如何為您的機器學習問題選擇正確的預訓練模型
在這篇文章中,我們將簡要介紹一下遷移學習是什么,以及如何使用它。
什么是遷移學習?
遷移學習是使用預訓練模型解決深度學習問題的藝術。
遷移學習是一種機器學習技術,你可以使用一個預訓練好的神經網絡來解決一個問題,這個問題類似于網絡最初訓練用來解決的問題。例如,您可以利用構建好的用于識別狗的品種的深度學習模型來對狗和貓進行分類,而不是構建您自己的模型。這可以為您省去尋找有效的神經網絡體系結構的痛苦,可以為你節省花在訓練上的時間,并可以保證有良好的結果。也就是說,你可以花很長時間來制作一個50層的CNN來***地區分你的貓和狗,或者你可以簡單地使用許多預訓練好的圖像分類模型。
使用預訓練模型的三種不同方式
主要有三種不同的方式可以重新定位預訓練模型。他們是,
- 特征提取 。
- 復制預訓練的網絡的體系結構。
- 凍結一些層并訓練其他層。
特征提取:這里我們所需要做的就是改變輸出層,以給出cat和dog的概率(或者您的模型試圖將內容分類到的類的數量),而不是最初訓練它將內容分類到的數千個類。當我們試圖訓練模型所使用的數據與預訓練的模型最初所訓練的數據非常相似且數據集的大小很小時,這是理想的。這種機制稱為固定特征提取。我們只對添加的新輸出層進行重新訓練,并保留每一層的權重。
復制預訓練網絡的架構 :在這里,我們定義了一個與預訓練模型具有相同體系結構的機器學習模型,該模型在執行與我們試圖實現的任務類似的任務時顯示了出色的結果,并從頭開始訓練它。我們從預訓練的模型中丟棄每一層的權重,然后根據我們的數據重新訓練整個模型。當我們有大量的數據要訓練時,我們會采用這種方法,但它與訓練前的模型所訓練的數據并不十分相似。
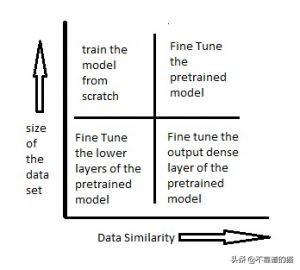
凍結一些層并訓練其他層:我們可以選擇凍結一個預訓練模型的初始k層,只訓練最頂層的n-k層。我們保持初始值的權重與預訓練模型的權重相同且不變,并對數據的高層進行再訓練。當數據集較小且數據相似度較低時,采用該方法。較低的層主要關注可以從數據中提取的最基本的信息,因此可以將其用于其他問題,因為基本級別的信息通常是相同的。
另一種常見情況是數據相似性高且數據集也很大。在這種情況下,我們保留模型的體系結構和模型的初始權重。然后,我們對整個模型進行再訓練,以更新預訓練模型的權重,以更好地適應我們的特定問題。這是使用遷移學習的理想情況。
