京東云總監帶你吃透分布式精髓(含視頻)
1953年,埃布·格羅希提出Grosch定律,即計算機性能會隨著成本的平方而增加。1965年,高登·摩爾提出摩爾定律:當價格不變時,集成電路上可容納的元器件的數目,約每隔18-24個月便會增加一倍。
當今,計算機的普及,也讓越來越多的電腦處于閑置狀態,即使在開機狀態下CPU的潛力也遠未被完全利用。而互聯網的出現,使得連接和調用閑置計算資源的計算機系統成為了現實。
于是,分布式計算開始普及,分布式難不難?難!所以更需名師指路!下面要介紹的課程,由京東云高級總監親自授課哦,趕快往下看吧!

本次直播課程由京東云高級總監郭理靖數據庫基礎入手,從實踐應用出發,深度解析從單機數據庫到分布式數據庫的技術發展與迭代,同時并理論結合實際為大家講述企業選擇數據庫服務的金科玉律以及京東云針對此方面的應用實踐等干貨內容。
課程概要
此次課程的分享內容更多關于數據庫服務的演變史,重點講述單機到分布式的變化從何而來以及從單機數據庫如何進行改進才可達成分布式數據庫的服務。
以下是郭理靖老師分享的全部內容,希望給各位開發者帶來更多幫助:
從單機到分布式,數據庫服務的演變史
京東云高級總監 郭理靖
1從Redis到MongoDB
從Redis到MongoDB,最初的產生都很簡單
很多時候,一門技術甚至一種產品,最初的產生往往都來源非常簡單的想法,例如2019年,我們看到DB-Engines Ranking中有兩個比較熟悉的身影,MongoDB和Redis。
很有意思的是,MongoDB屬于DocumentDB。如果我們調頭去看DocumentDB-Engines Ranking的話,可以發現MongoDB是排在***位,而且是以絕對性的優勢“吊打”第二位到第十位(第二名只有56分),整個DB-Engines中,Oracle和MySQL的分數靠得特別近;但是在DocumentDB中,MongoDB是400多分,但第二名可能就只有100多分。
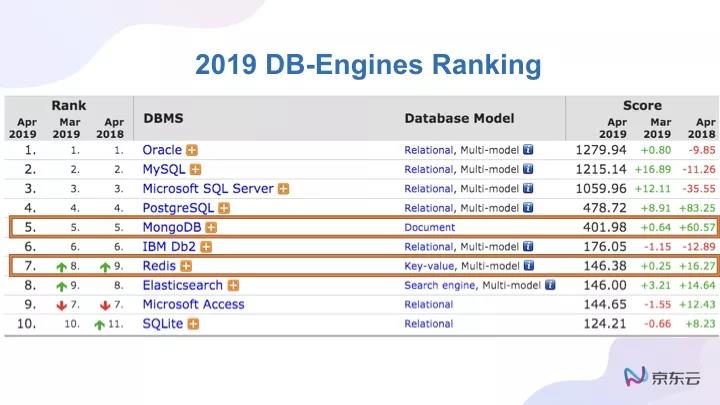
同樣,Redis在K/V的領域,分數也特別靠前,它146分,第三名是MemcacheD(第二名為Amazon DynamoDB,為56分) 只有28.7分。
所以這兩個數據庫在自己的專業領域中都是排名特別靠前的兩個數據庫,而且彼此出現的時間都不算特別長,不到十年:Redis出現的比MongoDB早一些,Redis是2009年,MongoDB差不多也是在2009年左右出現的。
為什么Redis會出現,并且成為K/VDB排名***的一個數據庫呢?
其實,在Redis出現之前已經有一個K/V的數據庫叫Memcached,早在2003年發布,最初用Perl寫了一個版本,***用C語言重寫了。在Redis沒有出現之前,Memcached一直是K/V數據庫的領頭,為什么在2009年,當Redis出現時就飛快地代替了Memcached,直至今日,大部分的緩存我們都用Redis。甚至剛入行的同學們根本沒有聽說過還有Memcached這樣的數據庫,這個過程中Redis到底做了什么事情?
