Golang 高性能無 GC 的緩存庫 bigcache 是怎么實現(xiàn)的?
我們寫代碼的時候,經(jīng)常會需要從數(shù)據(jù)庫里讀取一些數(shù)據(jù),比如配置信息或者諸如每周熱點商品之類的數(shù)據(jù)。

應(yīng)用讀取數(shù)據(jù)庫
如果這些數(shù)據(jù)既不經(jīng)常變化,又需要頻繁讀取,那比起每次都去讀數(shù)據(jù)庫,更優(yōu)的解決方案就是將它們放到應(yīng)用的本地內(nèi)存里,這樣可以省下不少數(shù)據(jù)庫 IO,性能嘎一下就上來了。
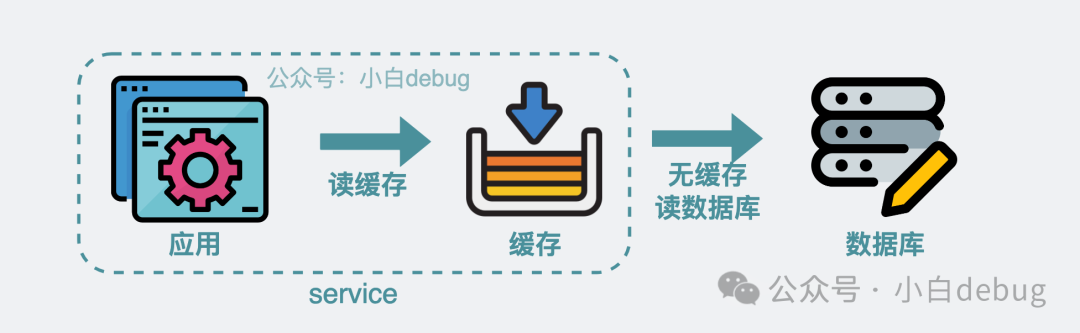
應(yīng)用優(yōu)先讀緩存
那么現(xiàn)在問題就來了,假設(shè)我要在某個服務(wù)應(yīng)用里實現(xiàn)一個緩存組件去存各種類型的數(shù)據(jù),該怎么實現(xiàn)這個組件呢?
從一個 map 說起
最簡單的的方案就是使用 map,也就是字典,將需要保存的結(jié)構(gòu)以 key-value 的形式,保存到內(nèi)存中。比如系統(tǒng)配置,key 就叫 system_config,value 就是具體的配置內(nèi)容。