













CanSecWest 2019 | 如何用AI“欺騙”AI?
引言:隱形T恤
在威廉?吉布森的科幻小說《零歷史》中有這么一個情節:有人發明了一件奇丑無比的T恤,其神奇之處在于,這是一件能在監控攝像下“隱身”的衣服——只要穿上這件T恤,就能神乎其技地躲開監控,去做一些見不得光的事情……
在現實世界中,這已經不完全是科幻概念了。在目前的AI攻防研究中,這種監控攝像下的“隱形T恤”已經有了具體的表現。其出現的主要原因是AI算法設計的時候未充分考慮相關的安全威脅,使得AI算法的預測結果容易受惡意攻擊者的影響,導致AI系統判斷失誤。
可見,AI在改變人類命運的同時,也同樣存在安全風險。這樣的安全風險可以體現在醫療、交通、工業、監控、政治等眾多領域。犯罪分子通過惡意攻擊來“蒙蔽”AI,甚至可能進行擾亂政治選舉、傳播黃暴恐、蓄意謀殺等重大犯罪活動。
因此,AI安全不容忽視,特別是來自于外部攻擊導致的AI模型風險,比如對抗樣本攻擊可以誘導AI模型進行錯誤的判斷,輸出錯誤的結果。本文主要針對這一問題進行分析。
1.什么是對抗樣本?
對抗樣本(adversarial examples),最早由Szegedy等人[1]在2013年提出。它是指通過給輸入圖片加入人眼難以察覺的微小擾動,使得正常的機器學習模型輸出錯誤的預測結果。如圖1所示,輸入一張熊貓圖片,正常的深度神經網絡可以正確地將其識別為“panda (熊貓)”。但是有針對性地給它加上一層對抗干擾后,同一個深度神經網絡將其識別為“cocktail shaker (雞尾酒調酒器)”, 如圖2所示。
?? 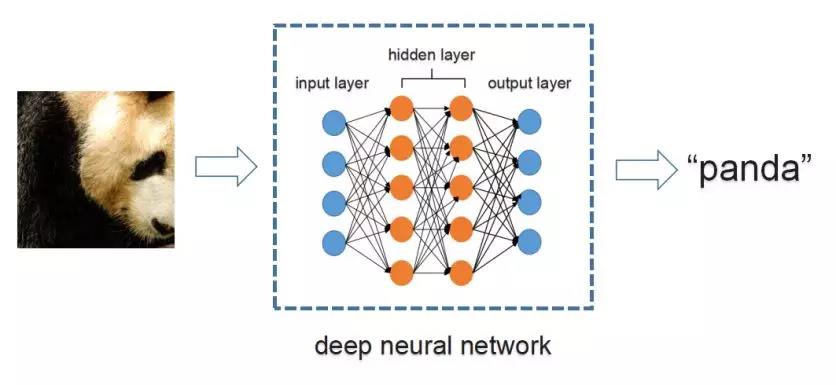
圖1. 正常圖片識別
?? 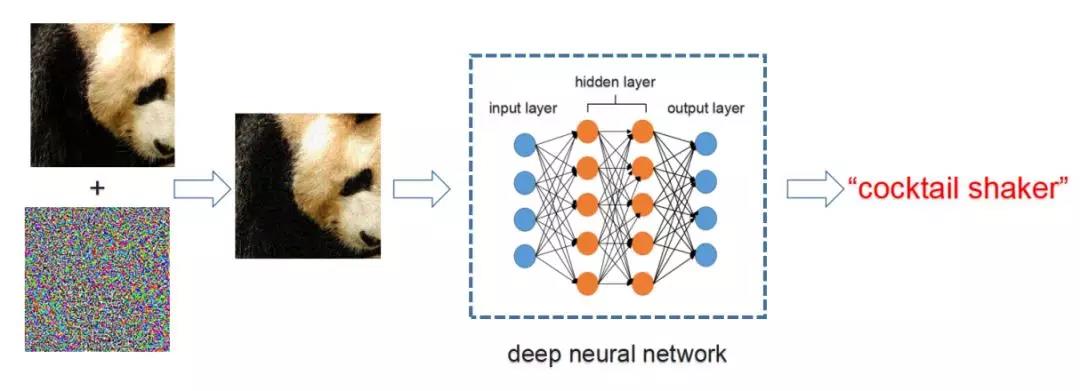
圖2. 對抗樣本攻擊
那么對抗樣本出現的原因是什么呢?主要有兩個原因導致對抗樣本的出現:
(1)首先,基于深度學習的神經網絡模型可學習的參數有限,導致神經網絡的表達能力有限,無法覆蓋所有圖像的可變空間。而且目前用于訓練神經網絡的數據集相對于整個自然場景圖像的空間來說,依然只占很小一部分空間,因此可能存在這樣一類與自然圖像中的樣本很相似的樣本,人眼無法察覺到它們的差異,但是神經網絡將其識別錯誤。
(2)其次,神經網絡中的高維線性變換導致對抗樣本[2]。例如,假設存在樣本x和網絡權重W,對樣本x加入微小的干擾η來構建對抗樣本,即
?? 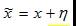
,對于線性變換
?? 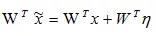
,WTη為噪聲的線性積累,當線性變換的權重W與噪聲η 的方向一致或完全相反時,導致這兩者的點積最大或最小,導致輸出超出正常范圍,最終導致神經網絡預測錯誤。
因此,對抗樣本并不是將隨機產生的噪聲疊加到正常的樣本上就可以使模型識別錯誤,而是與模型的參數W有關。對抗樣本是一種被惡意設計來攻擊機器學習算法模型的樣本。