下圖顯示了隨著數據集大小和數據相似性的變化而采用的方法。
PyTorch中的遷移學習
在torchvision.models模塊下,PyTorch中有八種不同的預訓練模型。他們是 :
- AlexNet
- VGG
- RESNET
- SqueezeNet
- DenseNet
- Inception v3
- GoogLeNet
- ShuffleNet v2
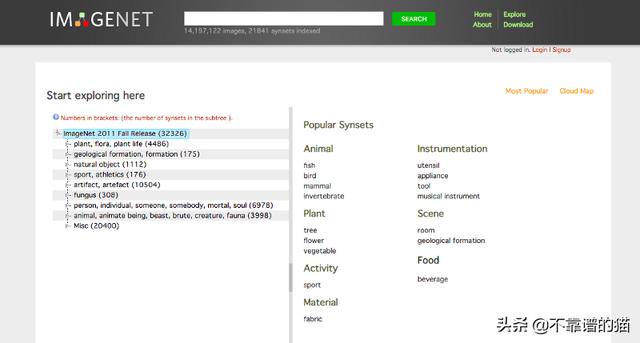
這些都是為圖像分類而構建的卷積神經網絡,在ImageNet數據集上進行訓練。ImageNet是根據WordNet層次結構組織的圖像數據庫,包含14,197,122張屬于21841類的圖像。
由于PyTorch中的所有預訓練模型都針對相同的任務在相同的數據集上進行訓練,所以我們選擇哪一個并不重要。讓我們選擇ResNet網絡,看看如何在前面討論的不同場景中使用它。
用于圖像識別的ResNet或深度殘差學習在pytorch、ResNet -18、ResNet -34、ResNet -50、ResNet -101和ResNet -152上有五個版本。
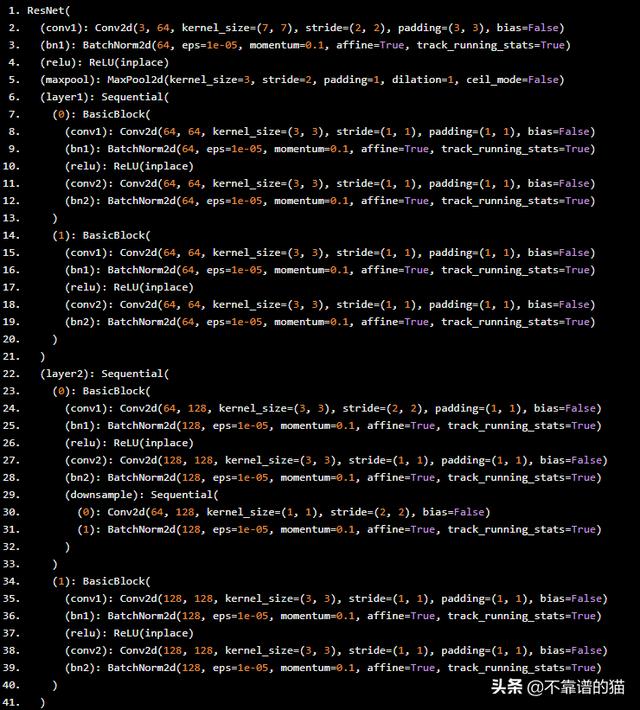
讓我們從torchvision下載ResNet-18。
- import torchvision.models as models
- model = models.resnet18(pretrained=True)

以下是我們剛剛下載的模型。
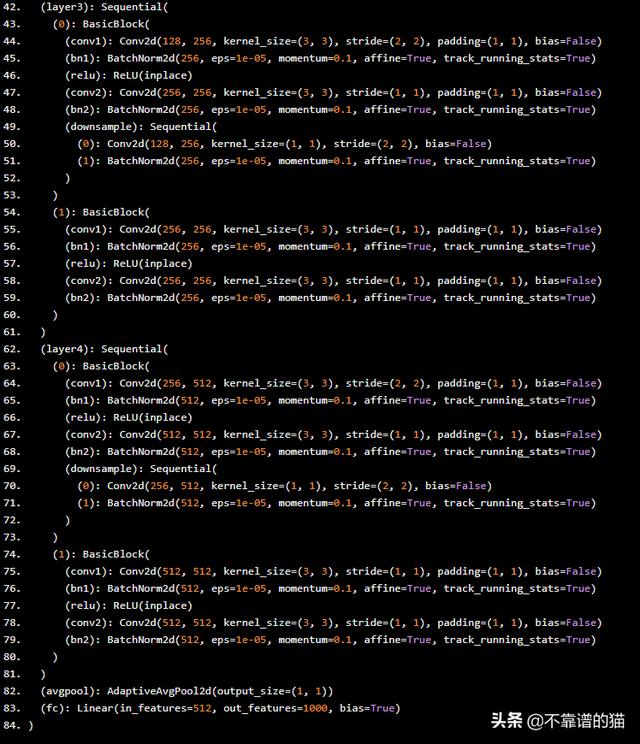
現在,讓我們看看嘗試,看看如何針對四個不同的問題訓練這個模型。
數據集很小,數據相似性很高
考慮這個kaggle數據集(https://www.kaggle.com/mriganksingh/cat-images-dataset)。這包括貓的圖像和其他非貓的圖像。它有209個像素64*64*3的訓練圖像和50個測試圖像。這顯然是一個非常小的數據集,但我們知道ResNet是在大量動物和貓圖像上訓練的,所以我們可以使用ResNet作為固定特征提取器來解決我們的貓與非貓的問題。
- num_ftrs = model.fc.in_features
- num_ftrs

Out: 512
- model.fc.out_features