需要讀取數(shù)據(jù)就用 v = m[key]來獲取數(shù)據(jù),需要寫數(shù)據(jù)就執(zhí)行m[key] = v.
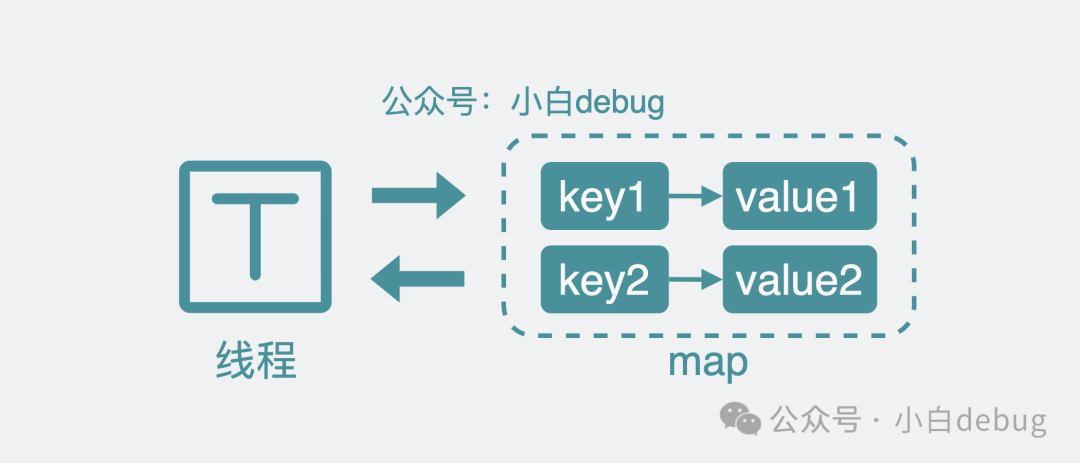
單線程讀寫map
這樣看起來在單線程下是滿足需求了。但如果我想在多個線程(協(xié)程)里并發(fā)讀寫這個緩存呢?那必然會發(fā)生競態(tài)問題。這就需要加個讀寫鎖了。讀操作前后要加鎖和解鎖,也就是改成下面這樣。
RLock()
v = m[key]
RUnLock()寫操作也需要相應(yīng)修改:
Lock()
m[key] = v
UnLock()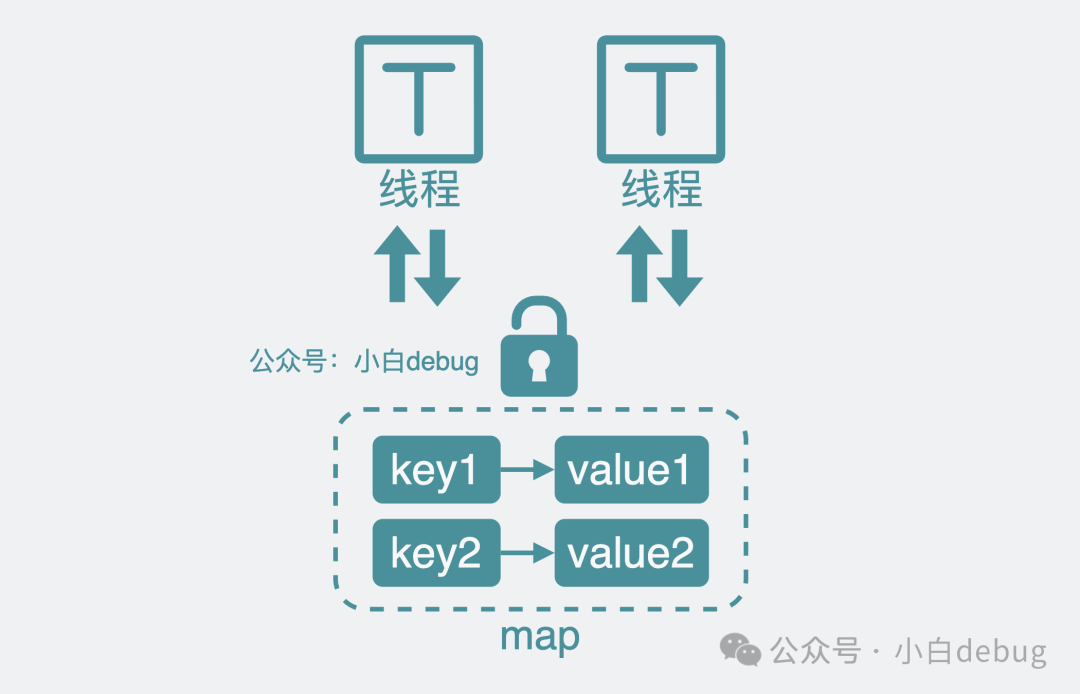
多線程加鎖讀寫map
這在讀寫不頻繁的場景下是完全 ok 的,如果沒有什么性能要求,服務(wù)也沒出現(xiàn)什么瓶頸,就算新來的實習(xí)生笑它很 low,你也要有自信,這就是個好用的緩存組件。架構(gòu)就是這樣,能快速滿足需求,不出錯就行。
但其實這個方案其實也有很大的問題,如果讀寫 qps 非常高,那么就會有一堆請求爭搶同一個 map 鎖,這對性能影響太大了。怎么解決呢?