一般來說,對抗樣本攻擊可以分為有目標攻擊(targeted attacks)和無目標攻擊(non-targeted attacks)。所謂有目標攻擊,即給定目標類別,修改輸入圖片,使神經網絡將其識別為目標類別。而無目標攻擊,只需要修改圖片使其類別發生改變即可。
對抗樣本攻擊還可以分為白盒攻擊(white-box attacks)與黑盒攻擊(black-box attacks)。其中白盒攻擊是指攻擊者能夠能夠獲知機器學習所使用的算法以及算法所使用的參數,攻擊者在生成對抗樣本的過程中可以與機器學習系統有所交互。而黑盒攻擊是指攻擊者并不知道機器學習所使用的算法模型或參數。
2.對抗樣本是怎樣生成的?
2.1 優化目標
近年來,對抗樣本的生成算法得到了快速發展,其中利用模型參數最大化模型分類損失的方法最為常用。該方法的總體分類目標可以定義為:給定模型y = f ( x, W )(其中W為模型參數,x為模型輸入,f ( x, W )為輸入到輸出的映射),對抗樣本
?? 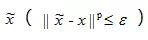
可以定義為:
?? 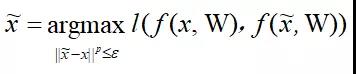
其中l (·, ·)為損失函數,刻畫原始樣本輸出和對抗樣本輸出的差異。可以使用梯度上升(gradient ascent)的方法來解決該最大化優化問題。
2.2 FGSM
Goodfellow等人[2]提出了一種名為Fast Gradient Sign Method(FGSM)的快速優化方法,定義如下:
?? 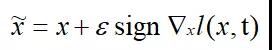
其中t為x的類別。該方法首先計算損失函數針對輸入的梯度,再取符號函數,最后加入擾動因子 ε 即可以得到對抗樣本。簡單有效,僅需一步迭代。但是這種對抗樣本生成方法的白盒攻擊成功率較低,因為在大多數情況下無法通過一步迭代有效提升損失函數。
2.3 BIM
為了解決白盒攻擊成功率較低的問題,Kurakin等人[3]提出了一種名為Basic Iterative Method(BIM)的方法, 其定義如下:
?? 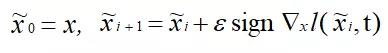
該方法通過多次迭代的方法最大限度地增大損失函數,能夠增加白盒模型的識別錯誤率。但是BIM的黑盒攻擊成功率比FGSM低,遷移性較差,因為BIM容易在白盒模型上過擬合。
2.4 我們的方法:TAP
為了解決多步迭代方法容易過擬合的問題,我們提出了一種新的對抗樣本生成方法:Transferable Adversarial Perturbations (TAP),定義如下:
?? 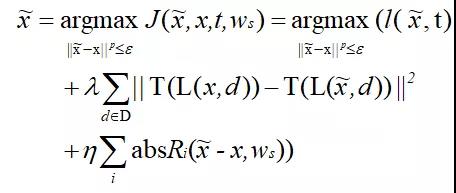
該方法主要進行了兩項優化:(1)加入特征距離來最大化原始樣本與對抗樣本高層特征之間的距離;(2)加入正則項來移除高頻噪聲,保留遷移性強的擾動。算法1闡述了使用TAP方法生成對抗樣本的詳細流程:
?? 