Out: 1000
我們需要凍結除***一層之外的所有網絡。我們需要設置requires_grad = False來凍結參數,這樣就不會在backward()中計算梯度。新構造模塊的參數默認為requires_grad=True。
- for param in model.parameters():
- param.requires_grad = False

由于我們只需要***一層提供兩個概率,即圖像的概率是否為cat,我們可以重新定義***一層中的輸出特征數。
- model.fc = nn.Linear(num_ftrs, 2)
這是我們模型的新架構。
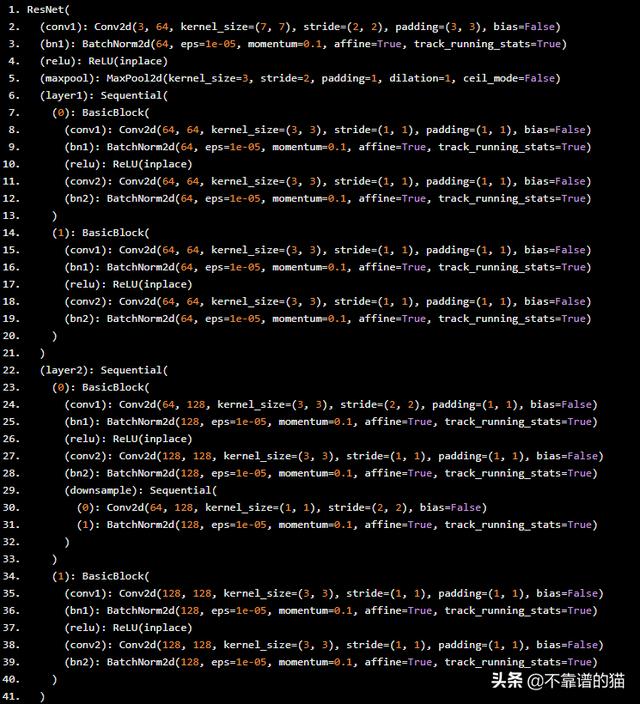
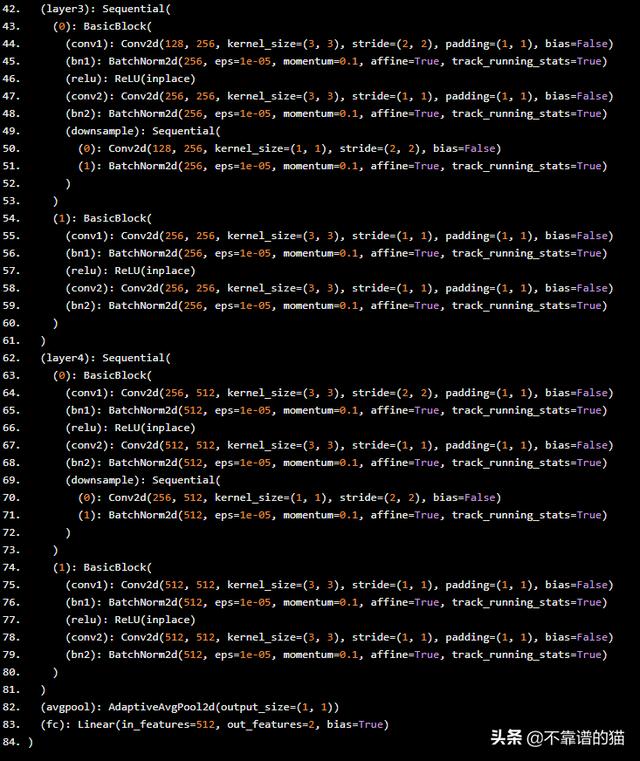
我們現在要做的就是訓練模型的***一層,我們將能夠使用我們重新定位的vgg16來預測圖像是否是貓,而且數據和訓練時間都非常少。
數據的大小很小,數據相似性也很低
考慮來自(https://www.kaggle.com/kvinicki/canine-coccidiosis),這個數據集包含了犬異孢球蟲和犬異孢球蟲卵囊的圖像和標簽,異孢球蟲卵囊是一種球蟲寄生蟲,可感染狗的腸道。它是由薩格勒布獸醫學院創建的。它包含了兩種寄生蟲的341張圖片。
這個數據集很小,而且不是Imagenet中的一個類別。在這種情況下,我們保留預先訓練好的模型架構,凍結較低的層并保留它們的權重,并訓練較低的層更新它們的權重以適應我們的問題。
- count = 0
- for child in model.children():
- count+=1
- print(count)
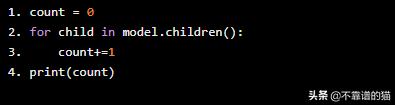
Out: 10
ResNet18共有10層。讓我們凍結前6層。
- count = 0
- for child in model.children():
- count+=1
- if count < 7:
- for param in child.parameters():
- param.requires_grad = False
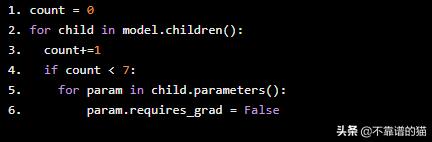
現在我們已經凍結了前6層,讓我們重新定義最終輸出層,只給出2個輸出,而不是1000。
