利用CPU緩存實(shí)現(xiàn)高性能程序
我們選購(gòu)電腦時(shí),CPU處理器的配置會(huì)有緩存大小,它是CPU性能的重要指標(biāo)。
為什么呢?因?yàn)镃PU計(jì)算速度與訪問(wèn)主存速度非常不匹配!
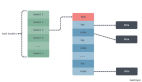
先來(lái)看計(jì)算速度。單顆CPU計(jì)算速度目前在2GHz-4GHz之間,以2.5GHz計(jì)即每秒鐘計(jì)算25億次,每個(gè)時(shí)鐘周期耗時(shí)1/2.5GHz==0.4納秒。當(dāng)前所有的計(jì)算機(jī)都遵循馮諾依曼結(jié)構(gòu),所以執(zhí)行任何指令(例如加法操作)的流程必然遵循下圖:
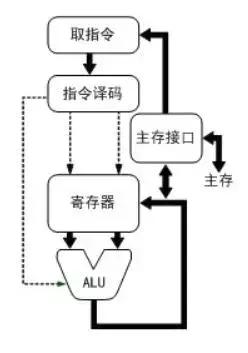
所以,做一次加法的指令是由多個(gè)時(shí)鐘周期組成的(如取指令和數(shù)字、放入寄存器、執(zhí)行ALU、將結(jié)果寫回主存),做ALU執(zhí)行指令僅需要1個(gè)時(shí)鐘周期,而取指令或者取數(shù)據(jù)、回寫結(jié)果數(shù)據(jù)就需要與主存打交道了。CPU訪問(wèn)內(nèi)存(主存)的速度非常慢,訪問(wèn)一次常常需要上百納秒以上,這與計(jì)算指令有千倍的差距!怎樣解決訪問(wèn)主存慢導(dǎo)致的CPU計(jì)算能力的浪費(fèi)呢?加入CPU緩存!
CPU上增加緩存后,由于CPU緩存離CPU核心更近,所以訪問(wèn)速度比主存快得多!如果我們?cè)L問(wèn)內(nèi)存時(shí),先把數(shù)據(jù)讀取到CPU緩存再計(jì)算,而下次讀取到該數(shù)據(jù)時(shí)直接使用緩存(若未被淘汰掉),這在時(shí)間和空間上都會(huì)降低CPU計(jì)算能力的浪費(fèi)!在時(shí)間上,有些數(shù)據(jù)訪問(wèn)頻率高(熱點(diǎn)),多次訪問(wèn)之間都未被淘汰出緩存;在空間上,緩存可以同時(shí)加載相鄰的數(shù)據(jù)、代碼,這樣函數(shù)、循環(huán)的執(zhí)行都在使用緩存中的數(shù)據(jù)。
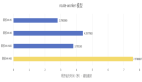
CPU緩存是分為多級(jí)的,原因是熱點(diǎn)數(shù)據(jù)太大了!最快的緩存一定離CPU核心最近,因?yàn)轶w積小所以容量也最小,不能滿足以MB計(jì)算的熱點(diǎn)數(shù)據(jù)。最終發(fā)展出了三級(jí)緩存,分別稱為L(zhǎng)1、L2、L3級(jí)緩存。這三級(jí)緩存的訪問(wèn)速度各不相同,但都遠(yuǎn)大于訪問(wèn)主存的速度(訪問(wèn)時(shí)間更小),如下圖所示:
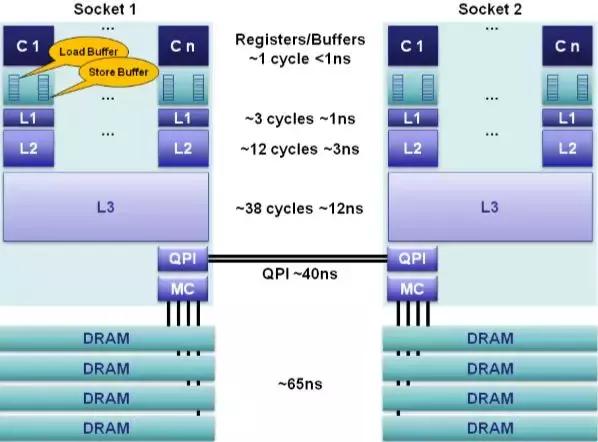