圖3展示了分別使用FGSM、BIM和TAP方法針對Inception V3網絡生成的對抗樣本。為了直觀地驗證對抗樣本的影響,我們對黑盒模型所提取的特征進行了可視化。細節來說,我們使用Inception V3來生成對抗樣本,然后使用Inception V4對生成的對抗樣本進行特征提取,從倒數第二層提取了1536維特征。接著,我們使用t-SNE對1536維特征進行降維,得到一個三維的特征表示,可視化效果如圖4所示。由圖4可知,我們的方法生成的對抗樣本與原始圖片之間的距離大于使用FGSM和BIM方法生成的對抗樣本與原始圖片之間的距離,證明用我們的方法在Inception V3上生成的對抗干擾將以更高的概率遷移到Inception V4的特征空間上。
?? 
(a)FGSM (b) BIM (d) TAP
圖3.對抗樣本生成示例
?? 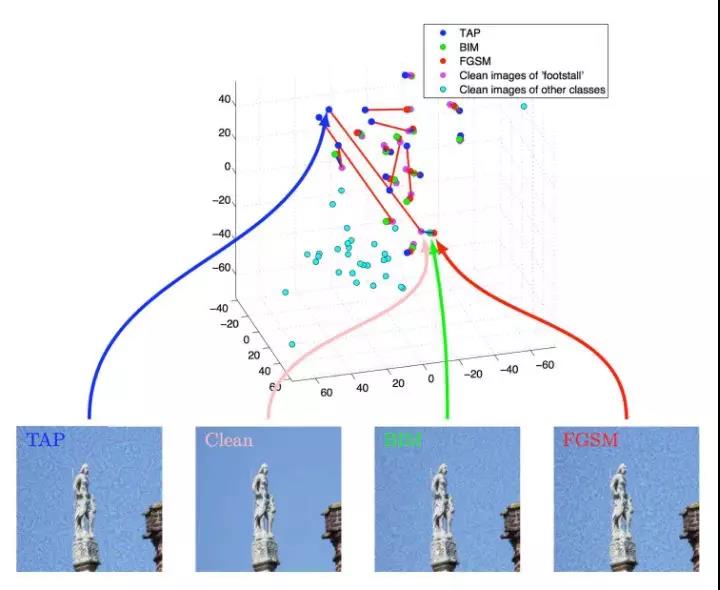
圖4. t-SNE可視化特征距離
我們關于對抗樣本生成的相關成果已經發表于ECCV 2018 [4],在此次CanSecWest會議中,我們也對這項工作進行了簡單的介紹。
3.如何使用對抗樣本來欺騙AI?