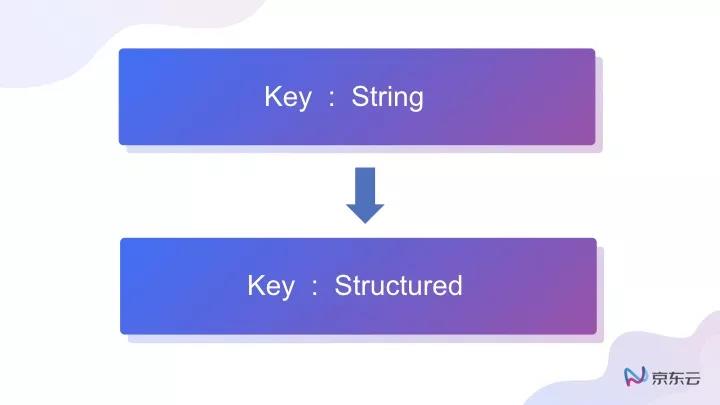
事情比較簡單,從設計理念出發,就是把原先Memcached的存儲結構進行了改變。之前是一個Key對應一個String,然后Redis把String變化成一個可以結構化的Structured storage,也就是說Redis可以支持一些結構化的數據,包括List、sorted set、hashes等 。
如此小的變化為什么能夠讓它取得這么大的優勢?關于此還是要回溯下Memcached。
假設我們自己要設計一個緩存系統的話,設計目標與Memcached一樣,過程中就需要設計一個Key String的緩存系統,那么在這個緩存系統上到底能夠提供哪些服務呢?更進一步來說,當存儲對象是String,針對此我們可以做到哪些操作?

可以想見,在一個編程語言中,以以C++或者Java為例,一個字符串可以set一個字符串,還可以get一個字符串,當然也可以delete一個字符串。此外,對于字符串我們還可以做一些其他操作,例如append、prepend等,也就是字符串的尾巴和頭部加些內容,甚至可以將整個字符串替換掉。當然,也可以做insert、erase,還有trim這種操作以及find、substr等。
大家在設計過程中不妨想一想,為什么在Memcached中不支持insert或find、substr這樣的操作呢?
這其實是一個很有意思的話題。理論上Memcached可以支持這些操作,包括針對Memcached的源代碼進行修改之后,也可以支持這些函數和調用,但之所以選擇不支持可能更多還是效率方面的考量。
例如在Memcached中支持substr或者find的操作的過程中,卻浪費了Memcached服務器的性能。因為find可以把整個字符串轉移到本地再做find,substr也是一樣,其實都歸功于性能。
當然Memcached也可以提供更高級的一些操作,例如add或者一些gets操作,還可以做incr/decr,對一個數字進行原子性加減,都可以。如果去研究Memcached整個release history的話,它是2003年開始發布的一個版本,前期支持的工作是非常有限的,所以后續的高級功能也是慢慢逐漸加進去的。
再看一下Redis,可以支持的數據結構有很多,包括Strings、Lists、Sets、Sorted sets、Hashes、Bit arrays,還有HyperLogLogs、streams,streams是5.0,***的版本甚至可以支持一些時序性的數據。