可見(jiàn),L1和L2的緩存訪問(wèn)速度非常快,只有不到3ns,L3稍慢一些,但都遠(yuǎn)小于訪問(wèn)主存的速度。當(dāng)然,CPU緩存的大小也遠(yuǎn)小于主存的大小,如本文最開(kāi)始的那張圖,現(xiàn)在的CPU緩存往往只有幾十MB。如果大家點(diǎn)擊具體的CPU細(xì)看緩存,可以看到intel只標(biāo)明了smart cache,如下圖所示(intel e5-2620 v4):
這個(gè)smart cache其實(shí)就是L3緩存,現(xiàn)在的CPU都是多核心的,而smart cache就是智能的被多CPU核心共用的意思。那么L1、L2緩存大小為什么不標(biāo)出來(lái)呢?其實(shí)沒(méi)有必要,因?yàn)橥ǔ1就是32KB,而L2是256KB,在linux上我們可以直接看到:
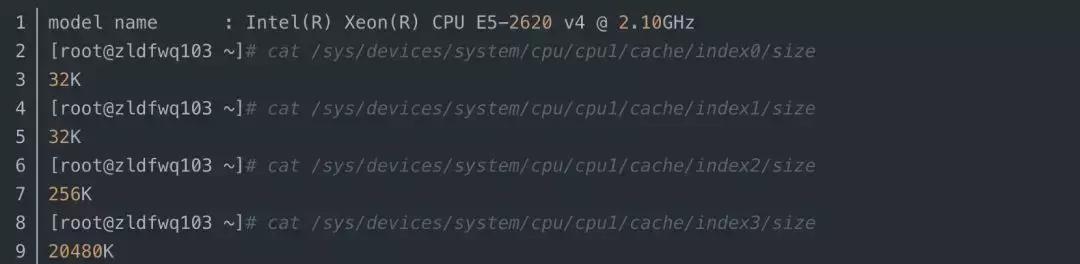
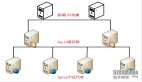
這里,index0和index1分別代表L1緩存中的指令緩存和數(shù)據(jù)緩存,index2是L2緩存,index3就是L3緩存。也可能一個(gè)緩存由多個(gè)CPU共享,仍然以E5-2620 v4這個(gè)8核16線程的CPU為例:

筆者的服務(wù)器有兩顆e5,所以表現(xiàn)為32顆邏輯CPU。由于intel的超線程技術(shù),所以兩顆邏輯CPU對(duì)應(yīng)一顆物理CPU。簡(jiǎn)單插一下何謂超線程技術(shù):由于訪問(wèn)主存的速度太慢,所以intel想了一個(gè)主意,就是當(dāng)CPU在等待從主存中調(diào)入數(shù)據(jù)或者指令時(shí),同時(shí)做另一個(gè)任務(wù),這樣一顆CPU就表現(xiàn)為兩顆邏輯CPU,如下圖所示:
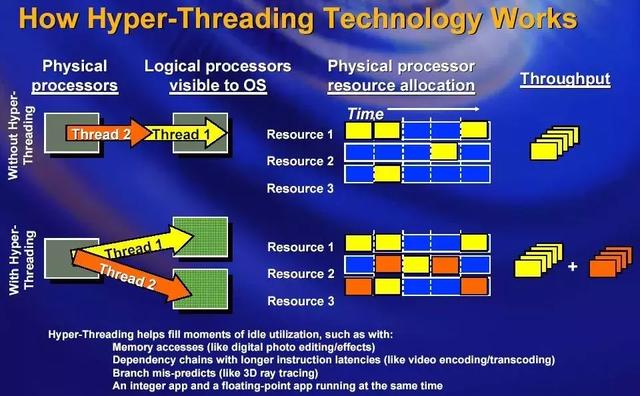
從shared_cpu_list可見(jiàn),20MB的L3緩存被16顆邏輯CPU(8顆物理CPU)共享,而L2和L1都是由一顆物理CPU獨(dú)占的。
CPU緩存與主存交換數(shù)據(jù)每次大小是固定的,我們稱其為cpu cache line,在64位系統(tǒng)下通常是64字節(jié),在linux下可以這么獲取該值:
在C語(yǔ)言程序里,可以通過(guò)sysconf (_SC_LEVEL1_DCACHE_LINESIZE)獲取,例如在nginx 1.13.8版本后是這么獲取的:

為什么需要cpu cache line這個(gè)數(shù)值呢?因?yàn)樗鼘?duì)提高性能是有用的!比如nginx中存儲(chǔ)http header的hash表。假設(shè)我們的cache size是64字節(jié),而一個(gè)hash bucket是48字節(jié)。假如某一個(gè)bucket的起始地址是1F7D030,那么它占用的內(nèi)存就從1F7D030到1F7D05F,而cache size的特性導(dǎo)致只會(huì)從64的整數(shù)倍地址訪問(wèn),于是需要訪問(wèn)兩次:1F7D000和1F7D040。而如果我們能使得hash bucket大小是cache size的整數(shù)倍,那么就不會(huì)出現(xiàn)訪問(wèn)一個(gè)hash bucket需要兩次操作主存的情況。比如,若原本bucket size是32,則設(shè)為64;原本為96,則設(shè)為128,即向上對(duì)齊。nginx有一個(gè)向上對(duì)齊函數(shù)就是做這個(gè)事的:

上面這個(gè)ngx_align算法來(lái)源于一個(gè)數(shù)學(xué)特性:對(duì)于正整數(shù)2^n(n>1)來(lái)說(shuō),存在這樣的特性,如果整數(shù)X是2^n的整數(shù)倍,則X的二進(jìn)制形式的低n位為0, 如果X不是2^n的整數(shù)倍,則X與(~(2^n-1))進(jìn)行與運(yùn)算可以得到一個(gè)與X相近的是2^n整數(shù)倍的正整數(shù)。對(duì)于上對(duì)齊,則需要先加上2^n-1,再進(jìn)行上述運(yùn)算。
事實(shí)上,如果hash bucket沒(méi)有對(duì)齊cache line,那么出現(xiàn)訪問(wèn)一個(gè)bucket要調(diào)用兩次載入主存數(shù)據(jù)的操作可能性非常大!比如上面的例子中hash bucket size是48,即使***個(gè)bucket沒(méi)有跨cache line,第2個(gè)bucket一定會(huì)跨從而導(dǎo)致兩次主存訪問(wèn)!
當(dāng)CPU獲取數(shù)據(jù)時(shí),cpu緩存由于已經(jīng)存有數(shù)據(jù),那么核心可以直接使用緩存,不用再去訪問(wèn)內(nèi)存了,這一過(guò)程我們稱為cache hit***!反之,稱為cache miss。可見(jiàn),如果我們的程序在循環(huán)或者熱點(diǎn)代碼中,能夠控制數(shù)據(jù)規(guī)模,使之長(zhǎng)期落在CPU緩存中,那么性能就可以提升!怎么判斷CPU緩存***率現(xiàn)在是多少呢?在linux下可以通過(guò)perf命令輕松實(shí)現(xiàn)(centos下通過(guò)yum install perf安裝),如下所示:
當(dāng)然,perf支持很多事件,包括進(jìn)程上下文切換等,上面的cache-references,cache-misses兩個(gè)事件分別代表緩存***和未***。perf支持的事件很多,如下表所示:
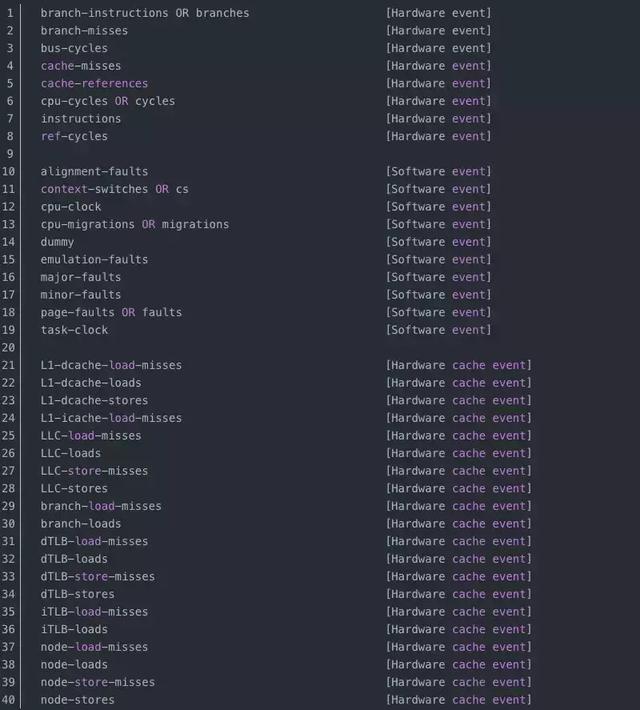
使用perf來(lái)定位程序性能的瓶頸是個(gè)有效的辦法!