將鎖粒度變小
上面的方案中,最大的問題是所有讀寫請求,都搶的同一個鎖,所以競爭才大,如果能將一部分請求改為搶 A 鎖,另一部分請求改為搶 B 鎖,那競爭就變小了。于是,我們可以將原來的一個 map,進行分片,變成多個 map,每個 map 都有自己的鎖。發(fā)生讀寫操作時,第一步先對 key 進行 hash 分片,獲取分片對應(yīng)的鎖后,再對分片 map 進行讀寫。只有落在同一個分片的請求才會發(fā)生鎖爭搶。也就是說 map 拆的越細,鎖競爭就越小。
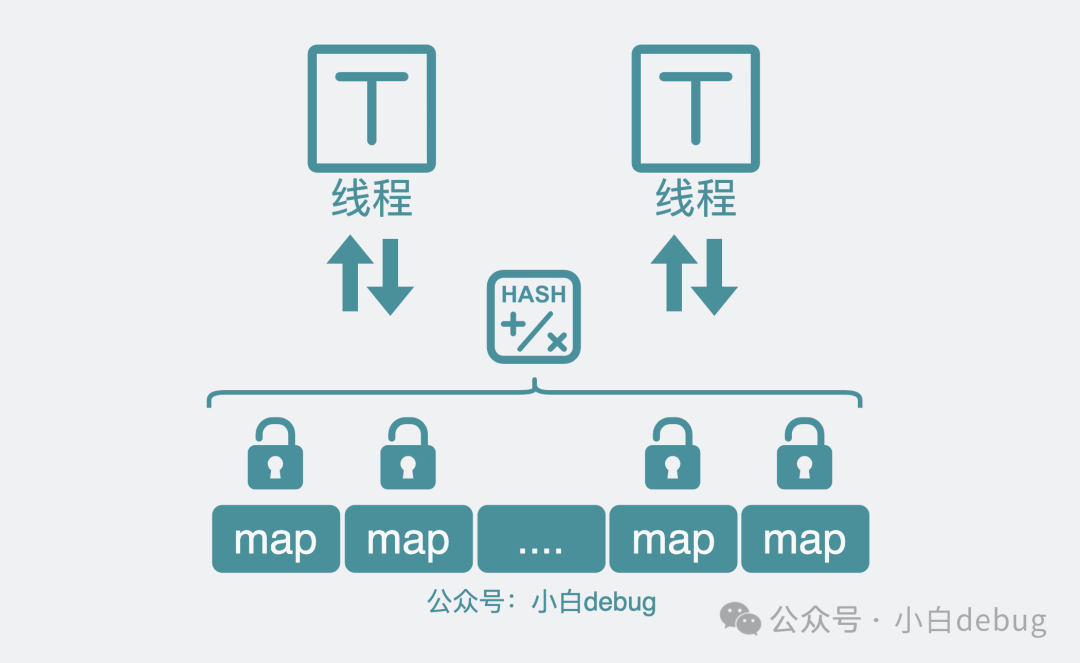
分片鎖
像這種將資源分割成多個獨立的分片(segments/shard),每個段都有一個對應(yīng)的鎖來控制并發(fā)訪問的控制機制, 其實就是所謂的分片(段)鎖。看起來很完美,但其實還有問題。
gc 帶來的問題
像 C/C++這類語言中,用戶申請的內(nèi)存需要由用戶自己寫代碼去釋放,一不小心忘了釋放那就會發(fā)生內(nèi)存泄露,給程序員帶來了很大的心智負擔(dān)。為了避免這樣的問題,一般高級語言里都會自帶 GC,也就是垃圾回收(Garbage Collection),說白了就是程序員只管申請內(nèi)存,用完了系統(tǒng)會自動回收釋放這些內(nèi)存。比如 golang,它會每隔一段時間就去掃描哪些變量內(nèi)存是可以被回收的。對于指針類型,golang 會先掃指針,再掃描指針指向的對象里的內(nèi)容。map緩存里放的東西少還好說,緩存里的 key-value 一多,那就喜提多遍瘋狂掃描,浪費,全是浪費,golang 你糊涂啊。
