宜人貸——宜人蜂巢金融科技AI實踐:蜂巢機器人
一、金融科技
金融科技:就是業內所說的Fintech。維基百科對此給出的定義是,由一群通過科技,讓金融服務更高效的企業,構成的一個經濟產業。Fintech并非簡單的在'互聯網上做金融',而是基于移動互聯網、云計算和大數據等技術,實現金融服務和產品的發展創新和效率提升。簡而言之,金融科技理解為:利用包括人工智能、征信、區塊鏈、云計算、大數據、移動互聯等前沿科技手段,服務于金融效率提升的產業。宜人蜂巢在金融科技的浪潮中,不僅擁有堅實的技術基礎,構建了一站式智能風控服務體系并推出了許多風控方面的產品。
二、蜂巢機器人
宜人蜂巢團隊于2018年正式推出蜂巢機器人。蜂巢機器人是一款智能語音對話機器人產品,它是人工智能技術領域的一個重要分支。蜂巢機器人涉及了大數據技術、云計算以及人工智能技術。主要應用于智能催收與智能客戶領域,它直擊行業痛點的各項功能,幫助企業有效提高轉化率。蜂巢機器人的主要功能有:
- 全自動撥打:批量上傳案件數據,一鍵啟動群呼撥打計劃。按需設置,自動撥打號碼及重播。
- 全真人原音對話:定制化語音交互設計,各行業專業對話智能原音溝通,無感知人機對話,對話更貼近真實、順滑。
- 機器轉人工坐席:自定義意向客戶規則,通話過程中達到條件自動觸發,無感知轉人工坐席,實時推送通話聊天記錄,實現人機無縫切換。
- 支持對話打斷:智能識別用戶打斷意圖,完成用戶打斷錄音行為,高度模擬真實對話場景。
- 客戶標簽分類:完成通話及轉人工時,數據精準分析管理,客戶類型自動標記篩選,方便人工及時跟進意向客戶。
- 預測***撥打時間: 基于客戶歷史電話接通情況,由決策模型決定客戶***撥打時間,并在***撥打時間嘗試進行客戶聯系,提高客戶聯系率及滿意度,提高還款效率。
- 對話全程錄音:電話外呼全程錄音, 數據統計, 客戶標記, 查詢試聽, 音轉文字, 客戶資料***保存。
- 大數據精準用戶畫像:基于對于客戶在貸前、貸中、貸后的表現給予客戶不同金額段、不同風險等級的區分及拆分,基于客戶類型的劃分基于不同的催收方式、催收頻率、催收話術,在短信、信函、微信、催收機器人等多渠道催收方式上給予催收策略決策依據。
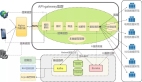
蜂巢機器人是一個全面的高效的智能語音對話機器人產品,在工程架構方面:整體框架為了高度的解耦合,運用了微服務框架;每個服務都是分布式開發部署,避免單點故障帶來的系統癱瘓;為了存儲大量的數據,系統結合運用結構化數據庫和分布式非結構化數據庫。在算法方面:語言識別、對話系統以及語音合成等模塊,運用了聲學模型、自然語言處理技術(NLP)、深度學習等人工智能技術。如下圖1為蜂巢機器人的整體框架:

圖1:蜂巢機器人整體框架
本文主要介紹的是蜂巢機器人主要在算法方面運用的技術以及方法。在整個蜂巢機器人中機器學習、深度學習等技術出現在每個環節。其實:整個蜂巢機器人的流程可分為語音識別(ASR)、語義理解(NLU)、對話管理(DM)以及語音合成(TTS)。如下圖2:

圖2:蜂巢機器人主體流程
電話通道實時把用戶的語音傳輸到ASR模塊,ASR將用戶的語音轉識別成文本,然后NLU模塊進行文本理解,識別用戶的真實意圖;有了用戶意圖,開始與用戶對話,通過多輪對話來更清晰的了解用戶意圖,此時就需要對話管理模塊的對話狀態管理和對話策略的制定;***,機器人做出***反饋,反饋為文本應答語句,語音合成把該反饋文本轉換成語音,播放給用戶,至此,機器人與用戶的多輪對話結束,同時完成具體的業務目標,了解了用戶的同時提供了正確的服務。整個環節緊密相連,承上啟下,接下來就詳細介紹:
1. 語音識別(Automatic Speech Recognition):
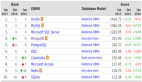
語音識別是一種廣義的自然語言處理技術。語音識別的輸入就是一段隨時間播放的信號序列,而輸出是一段文本序列。將語音實時轉換成人與機器能夠理解的文字文本,為人與機器的交互做好了***步工作,也是最重要的一步。完備的語音識別系統通常包含信息處理和特征提取、聲學模型、語言模型和解碼搜索這4個模塊,如下圖3:

