文件
- */
- public static void uploadFile(String hdfsPath, InputStream inputStream) throws Exception {
- hdfsPath = NAMENODE_URL + hdfsPath;
- FSDataOutputStream os = fs.create(new Path(hdfsPath));
- BufferedInputStream bufferedInputStream = new BufferedInputStream(inputStream);
- byte[] data = new byte[1024];
- int len;
- while ((len = bufferedInputStream.read(data)) != -1) {
- if (len == data.length) {
- os.write(data);
- } else { //最后一次讀取
- byte[] lastData = new byte[len];
- System.arraycopy(data, 0, lastData, 0, len);
- os.write(lastData);
- }
- }
- inputStream.close();
- bufferedInputStream.close();
- os.close();
- }
- /**
- * 從HDFS中下載文件
- */
- public static byte[] readFile(String hdfsFile) throws Exception {
- hdfsFile = NAMENODE_URL + hdfsFile;
- Path path = new Path(hdfsFile);
- if (fs.exists(path)) {
- FSDataInputStream is = fs.open(path);
- FileStatus stat = fs.getFileStatus(path);
- byte[] data = new byte[(int) stat.getLen()];
- is.readFully(0, data);
- is.close();
- return data;
- } else {
- throw new Exception("File Not Found In HDFS");
- }
- }
- }
3.7 執(zhí)行一個MapReduce任務(wù)
Hadoop中提供了hadoop-mapreduce-examples-2.9.0.jar,其封裝了一些任務(wù)計算方法,可以直接進行調(diào)用。
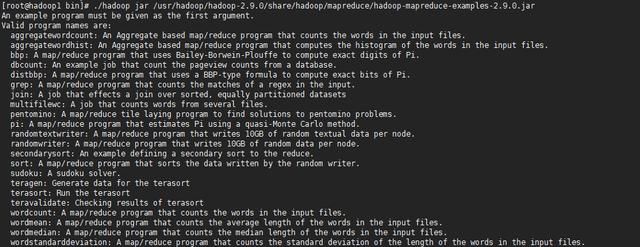
*使用hadoop jar命令執(zhí)行JAR包。
1.創(chuàng)建一個文件,將此文件上傳到HDFS中。
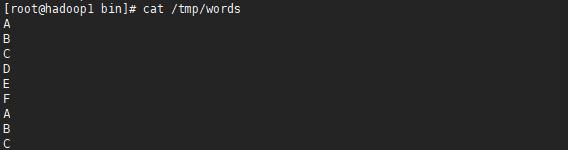
2.使用Hadoop提供的hadoop-mapreduce-examples-2.9.0.jar執(zhí)行wordcount詞頻統(tǒng)計功能,然后在YARN管理頁面中進行查看。

YARN管理頁面中可以查看任務(wù)的執(zhí)行進度:
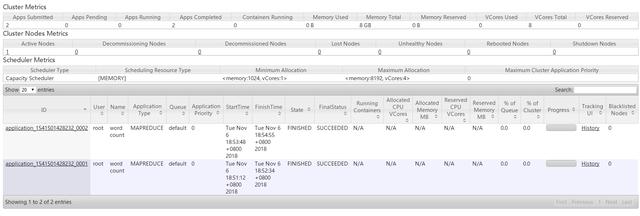
3.當(dāng)任務(wù)執(zhí)行完畢后,可以查看任務(wù)的執(zhí)行結(jié)果。

*任務(wù)的執(zhí)行結(jié)果將會放到HDFS的文件中。