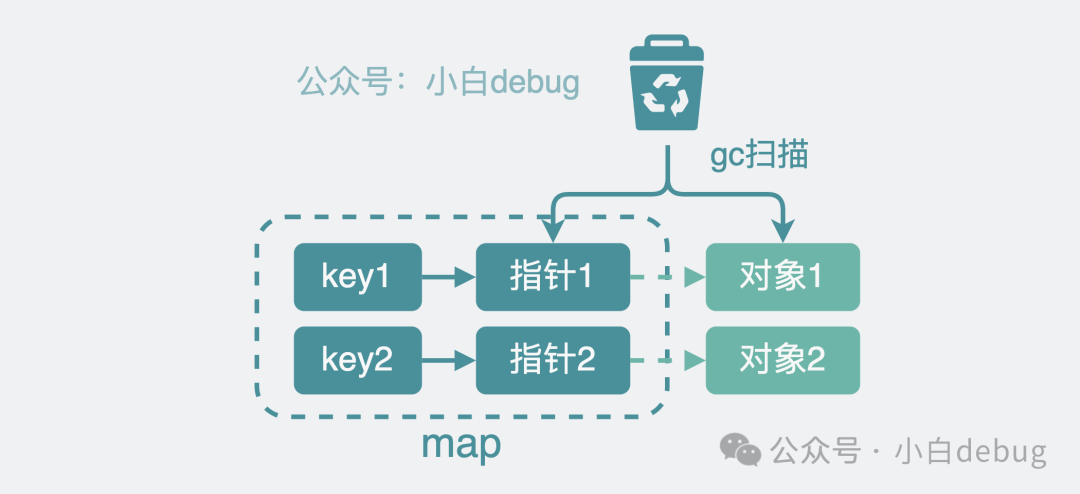
gc掃描指針對象
那有沒有辦法可以減少這部分 gc 掃描 成本呢?有。golang 對于key 和 value 都不含指針的的map,會選擇跳過,不進行 gc 掃描。所以我們需要想辦法將 map 里的內(nèi)容改成完全不含指針。原來 map 中放的 key-value,key和value 都可能是指針結(jié)構(gòu)體。
1.對于 key
原來 key 是用的字符串,在 golang 中字符串本質(zhì)上也是指針,于是我們將它進行 hash 操作,將字符串轉(zhuǎn)為整形。信息經(jīng)過 hash 操作后,有可能會丟掉部分信息,為了避免hash沖突時分不清具體是哪個 key-value,我們會將 key 放到 value 中一起處理,繼續(xù)看下面。
2.對于 value
我們可以構(gòu)造一個超大的 byte 數(shù)組 buf,將原來的 key value 等信息經(jīng)過序列化,變成二進制01串。將它存放到這個超大 buf 中,并記錄它在 超大 buf 中的位置 index。然后將這個位置 index 信息放到 map 的 value 位置上,也就是從 key-velue,變成了 key-index。
