如何在機器學習中處理大型數據集
如何在機器學習中處理大型數據集
不是大數據…。

數據集是所有共享一個公共屬性的實例的集合。 機器學習模型通常將包含一些不同的數據集,每個數據集用于履行系統中的各種角色。
當任何經驗豐富的數據科學家處理與ML相關的項目時,將完成60%的工作來分析數據集,我們稱之為探索性數據分析(EDA)。 這意味著數據在機器學習中起著重要作用。 在現實世界中,我們需要處理大量數據,這使得使用普通大熊貓進行計算和讀取數據似乎不可行,這似乎需要花費更多時間,并且我們的工作資源通常有限。 為了使其可行,許多AI研究人員提出了一種解決方案,以識別處理大型數據集的不同技術和方式。
現在,我將通過一些示例來分享以下技術。 在這里為實際實施,我使用的是google Colab,它的RAM容量為12.72 GB。
讓我們考慮使用隨機數從0(含)到10(不含)創建的數據集,該數據集具有1000000行和400列。
執行上述代碼的CPU時間和掛墻時間如下:

現在,讓我們將此數據幀轉換為CSV文件。
執行上述代碼的CPU時間和掛墻時間如下:

現在,使用熊貓加載現在生成的數據集(將近763 MB),然后看看會發生什么。
當您執行上述代碼時,由于RAM的不可用,筆記本電腦將崩潰。 在這里,我采用了一個相對較小的數據集,大小約為763MB,然后考慮需要處理大量數據的情況。 解決該問題的下一個計劃是什么?
處理大型數據集的技術:
1.以塊大小讀取CSV文件:
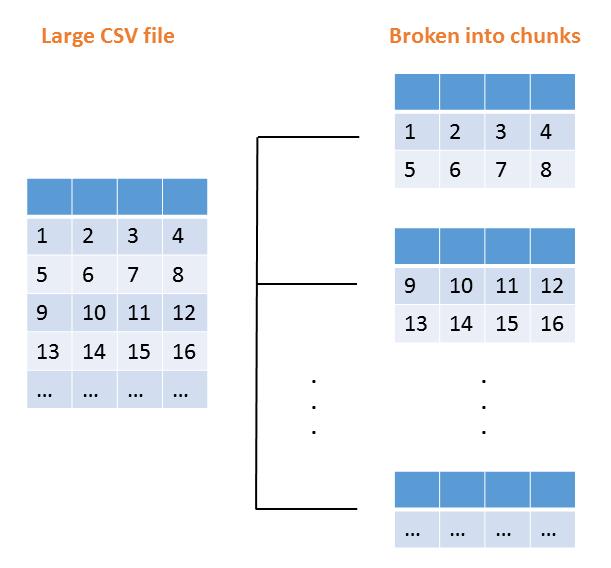
當我們通過指定chunk_size讀取大型CSV文件時,原始數據幀將被分解成塊并存儲在pandas解析器對象中。 我們以這種方式迭代對象,并連接起來以形成花費較少時間的原始數據幀。
在上面生成的CSV文件中,此文件包含1000000行和400列,因此,如果我們讀取100000行中的CSV文件作為塊大小,則
執行上述代碼的CPU時間和掛墻時間如下:

現在我們需要迭代列表中的塊,然后需要將它們存儲在列表中并連接起來以形成完整的數據集。
執行上述代碼的CPU時間和掛墻時間如下:

我們可以觀察到閱讀時間的大幅改善。 這樣,我們可以讀取大型數據集并減少讀取時間,有時還可以避免系統崩潰。
2.更改數據類型的大小:
如果要在對大型數據集執行任何操作時提高性能,則需要花費更多時間來避免此原因,我們可以更改某些列的數據類型的大小,例如(int64→int32),(float64→float32)以減少空間 它存儲并保存在CSV文件中,以供進一步實施。
例如,如果我們在分塊后將其應用于數據幀,并比較文件大小減少到一半之前和之后的內存使用情況,并且內存使用減少到一半,這最終導致CPU時間減少
數據類型轉換前后的內存使用情況如下:
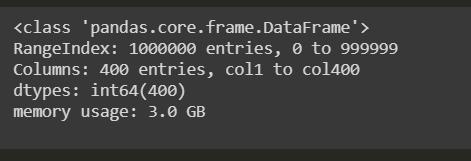
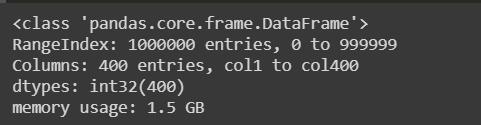
在這里,我們可以清楚地觀察到3 GB是數據類型轉換之前的內存使用量,而1.5 GB是數據類型轉換之后的內存使用量。 如果我們通過計算數據幀前后的平均值來計算性能,那么CPU時間將減少,我們的目標就可以實現。
3.從數據框中刪除不需要的列:
我們可以從數據集中刪除不需要的列,以便減少加載的數據幀的內存使用量,這可以提高我們在數據集中執行不同操作時的CPU性能。
4.更改數據格式:
您的數據是否以CSV文件之類的原始ASCII文本存儲?
也許您可以通過使用另一種數據格式來加快數據加載速度并使用更少的內存。 一個很好的例子是二進制格式,例如GRIB,NetCDF或HDF。 您可以使用許多命令行工具將一種數據格式轉換為另一種格式,而無需將整個數據集都加載到內存中。 使用另一種格式可以使您以更緊湊的形式存儲數據,以節省內存,例如2字節整數或4字節浮點數。
5.使用正確的數據類型減少對象大小:
通常,可以通過將數據幀轉換為正確的數據類型來減少數據幀的內存使用量。 幾乎所有數據集都包含對象數據類型,該對象數據類型通常為字符串格式,這對內存效率不高。 當您考慮日期,類別特征(如區域,城市,地名)時,它們會占用更多的內存,因此,如果將它們轉換為相應的數據類型(如DateTime),則類別將使內存使用量比以前減少10倍以上 。
6.使用像Vaex這樣的快速加載庫:
Vaex是一個高性能Python庫,用于懶惰的Out-of-Core DataFrame(類似于Pandas),以可視化方式瀏覽大型表格數據集。 它以每秒超過十億(10 ^ 9)個樣本/行的速度在N維網格上計算統計信息,例如平均值,總和,計數,標準差等。 可視化使用直方圖,密度圖和3d體積渲染完成,從而允許交互式探索大數據。 Vaex使用內存映射,零內存復制策略和惰性計算來獲得優質性能(不浪費內存)。
現在,讓我們在上面隨機生成的數據集中實現vaex庫,以觀察性能。
1.首先,我們需要根據您使用的操作系統,使用命令提示符/ shell安裝vaex庫。
2.然后,我們需要使用vaex庫將CSV文件轉換為hdf5文件。
執行上述代碼后,將在您的工作目錄中生成一個dataset.csv.hdf5文件。 數據類型轉換前后的內存使用情況如下:

可以看出,將CSV轉換為hdf5文件花費了將近39秒,相對于文件大小而言,時間要短一些。
3.使用vaex讀取hdf5文件:-
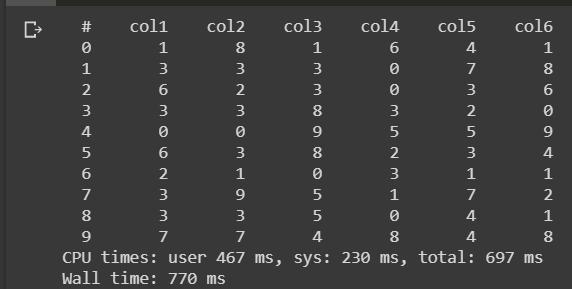
現在我們需要通過vaex庫中的open函數打開hdf5文件。
觀察完上面的代碼后,如果我們看到輸出,則看似花了697毫秒來讀取hdf5文件,由此我們可以了解讀取3GB hdf5文件的執行速度。 這是vaex庫的實際優勢。
通過使用vaex,我們可以對大型數據幀執行不同的操作,例如
- 表達系統
- 超出核心數據幀
- 快速分組/聚合
- 快速高效的加入
如果您想探索有關vaex庫的更多信息,請點擊此處。
結論:
通過這種方式,我們可以在機器學習中處理大型數據集時遵循這些技術。
如果您喜歡這篇文章,請閱讀這篇文章。如果您想在linkedin上與我聯系,請點擊下面的鏈接。