當AI被“蒙蔽”,壞人能夠做哪些事?我們使用對抗樣本對人臉識別、目標檢測、交通指示標識別、色情識別等多個應用進行了實驗。
3.1人臉識別
在人臉識別攻擊的實驗中,我們嘗試將Trump的圖片修改為Merkel,從男性更改為女性。圖5展示了我們對人臉識別網絡的攻擊過程,具體流程如下:
Step 1. 收集N張目標人物(Merkel)的人臉圖片,使用人臉檢測網絡對N張圖片進行人臉檢測和裁剪,然后送入人臉識別網絡進行特征提取,將得到N個特征表示{ f 1,f2,。。。,f N}
Step 2. 將攻擊圖片也進行人臉提取、裁剪和特征提取,將得到人臉特征f x;
Step 3. 計算loss來度量特征相似度;
Step 4. 通過梯度上升多次迭代最大化loss,生成對抗樣本;
Step 5. 將生成的人臉對抗樣本疊加到原始圖片中的人臉區域。
????
3.2 目標檢測
我們也對目標檢測網絡Faster R-CNN [7] 進行了攻擊實驗。目標檢測網絡以待檢測的圖片為輸入,輸出前景目標的坐標和類別,如人、馬、狗、汽車等。一般目標檢測網絡的損失函數包含定位和分類兩部分。在這個實驗中,我們僅考慮了分類損失,因為我們發現分類失敗能更大概率影響目標檢測的結果。圖8展示了目標檢測攻擊的結果,原本能夠精準定位和分類的前景目標的坐標和類別都發生了改變,說明針對目標分類的噪聲也可以遷移到目標定位。
?? 
(a)原始圖片
?? 
(b)對抗樣本圖
8. 目標檢測攻擊
3.3 交通指示牌識別
圖9展示了我們對交通指示牌識別網絡的攻擊樣例。目標檢測與交通指示牌識別是自動駕駛或輔助駕駛系統常用的兩種AI技術,一旦目標檢測與交通指示牌識別系統受到攻擊,后果將不堪設想(如圖10)。
?? 
圖9. 交通指示牌識別攻擊
?? 
圖10. 輔助駕駛系統
3.4 色情識別
對抗樣本同樣可以蒙騙色情識別系統。圖11顯示了使用Google Cloud [8]色情識別系統將修改后的色情圖片識別為正常圖片。
????
????
4.如何防范對抗樣本攻擊?
針對AI安全對抗樣本攻擊的防御主要分為三個階段:數據收集階段、模型訓練階段、模型使用階段。圖12列出了在各個階段的各種防御技術。
?? 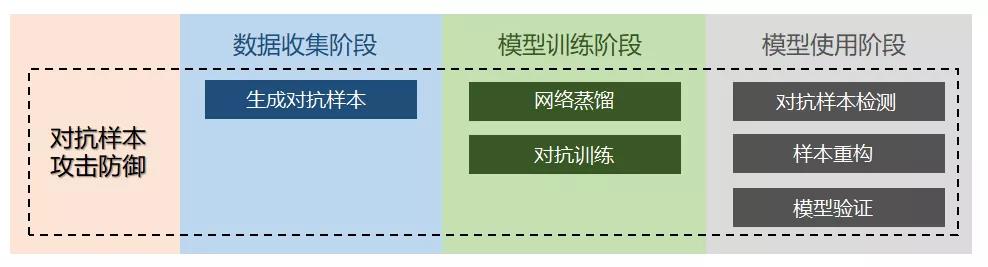
圖12. AI安全對抗樣本防御技術
生成對抗樣本(Adversarial Example Generation):該方法是指在模型訓練之前進行數據收集階段,使用各種已知的攻擊方法和網絡模型生成對抗樣本,作為數據的一部分。一般而言,生成的對抗樣本的方法和模型類型越多,樣本的變化越大,越有利于訓練生成魯棒的模型。
網絡蒸餾(Network Distillation):該方法的基本原理是指在模型訓練階段,對多個神經網絡進行串聯,其中前一個大網絡的訓練結果被作為“軟標簽”去訓練后一個小網絡。相關研究[9]發現遷移知識可以在一定程度上降低模型對微小擾動的敏感度,提高AI模型的魯棒性。
對抗訓練(Adversarial Training):該方法是指在模型訓練過程中將在數據收集階段生成的各種各樣的對抗樣本加入訓練集中,對模型進行單次或多次訓練,可以生成可以抵抗對抗干擾的對抗模型。該方法不僅可以增強新生成模型的魯棒性,還可以增強模型的準確率。
對抗樣本檢測(Adversarial Example Detection):該方法的基本原理是指在模型使用階段加入對抗樣本檢測模塊來判斷輸入的樣本是否為對抗樣本。可以是在輸入樣本到達原模型之前進行對抗樣本檢測,也可以是從原模型內部提取信息來進行判斷。例如,輸入樣本和正常數據之間的差異性可以作為判斷標準,也可以簡單地訓練一個基于神經網絡的二分類模型來進行對抗樣本檢測。