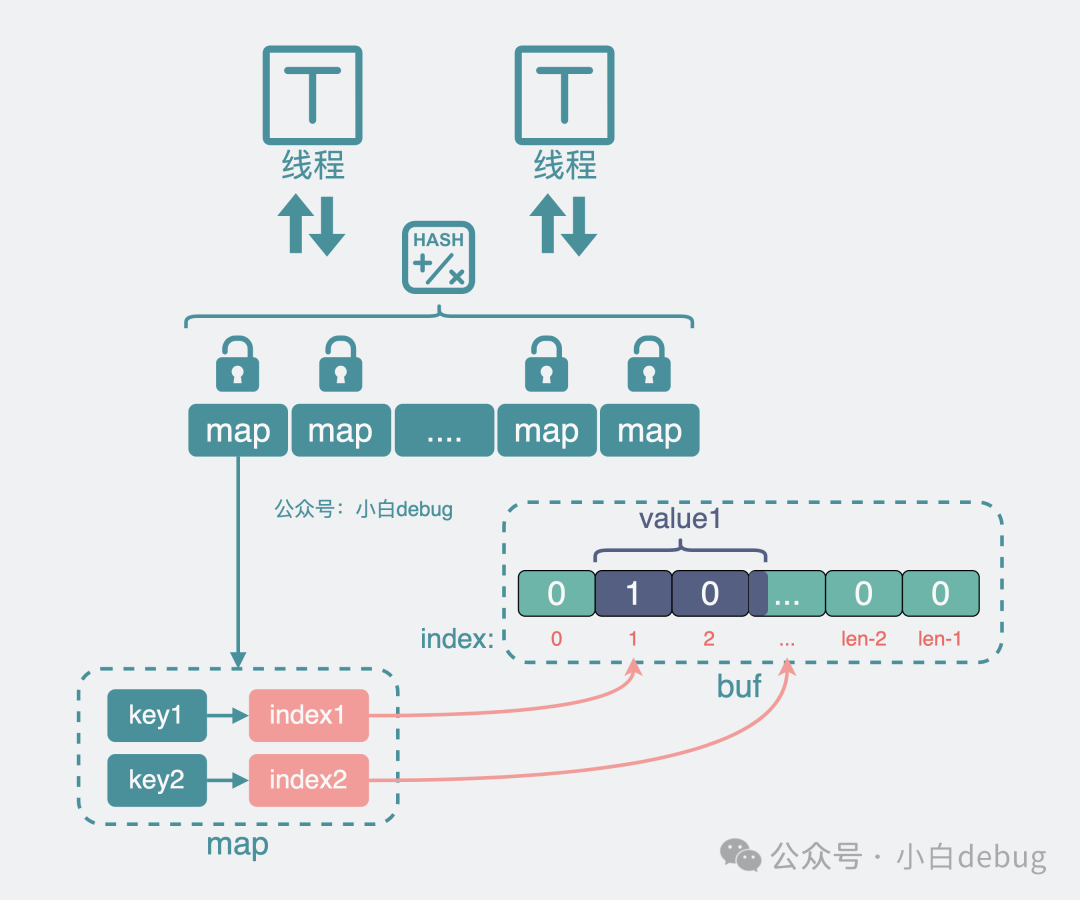
引入buf減少gc掃描
同時為了防止 buf 數(shù)組變得過大,占用過多內(nèi)存導(dǎo)致應(yīng)用oom,還可以采用 ringbuf 的結(jié)構(gòu),寫到尾部就重頭開始寫,如果 ringbuf 空間不夠,還能對它進行擴容。
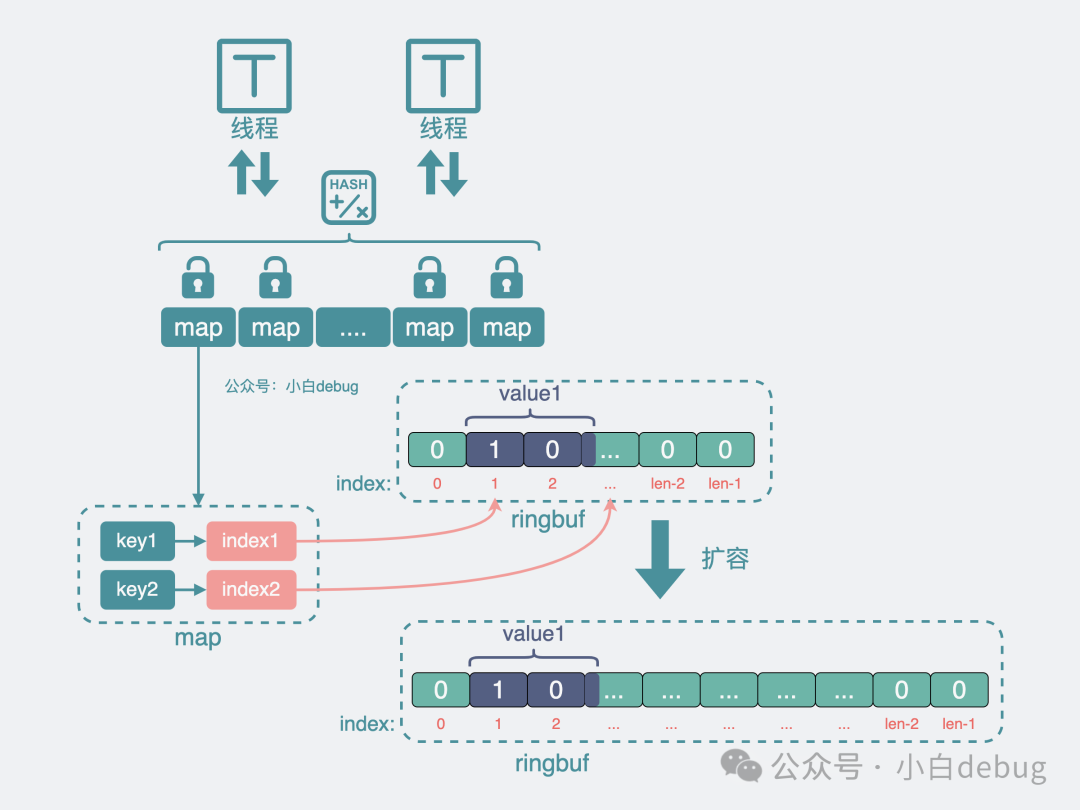
ringbuf擴容
3.寫操作
對于寫操作,程序先將 key 進行 hash,得到所在分片 map,加鎖。
- 如果不能從分片 map 里拿到 index,也就是 map 中沒舊數(shù)據(jù),那就找到 ringbuf 里的空位置后寫入 value,再將index寫入map。
- 如果能從分片 map 里拿到 index,也就是 map 中有舊數(shù)據(jù),那就覆蓋寫 ringbuf。
然后解鎖,結(jié)束流程。
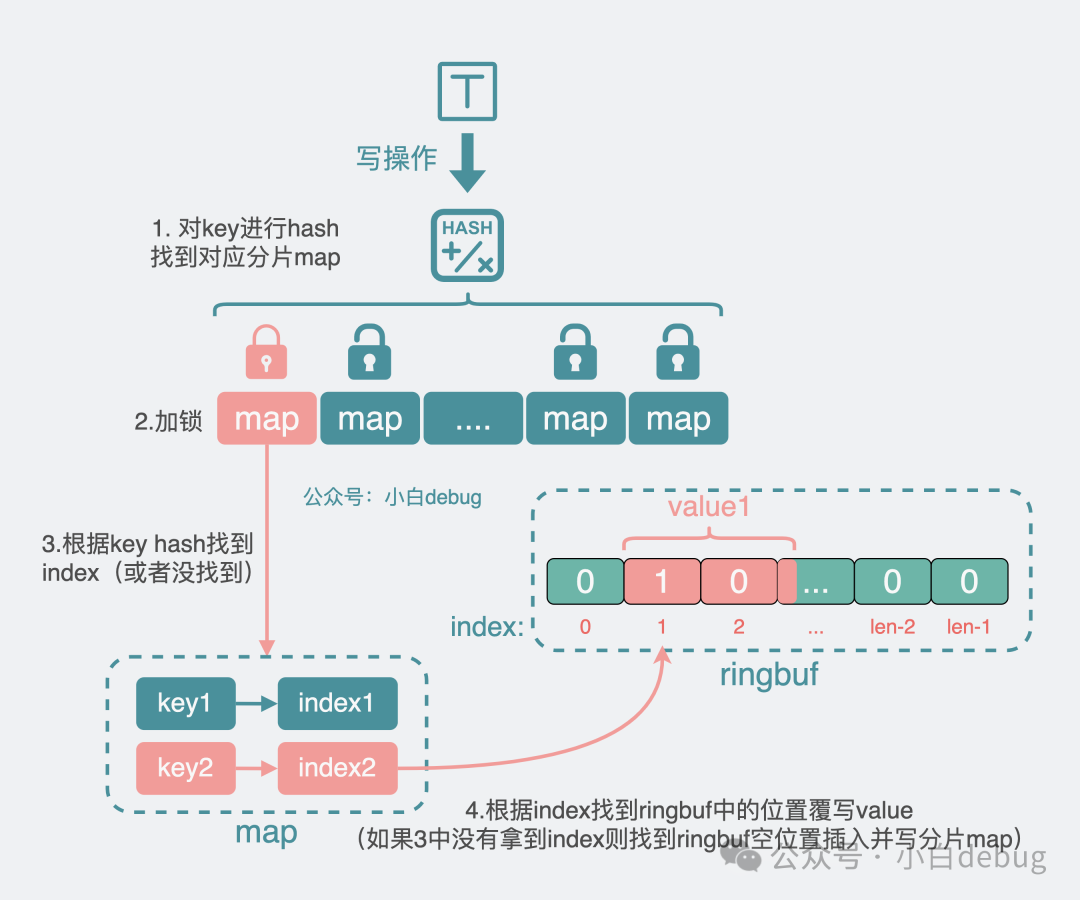
寫分片map流程
4.讀操作
對于讀操作,程序同樣先對 key 進行 hash,得到分片 map。加鎖,從分片 map 里拿到 value 對應(yīng)的 index,拿著這個 index 到 ringbuf 數(shù)組中去獲取到 value 的值,然后解鎖,結(jié)束流程。