- model.fc = nn.Linear(num_ftrs, 2)
這是更新的架構。
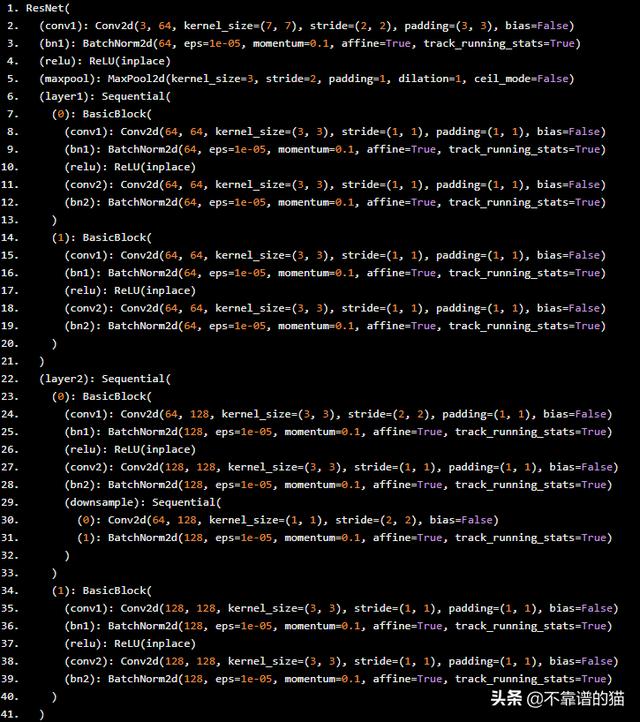
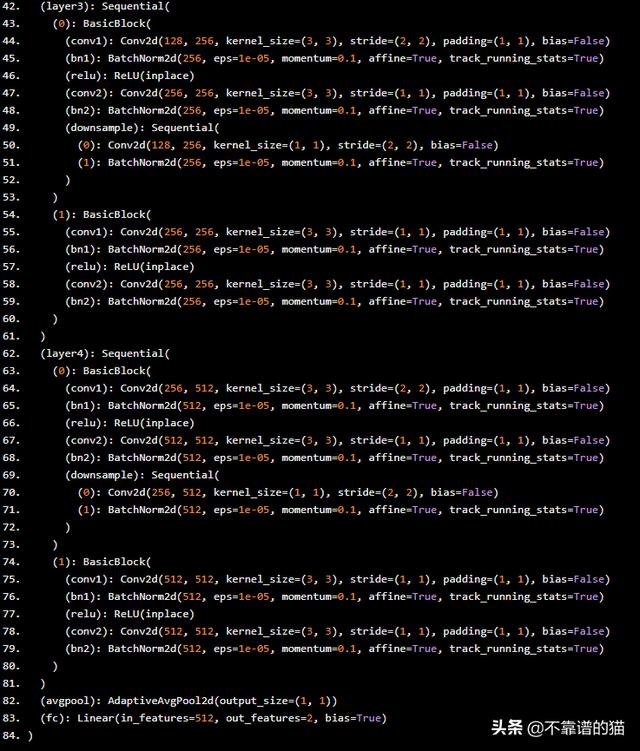
現在,訓練這個機器學習模型,更新***4層的權重。
數據集的大小很大,但數據相似性非常低
考慮這個來自kaggle,皮膚癌MNIST的數據集:HAM10000
其具有超過10015個皮膚鏡圖像,屬于7種不同類別。這不是我們在Imagenet中可以找到的那種數據。
這就是我們只保留模型架構而不保留來自預訓練模型的任何權重的地方。讓我們重新定義輸出層,將項目分類為7個類別。
- model.fc = nn.Linear(num_ftrs, 7)
這個模型需要幾個小時才能在沒有GPU的機器上進行訓練,但是如果你運行足夠的時代,你仍然會得到很好的結果,而不必定義你自己的模型架構。
數據大小很大,數據相似性很高
考慮來自kaggle 的鮮花數據集(https://www.kaggle.com/alxmamaev/flowers-recognition)。它包含4242個花卉圖像。圖片分為五類:洋甘菊,郁金香,玫瑰,向日葵,蒲公英。每個類大約有800張照片。
這是應用遷移學習的理想情況。我們保留了預訓練模型的體系結構和每一層的權重,并訓練模型更新權重以匹配我們的特定問題。
- model.fc = nn.Linear(num_ftrs, 5)
- best_model_wts = copy.deepcopy(model.state_dict())

我們從預訓練的模型中復制權重并初始化我們的模型。我們使用訓練和測試階段來更新這些權重。
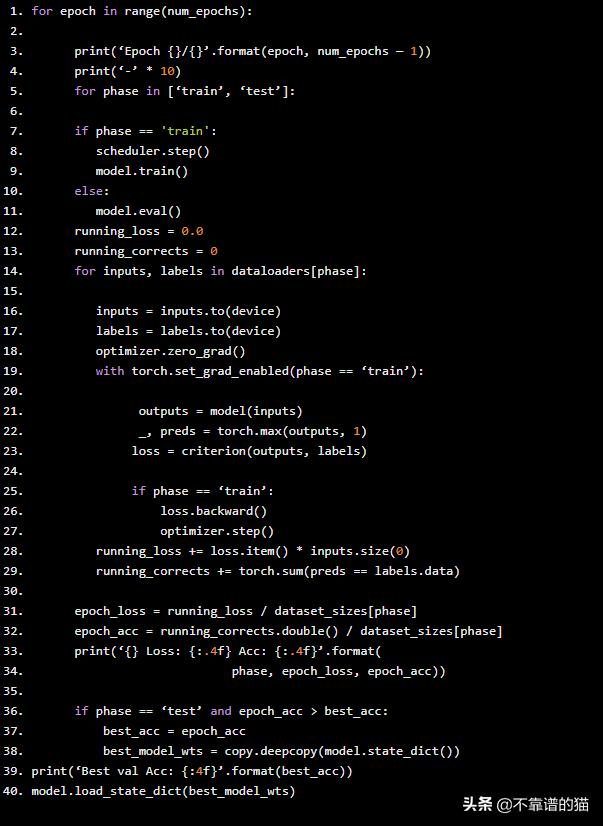
- for epoch in range(num_epochs):
- print(‘Epoch {}/{}’.format(epoch, num_epochs — 1))
- print(‘-’ * 10)
- for phase in [‘train’, ‘test’]:
- if phase == 'train':
- scheduler.step()
- model.train()
- else:
- model.eval()
