干貨|多重預訓練視覺模型的遷移學習
本文介紹的是基于Keras Tensorflow抽象庫建立的遷移學習算法模型,算法簡單、易于實現,并且具有很好的效果。
許多被稱為“深度學習”的方法已經出現在機器學習和數據科學領域。在所有的這些“深度學習”方法中,有一種尤為突出,即對已學習representations的遷移,其有一種方法在遷移已學習的representations時,其簡潔性、魯棒性、有效性尤為突出。尤其是在計算機視覺領域,這個方法展示出了***的優勢,使以前難以克服的任務變得像keras.applications import *一樣容易。
簡而言之,這個方法規定應該使用一個大型的數據集學習將所感興趣的對象(如圖像,時間序列,客戶,甚至是網絡)表示為一個特征向量,以適合數據科學研究任務,如分類或聚類。一旦學習完畢,representation機制就可供其他研究人員或其他數據集使用, 而幾乎不需要考慮新數據的數據量或可用計算資源的大小。
本文我們展示了基于預訓練計算機視覺模型的遷移學習的用途,并使用了keras TensorFlow抽象庫。預訓練計算機視覺模型已經在大型ImageNet數據集上進行了訓練,并學會了以特征向量的形式生成圖像的簡單表示。這里,我們將利用這個機制學習一個鳥類分類器。
能夠使用預訓練模型的方法有很多,其選擇通常取決于數據集的大小和可用的計算資源,這些方法包括:
- 微調(Fine tuning):在這種情況下,用適當大小的softmax層替換網絡的最終分類層,以適應當前的數據集,同時其他所有層的學習參數保持不變,然后在新任務上進行更進一步的訓練。
- 凍結(Freezing):fine-turning方法需要相對較強的計算能力和較大的數據量。對于較小的數據集,通常“凍結”網絡的一些***層,這就意味著預訓練網絡的參數在這些層中是固定的。其他層在新任務上像以前一樣進行訓練。
- 特征提取(Feature extraction):這種方法是預訓練網絡最寬松的一種用法。圖像經過網絡前饋,將一個特定的層(通常是在最終分類器輸出之前的一個層)作為一個representation,其對新任務絕對不會再訓練。這種圖像-矢量機制的輸出,在后續任何任務中幾乎都可以使用。
本文我們將使用特征提取方法。首先,我們使用單個預訓練深度學習模型,然后使用堆疊技術將四個不同的模型組合在一起。然后再對CUB-200數據集進行分類,這個數據集(由vision.caltech提供)包括200種被選中的鳥類圖像。

首先,下載數據集,MAC/Linux系統下載路徑:

或者,只需手動下載并解壓文件即可。
接下來將描述程序中的主要元素。我們省略了導入和部署代碼,以支持可讀性更好的文本,如有需要請查看完整代碼。
讓我們從加載數據集開始,用一個效用函數(here)來加載具有指定大小的圖像的數據集。當解壓數據集時創建了“CUB_200_2011”文件夾,常量CUB_DIR指向該文件夾中的“image”目錄。

首先,我們將用Resnet50模型(參見論文和keras文件)進行特征提取。注意,我們所使用的是大小為244X244像素的圖像。為了生成整個數據集的向量representations,需要添加以下兩行代碼:
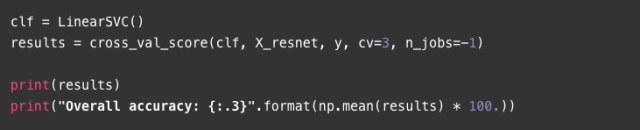
當模型被創建時,使用preprocess_input函數對初始訓練數據(ImageNet)進行規范化,即求出平均信道像素值的減法結果。ResNet50.predict進行實際轉換,返回代表每個圖像大小為2048的向量。當***被調用時,ResNet501d[1]的構造器會下載預訓練的參數文件,所需時間長短取決于您的網速。之后,用這些特征向量和簡單的線性SVM分類器來進行交叉驗證過程。
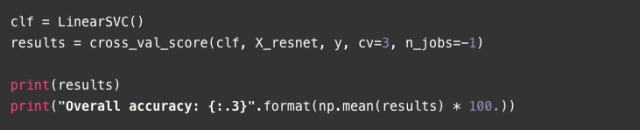
[ 0.62522158 0.62344583 0.62852745]
Overall accuracy: 62.6
通過這個簡單的方法,我們在200類數據集上達到了62.6%的準確度。在接下來的部分中,我們將使用幾個預先訓練好的模型和一個疊加方法來繼續改進這個結果。
使用多個預訓練模型后,感覺與任何情況下使用一個特征集的情況相同:它們希望提供一些不重疊的信息,從而使組合時性能更優越。
我們將使用的方法來自這四個預訓練模型(VGG19, ResNet, Inception, and Xception)派生出的特性,被統稱為“stacking”。Stacking是一個兩階段的算法,在此算法中,一組模型(基礎分類器)的預測結果被聚合并傳送到第二階段的預測器中(元分類器)。在這個例子中,每個基本分類器將是一個簡單的邏輯回歸模型。然后求出這些輸出概率的平均數,并傳送到一個線性SVM算法中來提供最終決策。

每個預訓練的模型(如上述的ResNet)都可以生成特征集(X_vgg, X_resnet, X_incept, X_xcept),我們以此作為開始(完整的代碼請參閱git repo)。方便起見,將所有的特征集合疊加到一個單獨的矩陣中,但是保留邊界索引,以便每個模型都可以指向正確的集合。

我們將使用功能強大的mlxtend擴展庫,使stacking算法變得更加容易。對于四個基本分類器中的任何一個,我們都構建了一個可以選擇適當特性的傳遞方法,并遵循LogisticRegression算法的途徑。

定義并配置堆疊分類器,以使用每個基本分類器提供的平均概率作為聚合函數。

***,我們準備測試stacking方法:

[ 0.74221322 0.74194367 0.75115444]
Overall accuracy: 74.5
提供一些基于模型的分類器,并利用這些單獨的被預先訓練過的分類器的stacking方法,我們獲得了74.5%的精確度,與單一的ResNet模型相比有了很大的提升(人們可以用同樣的方法測試其它模型,來對兩種方法進行比較)。
綜上所述,本文描述了利用多個預訓練模型作為特征提取機制的方法,以及使用stacking算法將它們結合起來用于圖像分類的方法。這種方法簡單,易于實現,而且幾乎會產生出人意料的好結果。
[1]深度學習模型通常是在GPU上訓練,如果您使用的是低端筆記本GPU,可能不適合運行我們這里使用的一些模型,因為會導致內存溢出異常,如果是這樣,那么您應該強制TensorFlow運行CPU上的所有內容,將所有深度學習相關的內容放到一個帶有tf.device("/cpu:0"): 的塊下面。