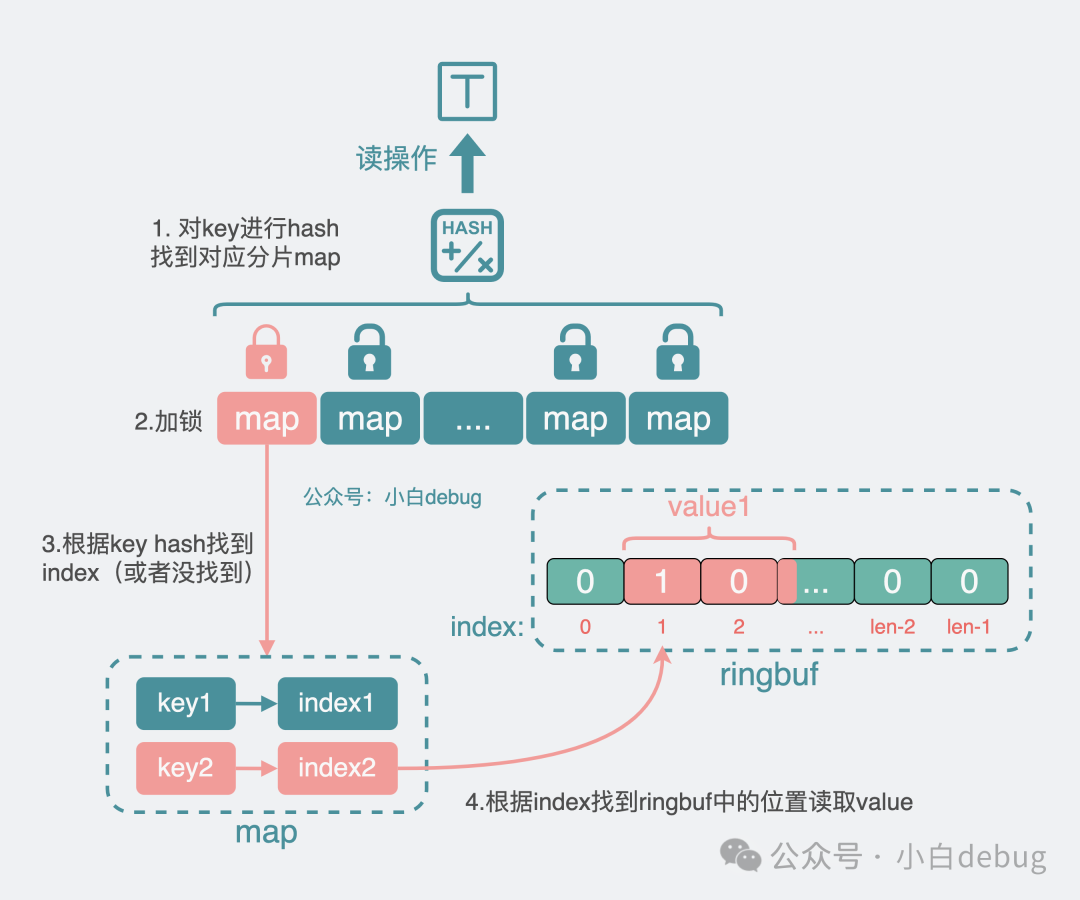
讀分片map流程
到這里,我們可以發(fā)現(xiàn) map 的 key 和 value 都被改成了整形數(shù)字,也就省下了大量的 gc 掃描,大大提升了組件性能。其實這就是有名的高性能無 GC 的緩存庫 github.com/allegro/bigcache 的實現(xiàn)原理。
bigcache 的使用
它的使用方法大概像下面這樣。
package main
import (
"fmt"
"github.com/allegro/bigcache/v3"
)
func main() {
// 設(shè)置 bigcache 配置參數(shù)
cacheConfig := bigcache.Config{
Shards: 1024, // 分片數(shù)量,提高并發(fā)性
}
// 初始化 bigcache
cache, _ := bigcache.NewBigCache(cacheConfig)
// 寫緩存數(shù)據(jù)
key := "歡迎關(guān)注"
value := []byte("小白debug")
cache.Set(key, value)
// 讀緩存數(shù)據(jù)
entry, _ := cache.Get(key)
fmt.Printf("Entry: %s\n", entry)