- running_loss = 0.0
- running_corrects = 0
- for inputs, labels in dataloaders[phase]:
- inputs = inputs.to(device)
- labels = labels.to(device)
- optimizer.zero_grad()
- with torch.set_grad_enabled(phase == ‘train’):
- outputs = model(inputs)
- _, preds = torch.max(outputs, 1)
- loss = criterion(outputs, labels)
- if phase == ‘train’:
- loss.backward()
- optimizer.step()
- running_loss += loss.item() * inputs.size(0)
- running_corrects += torch.sum(preds == labels.data)
- epoch_loss = running_loss / dataset_sizes[phase]
- epoch_acc = running_corrects.double() / dataset_sizes[phase]
- print(‘{} Loss: {:.4f} Acc: {:.4f}’.format(
- phase, epoch_loss, epoch_acc))
- if phase == ‘test’ and epoch_acc > best_acc:
- best_acc = epoch_acc
- best_model_wts = copy.deepcopy(model.state_dict())
- print(‘Best val Acc: {:4f}’.format(best_acc))
- model.load_state_dict(best_model_wts)
這種機器學習模式也需要幾個小時的訓練,但即使只有一個訓練epoch ,也會產生出色的效果。
您可以按照相同的原則在任何其他平臺上使用任何其他預訓練的網絡執行遷移學習。本文隨機挑選了Resnet和pytorch。任何其他CNN都會給出類似的結果。希望這可以節省您使用計算機視覺解決現實世界問題的痛苦時間。