縱觀整個迭代歷程,Redis最初的簡單想法就是能不能將Strings的結構和存儲結構,讓其支持的多一些。從這個想法出發,才會逐漸發展成慢慢去支持越來越多的數據結構,支持越來越多操作類型的局面。
以C++為例,一個List操作支持pop/push,也可以支持在List中間去Insert/erase。對于Redis而言,除了常見的操作之外,我看了一下Redis整體的release history,最開始的時候也支持的是一些比較簡單的操作,例如pop/push;隨著時間的發展,支持越來越多的高級功能,都是建立在普通的操作上。
比方說BRPOPLPUSH這個功能,就是從一個List中POP一個數據出來,插入到另外一個List中去,這算是比較高級的功能體現了,但這個也是在用戶發現其需要此種場景之后才去增加的事項。

再來探究下MongoDB。MongoDB的“工作”其實與Redis有點類似,可以認為Redis就是利用K/V結構,將Strings換成了一個類似于JSON的類型,JSON中可以支持的數據結構也非常多。
MongoDB所體現的功能相似度很高。以前在設計數據庫的時候,如果是關系型數據庫,一開始就需要將Schema設計好,然后去做一個DDL操作。當需要增加一列或者減少一列的時候,以上的操作并不是很方便;特別在表單很龐大的情況下,操作時間會很長。
隨著業務的發展,是否可以用一個JSON來代替原型MySQL Schema?以這樣一種簡單的想法出發,如今盡管MySQL或者關系型數據庫還是以Schema為核心,但是MongoDB就以Document,也就是JSON這個格式為核心去構建整個數據庫的功能和生態。
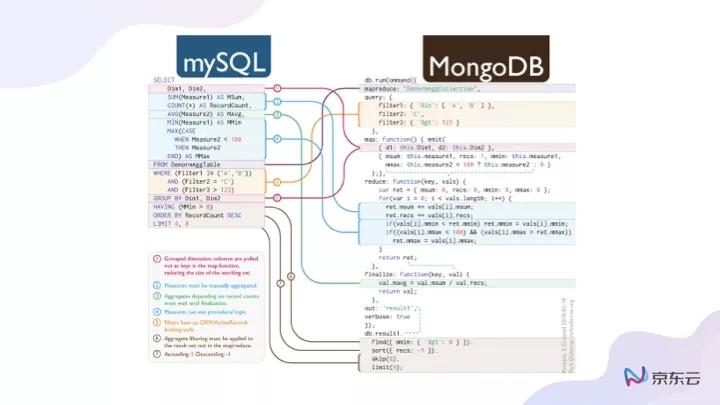
可以看到,MySQL的常見SQL語句在MongoDB中命令長度不太一樣,因為所有的命令都與JSON的格式有關,包括底層的存儲結構也會因為要保存JSON格式而做出很大變化。
這部分集中想要表達的觀點就是很多數據庫以及技術產品的演進,其實都是有脈絡可尋的,主要就是設定解決問題的目標進而完成底層數據結構的修改,其中底層結構確定之后還會在一定程度上影響產品功能,例如MongoDB在很長一段時間內都不支持事務,不是不想去嘗試支持,而是取決于底層存儲結構的存儲引擎,無法支持事務。
同樣的道理,探究Memcached和Redis的內存管理設計,也會發現,Memcached的開發者或者說社區,也想去支持像Redis一樣的功能,但事實上由于底層的存儲結構注定無法提供此類服務。
2分布式從何而來?