}說白了就是 Get 方法讀緩存數(shù)據(jù),Set 方法寫緩存數(shù)據(jù),比較簡單。現(xiàn)在,大概原理和使用方法我們都懂了,我們再來看下 bigcache 中,兩個我認為挺巧妙的設(shè)計點。
ringbuf 中的數(shù)據(jù)格式
在前面的介紹中,我猜你心里可能有疑問,程序從 ringbuf 讀寫 value 的時候,ringbuf里面放的都是 01 二進制數(shù)組,程序怎么知道該讀多少bit才算一個完整 value?bigcache 的解法非常值得學(xué)習(xí),它重新定義了一個新的數(shù)據(jù)格式。
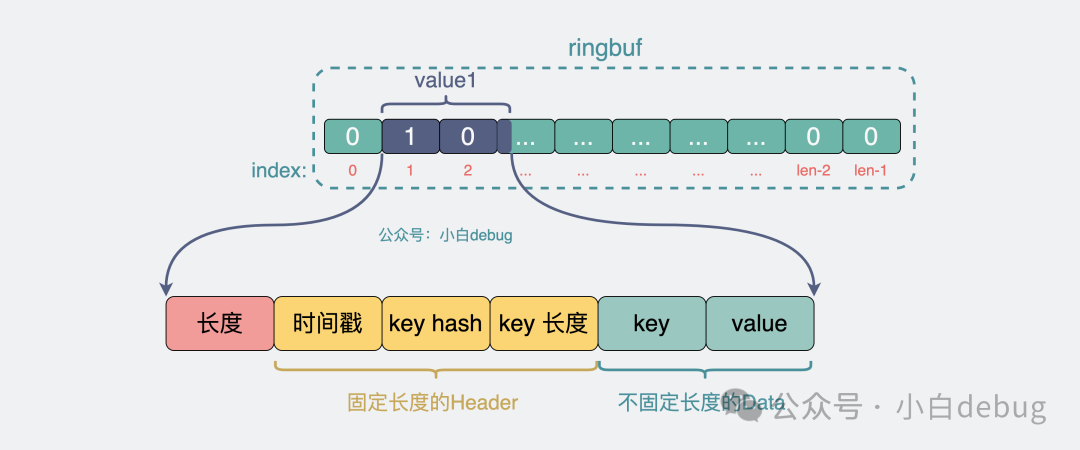
ringbuf內(nèi)數(shù)據(jù)格式
- length 表示 header 到 data 的數(shù)據(jù)長度
- header 是固定長度
- data 則是 key 和 value 的完整數(shù)據(jù)。
當(dāng)讀取 ringbuf 時,我們會先讀到 length,有了它,我們就能在 ringbuf 里拿到 header 和 data,header 里又含有 key 的長度,這樣就能在 data 里將 key 和 value 完整區(qū)分開來。
很多網(wǎng)絡(luò)傳輸框架中都會用到類似的方案,后面有機會跟大家細聊。
ringbuffer 的第 0 位
