數據集查找神器!100個大型機器學習數據集都匯總在這了
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
想自己構建機器學習模型,沒想到首先就卡在了***步。
網上各種數據集魚龍混雜,質量也參差不齊,簡直讓人挑花了眼。想要獲取大型數據集,還要挨個跑到各數據集的網站,兩個字:麻煩。
如何才能高效找到機器學習領域規模***、質量***的數據集?
為了響應廣大網友的呼聲,網友u/UpdraftDev將全網***的機器學習數據集整理匯集,并對這些數據集進行了分類和介紹。
想找心儀數據集,現在一目了然。網友紛紛表示:很滿意!
太方便了
這個網站上,共收集到了100多個業界***型的數據集。
根據任務類別,這些數據集中又分為三大類:計算機視覺(CV)、自然語言處理(NLP)和音頻數據集。
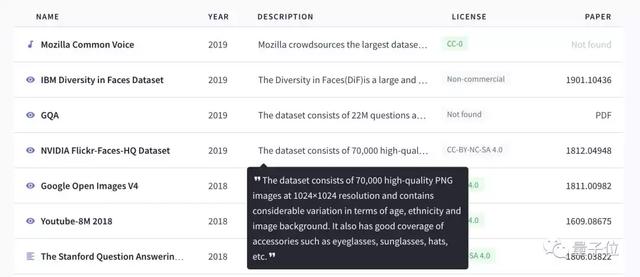
在網站主頁,一眼掃過去可以看到數據集名稱、發布時間、簡要介紹、開源協議、相關論文等重要信息,查找起來非常方便。
點進去就直接跳轉到網站主頁了,輕輕一點,免去了你挨個搜索每個數據集地址的麻煩。
神仙數據集
清單中列舉的數據集中,不乏一些有趣的業界知名數據集,在很多的機器學習任務中,這些數據集都是最實用、出現場次***的那一批。
都是哪些神仙數據集?
計算機視覺領域
先來看一下CV領域,匯總中收納了70個大型數據集,很多經常遇到的經典數據集都在里面。
看看你能認出幾個:

其中,包含了英偉達去年12月開源的人臉數據集FFHQ(Flickr-Faces-HQ),內含7萬張1024×1024分辨率的高清人臉大圖。
它提供了高度多樣化、高質量的人臉數據,并且涵蓋了比現有高分辨率數據集(如CelebA-HQ)更多的變化,比如更多佩戴眼鏡、帽子的照片。
也有一些熟悉的中國企業身影。
比如百度開放的自動駕駛數據集ApolloScape,包括感知、仿真場景、路網數據等數十萬幀逐像素語義分割標注的高分辨率圖像數據。
數據集采用了逐像素語義分割標注的方式,是環境復雜、標注精準、數據量大的自動駕駛數據集。
騰訊開源的Tencent ML-Images項目,其多標簽圖像數據集ML-Images包含了1800萬圖像和1.1萬多種常見物體類別,比谷歌開源的Open Images數據集還豐富不少。
當然,像ImageNet、KITTI、COCO、Cityscapes等這樣的老牌經典數據集也都在里面。
自然語言處理(NLP)領域
NLP領域目前有26個數據集:
斯坦福大學NLP組的SQuAD 2.0你得了解一下,和一代相比,2.0版在增加對抗性問題的同時,也新增了一項“判斷一個問題能否根據提供的閱讀文本作答”的任務。
SQuAD 2.0中不僅包含十萬個問題-答案對,還有超過五萬個由人類眾包者對抗性地設計的無法回答的問題。

CoQA數據集也是斯坦福開發的對話數據集,包含來自8k組對話的127k個帶有答案的問題。這些對話涉及 7 個不同領域,每組對話的平均長度為15輪,每一輪對話都由問題和回答組成。
此外,DeepMind的Q&A問答數據集、微軟的MS MARCO機器閱讀理解數據集、三名中國學生推出的HotpotQA新型問答數據集等,都可以在這份清單中一鍵直達。
音頻數據集
還有四個大型音頻數據集:
谷歌的大規模音頻數據集AudioSet,包含632類的音頻類別以及2084320 條人工標記的每段10秒的聲音剪輯片段,覆蓋大范圍人類與動物、樂器與音樂流派、日常環境聲音。

谷歌NSynth數據集,收錄了從1000種樂器中采集的大量注釋的音符,包括不同的音高和速率,比同類的公共數據集大了一個數量級。
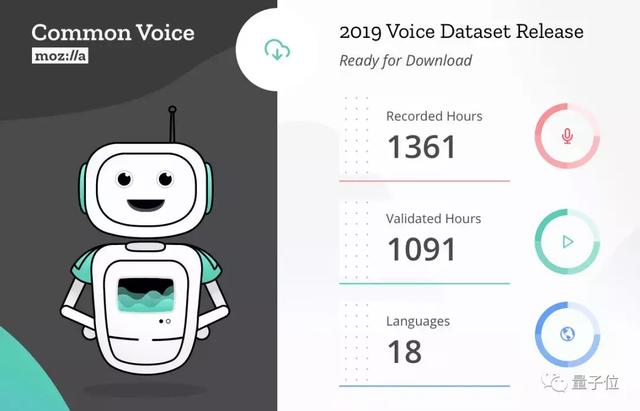
初創公司Mozilla公布的Common Voice數據集,內含2萬名英語志愿者500小時、40萬份錄音,語料庫也在不斷擴充中。
還有LibriSpeech ASR corpus語音數據集,包括1000小時的英文發音和對應文字,數據來自LibriVox項目的有聲讀物,是一個大型的語料數據庫。