為什么會有分布式?主要還是由于處在信息爆炸的時代,業務量逐漸龐大導致單機數據庫并不能更好滿足需求,自然要尋找一些可行的解決方案。
這里的解決方案可以分為兩種,一類相當于表層的解決方案,操作起來比較簡單,其中涉及客戶端的方案以及統一代理的方案等,例如proxy的方案。
相比之下,底層的方案可以分為三類。***類是分布式塊存儲方案,第二類是計算與存儲分離方案,第三類就是要另起爐灶了。

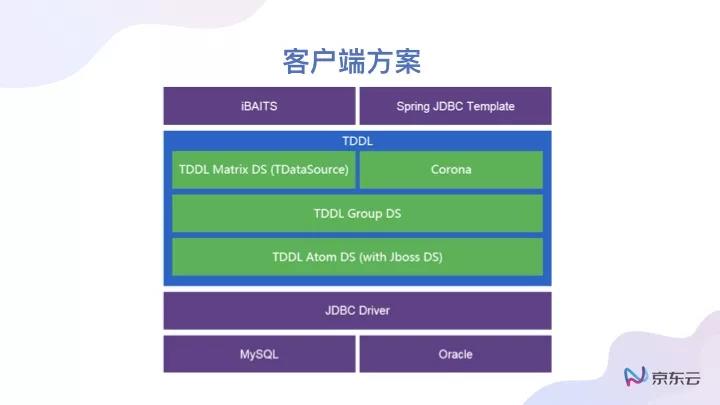
首先客戶端方案,可以以友商開源的項目稱為TDDL為代表,方案思路較為清晰。如果我們自身需要做一個分布式系統的話,將分布式解決方案放入客戶端內,最重要的就是“告訴”客戶端SQL語句應該鏈接到背后哪個數據庫,畢竟不同的數據存儲在不同的機器當中。對于客戶端的方案,比較重要的就是與后端的一些連接,以及如何解析這個SQL語句。
第二種方案就是Proxy方案。Proxy方案相對客戶端方案而言,開發難度稍微高一些,但思路上還是非常一致的。舉例說明,一張用戶表,用戶表的組件是ID,我們對ID的分布式key進行分布,查詢具體某一個用戶ID的時候其實就有一個Proxy,如果說查詢這個用戶ID為0,進而就知道0是存在于后臺的哪一臺MySQL。
所以對于Proxy而言,非常重要的一點還是需要去解析具體的SQL語句,這個過程中必須需要有一個自己的路由,就可以完成識別。

客戶端的方案與Proxy方案的區別在哪里?區別在于客戶端的方案開發起來相對比較簡單一點,在JDBC中或者要求客戶端調用時,客戶端可以不解析SQL語句,完成導向很容易。
對于Proxy方案,它需要兼容原有的MySQL協議,怎么建立MySQL連接,怎么與后端保持連接,這個難度比較大。但相對而言,Proxy方案的限制也比較多,不管是客戶端的表層方案,還是Proxy的表層方案,它們對SQL的使用要求都是比較高的,例如一些join是比較難支持的,而且要與業務方達成一致。
此外,無論是客戶端方案還是Proxy方案,整體架構還是比較類似的。例如Proxy方案,它會涉及前端如何與客戶端進行連接以及后端的Backend connection,還要與后端真正提供MySQL服務的保持連接,這是兩個連接的管理。
經過了解,整個Proxy一般的設計都會采取無狀態,因為路由信息都是保存在Proxy本機的;但路由方面肯定有一個相對的路由管理中心去分發和更改控制。業界大部分Proxy設計,大家都會發現,Proxy代理的方案其架構設計非常相像,區別在于工程質量不同而已。