另外,還有個巧妙的設(shè)計是,在 bigcache 中, ringbuffer 的第 0 位并不用來存放任何數(shù)據(jù),這樣如果發(fā)現(xiàn) 分片 map 中得到數(shù)據(jù)的 index 為 0,就可以直接認為沒有對應(yīng)的緩存數(shù)據(jù),那就不需要跑到 ringbuffer 里去撈一遍數(shù)據(jù)了,覺得學(xué)到了,記得在右下角給我點個贊。
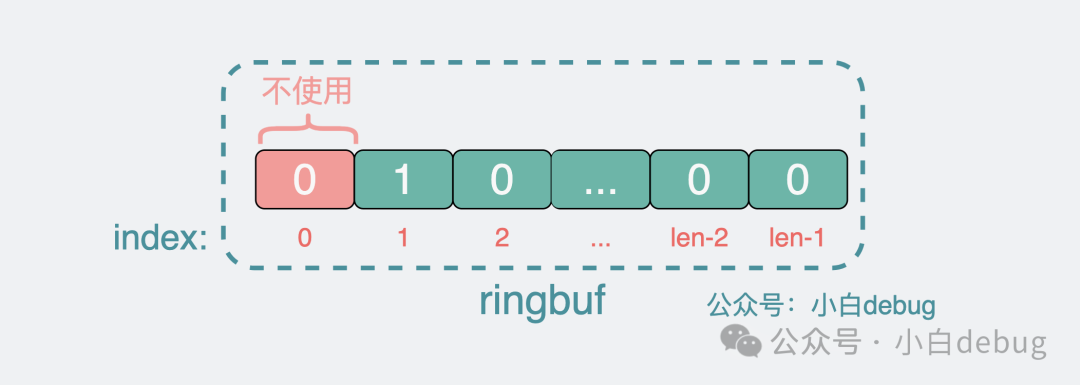
ringbuf不使用第0位
bigcache 的缺點
bigcache 性能非常好,但也不是完全沒有問題。比較明顯的是,它讀寫數(shù)據(jù)時,用的都是byte數(shù)組,但我們平時寫代碼用的都是結(jié)構(gòu)體,為了讓結(jié)構(gòu)體和 byte 數(shù)組互轉(zhuǎn),我們就需要用到序列化和反序列化,這些都是成本。
另外它的緩存淘汰策略也比較粗暴,用的是 FIFO,不支持 LRU 或 LFU 的淘汰策略。
總結(jié)
- 對于不頻繁讀寫的場景,加鎖讀寫 map 就夠了。
- 對于需要頻繁讀寫的場景,可以使用分片鎖,減少鎖競爭。
- 對于 golang,map 中含指針的話會引發(fā) gc 掃描,為了降低這部分成本,引入了 ringbuf,map 的 value 則改為緩存對象在 ringbuf 中的 index,以此提升組件性能。以后面試官問你看沒看過哪些優(yōu)秀組件的源碼的時候,你知道該怎么回答了吧?