圖3:語音識別系統主流程
在語音預處理階段,信號處理主要的工作是靜音片段切除、分離混疊音軌、消除噪音和信道增強;在特征提取階段主要利用MFCC特征提取方法和基于深度學習的特征表征方法來獲取語音的特征提取,形成機器能夠識別的數值類型數據。傳統的聲學模型主要是混合高斯模型(GMM)和隱馬爾科夫模型(HMM),隨著深度學習的成熟,基于深度學習的聲學模型也得到應用(例如:結合HMM模型與DNN模型的DNN-HMM混合模型、TDNN模型以及DFCNN模型),并且效果也得到提升。***一種端對端(END2END)語音識別處理系統也是研究的熱點。
2. 中文文本糾錯:
語音識別轉換的文本是后續流程處理的主要信息,然而語音識別的準確率不可能是***,這種系統級聯的不確定性會嚴重影響系統的準確性。為此,中文文本糾錯非常有必要。ASR后文本糾錯主要關注處理的是諧音字詞糾錯(配副眼睛-配副眼鏡)和混淆音字詞糾錯(流浪織女-牛郎織女)。蜂巢機器人利用人工規則、N-gram模型、拼音相似度以及同義詞搭配等方法來糾正拼音正確但識別有誤以及因背景嘈雜引起的語音識別語句主體部分的識別錯誤,而在語義關聯上的錯誤,采用雙向LSTM檢查,較好的解決了這類多義性句子的語義錯誤。
3. 自然語言理解(NLU):
NLU主要是理解ASR轉換的文本,同時結合用戶畫像等數據來挖掘用戶此時的真實意圖。此模塊三大功能是:領域識別、意圖識別和槽位提取(如圖4)。
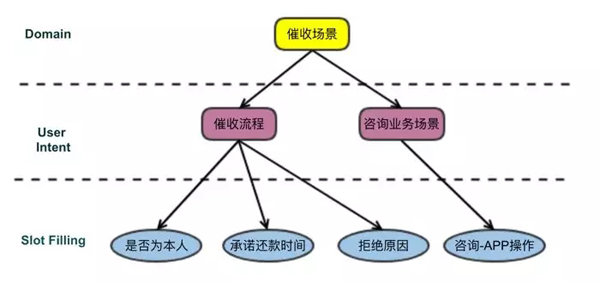
圖4:意圖識別實例
NLU是將文本歸一化計算成機器可以理解的語義表示。NLU可以使用語義解析或語義標注的方式獲得,也可以把它分解為多個分類任務來解決。蜂巢機器人在NLU部分在冷啟動階段,采用基于正則表達式的規則方法和無監督學習的語句相似度方法來實現。隨著數據的積累以及對數據標注,在用戶領域識別和意圖識別上采用了分類算法,例如:機器學習中的SVM以及深度學習領域的CNN和RNN。槽位提取其實是通過學習一系列標注序列數據來預測新標注序列,是一個序列標注問題,主要采用的方法是BLSTM+CRF。由于意圖和槽位具有較強的關聯關系,所以嘗試采用同一個網絡來完成意圖識別和槽位提取。
4. 對話管理(DM):
用戶的需求較復雜,單輪對話不能夠很好的獲取用戶的真實意圖,通過對話管理實現用戶與機器人的多輪對話,機器人就能夠通過詢問、澄清或確認來獲取更多的用戶信息,從而幫助用戶明確需求。對話管理的主要任務是維護用戶和機器人的對話狀態,并且與知識庫產生信息交互,從而選擇下一步***的動作。蜂巢機器人在早期采用了基于議程(agenda)的對話管理,利用圖數據庫存儲層次結構分明且有序的話術內容和關系,這樣整個用戶與機器人的對話實質上是對樹的遍歷,并且較容易的支持話題切換、回退和退出。隨著場景的增加,用戶的實際需求變得多樣性,其中有些質詢問題的多樣性導致基于議程的對話管理過于復雜,而且難以管理。因此,結合了基于議程的對話管理和基于槽位的對話管理,在正常業務流程中使用于議程的對話管理;而在質詢業務問題方面,采用了填槽的對話管理方式,整個對話過程就是一個不斷填槽的過程。而整個槽位信息的獲取就是NLU階段的信息輸出。在對話管理中,話術的管理利用分布式圖數據庫,同時采用圖的遍歷技術尋找下一節點以及***問題檢索的相似度重排序。
5. 語音合成(TTS):
語音合成模塊是蜂巢機器人***的一個重要模塊。語音合成就是把尋找出的***話術文本轉換成語音音頻通過電話通道播放給用戶。語音音頻主要解決發聲和語氣兩個大問題:清晰的發聲解決了用戶是否聽清機器人,而語氣主要是讓機器人更像有感情的真人。蜂巢機器人在語音合成階段利用了拼接法,根據機器人的***文本在語音庫中找去不僅在語言學特征上,還在聲學特征上也是類似的音素 。在實際的業務中,有些話術存在參數變量,這個變量隨著用戶的本身信息的不同而不同,所以通過拼接發很容易解決這個問題。語音拼接法雖然聽起來很自然,但是在前期語音的錄制和裁剪中需要花費大量人工,而且系統擴展性很差。在后期,打算利用建立基于參數的語音合成系統,它其實是一個文本抽象成語音學特征,再用統計學模型學習出來語音學特征和其聲學特征的對應關系后,再從預測出來的聲學特征還原成音頻的過程。這個技術主要是基于統計的模型完成,現階段主流深度學習模型。
三、未來展望
蜂巢機器人整個鏈路設計到了大數據、云計算、人工智能等諸多前沿技術,特別在某些領域還沒有***的解決方案。蜂巢機器人作為AI技術的實踐者,為了更好的落地,蜂巢機器人有如下的展望:
- ASR方面:更好的提升語音識別的準確性以及識別更加復雜的對話場景,需要做好降噪處理和多聲道識別。為了更貼切業務,需要加入男女聲識別、方言的識別和領域詞匯的識別等。
- 語義理解方面:嘗試更加優秀的算法,提高意圖識別和槽位信息提取的準確率。
- 對話管理方面:融合多種方式的對話管理框架,最終實現機器人端對端的學習,利用增強學習等方法使得機器人大腦更加智能。
- TTS方面:基于深度學習的語音合成系統構建能夠合成有情感的語音音頻,變得更有節奏。
【本文是51CTO專欄機構宜信技術學院的原創文章,微信公眾號“宜信技術學院( id: CE_TECH)”】