另外,對于Proxy方案的缺點就是怎么去做一個分布式事務,沒辦法保證次序。通常在一個分布式的情況下,其實很難保證每個節點上的事務執行是按照我們想像中的次序去做。
講完表層的解決方案之后,我們還需要講講比較深層次的底層解決方案。從表層出發,不管是客戶端方案還是Proxy方案,都并沒有去改變底層MySQL的整體協議,也沒有改變數據庫原生服務,可以認為根本就沒有讓MySQL底層代碼發生變動。
如今可知曉的底層解決方案主要有三個,***個方案是塊存儲方案,包括SAN解決方案,涉及云端就是云硬盤解決方案,都是同一類型的。
但如果真正要做一個數據庫的解決方案,目前的主流思路還是計算與存儲分離,為什么會出現計算與存儲分離呢?主要原因有以下幾點:現在的網絡延時一直在下降,帶寬一直在增長,從我個人的工作經驗來看,未來可能還有更大的網絡帶寬出現;但與此同時,磁盤IO的吞吐量并沒有增長得像網絡這么快。
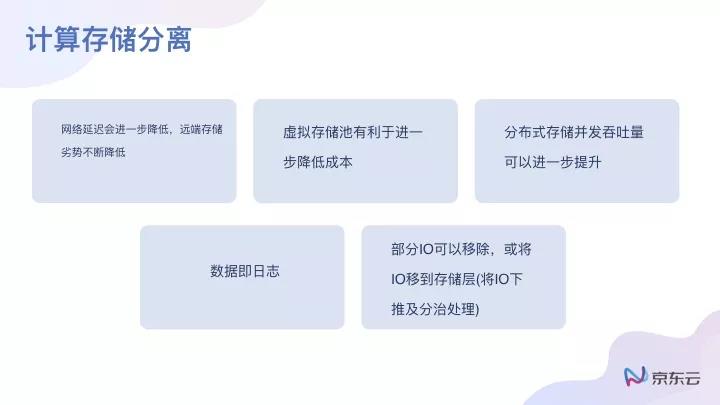
此外,存儲的虛擬化有利于成本下降,分布式存儲有利于提高IOPS。如果在一個機器上做Raid的話,它的性能會比單個硬盤要好很多;如果采用分布式系統寫入,它的IOPS其實會更高。
目前業界比較有名的幾個計算與存儲分離的解決方案,***的就是亞馬遜的Aurora。
Aurora為什么選擇計算存儲分離?關于這一點,還需要探究當時亞馬遜做RDS的解決方案如何。亞馬遜RDS,就是它們的Realtional Database Service,整體數據存在local disk/EBS上面。
我們可以看到,整個IO的寫入鏈條是比較長的,要把數據落盤,binlog落盤,redo log落盤,而且整個binlog兩邊要同步,***還要把EBS的數據適當地備份到云存儲中去。(這個只是備份,與實時寫入無關)。
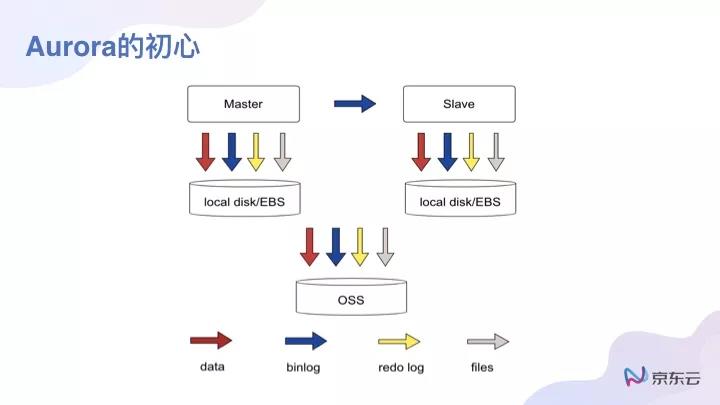
由于鏈路比較長,而且包括整個EBS的實現中,EBS就是個分布式的快存儲,本質上也是多副本的。在多副本的情況下,EBS在遠端也要做整個數據的同步,所以Aurora的設計目標就是思考能不能把存儲與計算做一些相應的分離。出發點就是數據庫存儲引擎能不能與分布式塊存儲融合在一塊,融合成一個新的存儲引擎。
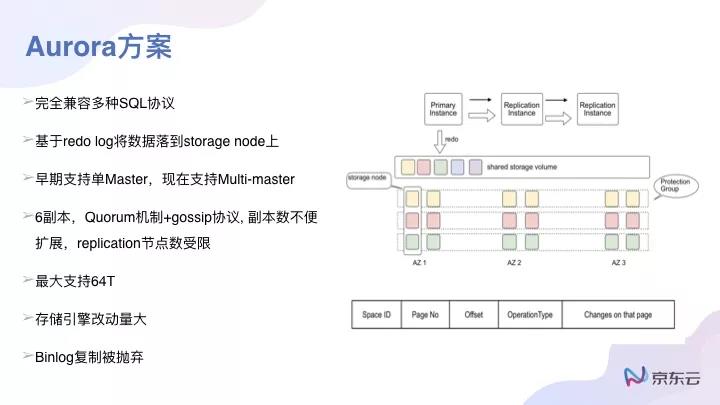
另外一個方案是F1/Spanner的方案,思路又是什么呢?