樣本重構(Example Reconstruction):樣本重構是指將對抗樣本恢復為正常樣本。通過這樣的轉換后,對抗樣本將不對網絡預測的結果產生影響。樣本重構最常用的方法是對輸入的對抗樣本進行降噪,即使用降噪網絡將對抗樣本轉換為正常樣本,或是直接在原模型網絡架構中加入降噪模塊。
模型驗證(Model Verification):模型驗證是指檢查神經網絡的屬性,驗證輸入是否違反或滿足屬性要求。該方法是防御對抗樣本攻擊很有希望的一種防御技術,因為它可以檢測未曾見過的對抗樣本攻擊。
然而,以上的防御措施都有特定的應用場景,并不能防御所有的對抗樣本攻擊,特別是一些攻擊性較強的、未曾出現過的對抗樣本攻擊。此外,也可以并行或串行整合多種防御方法,增強AI模型的防御能力。目前,大多數防御方法都是針對計算機視覺中的對抗樣本,隨著其他領域的對抗樣本的發展,比如語音,迫切需要針對這些領域的對抗樣本攻擊的防御方法。
總結
AI擴寬了人類解決問題的邊界,但是也暴露了各種各樣的安全性問題。本文剖析了AI系統極易受到對抗樣本的攻擊,并且現有的防御技術并不能完全防御這樣的攻擊。一旦AI系統被惡意攻擊,輕則造成財產損失,重則威脅人身安全。AI應用的大規模普及和發展需要很強的安全性保證,因此,我們還需要持續提升AI安全、提升AI算法的魯棒性。安平AI安全研究團隊也會在這個領域不斷深耕,助力AI事業發展。
參考文獻
Szegedy, Christian, et al. "Intriguing properties of neural networks." Computer Science (2013).
Goodfellow, Ian J., J. Shlens, and C. Szegedy. "Explaining and Harnessing Adversarial Examples." Computer Science (2015).
Kurakin, Alexey, I. Goodfellow, and S. Bengio. "Adversarial examples in the physical world." (2016).
Zhou, W., Hou, X., Chen, Y., Tang, M., Huang, X., Gan, X., & Yang, Y. (2018). Transferable Adversarial Perturbations. In Proceedings of the European Conference on Computer Vision (ECCV) (pp. 452-467).
??https://console.aws.amazon.com/rekognition/home?region=us-east-1#/celebrity-detection??
??https://azure.microsoft.com/en-us/services/cognitive-services/computer-vision/??
Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems (pp. 91-99).
??https://cloud.google.com/vision/??
Papernot, N., McDaniel, P., Wu, X., Jha, S., & Swami, A. (2016, May). Distillation as a defense to adversarial perturbations against deep neural networks. In 2016 IEEE Symposium on Security and Privacy (SP) (pp. 582-597). IEEE.
【本文為51CTO專欄作者“騰訊技術工程”原創稿件,轉載請聯系原作者(微信號:Tencent_TEG)】
??
戳這里,看該作者更多好文??




