做一個分布式系統,如果去兼容MySQL比較麻煩的話,那是不是可以另起爐灶,做一個新的分布式系統。
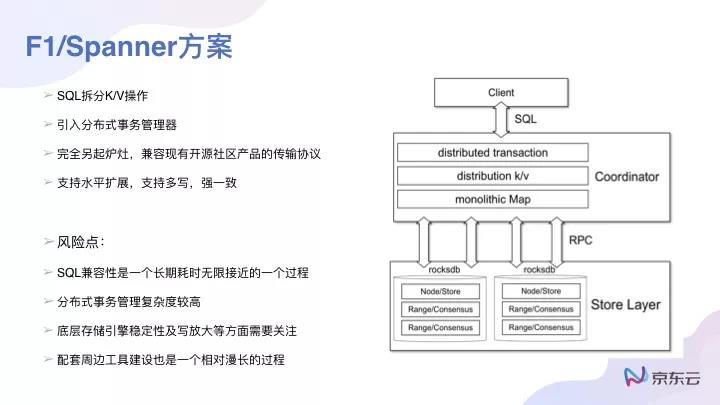
它的思路很簡單,就是重新去改寫一些SQL,所以像F1/Spanner并不兼容MySQL的一些協議時,就會引入新的分布式事務管理,把SQL都拆解成K/V的一些操作結構,對這種方案而言,SQL的兼容性是個長期耗時而且是***接近的一個過程,主要需兼容已有的生態會比較費力。但如果是一個新業務,用這種分布式方案就沒有問題;如果是個舊業務,有自己成熟的SQL,想用它就比較困難了。
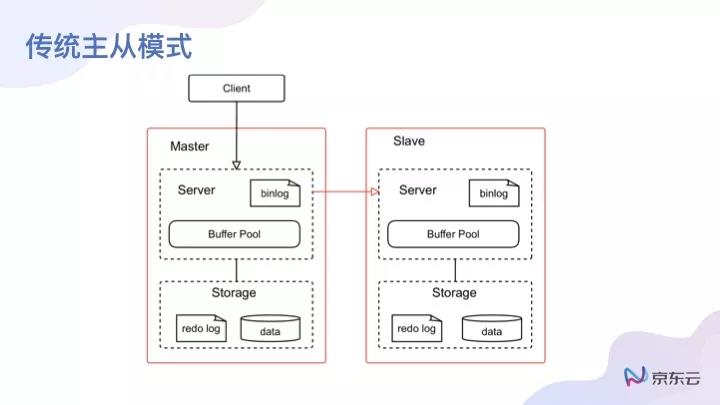
可以看到對一個MySQL服務而言,其實有兩部分組成,一部分是Server,一部分Storage。Storage標準的架構是redo log加個data,這是InnoDB的一個結構,如今InnoDB已經成為MySQL的一個標準,大家都是按照這種方式去做的。
關于主從同步,是用binlog復制的方式,把binlog復制到Slave這邊,Slave對binlog重放,然后Slave就有完整數據,這是傳統的一個數據庫組成模式。
對于MySQL而言,它的數據流向會是什么樣子的?***步,如果針對一個事務或者一個SQL語句,它會寫很多redo log。第二步,會寫到binlog中,binlog以后會做半同步,會同步到Slave中,返回一個信息,這時候可以進行一個整體的commit。
對于整個數據流向的一個示意圖,主從之間用了整體的binlog復制方式去做。如果想做一個分布式系統的話,而且出發點是不能夠將這些一樣的數據放在同一個分布式系統中,需要做哪些事情?
我們發現,如果計算和存儲分離之后,把所有的存儲都放在一個分布式存儲系統中去,master與slave讀的是同一個數據,其實就不需要binlog了,這個是比較容易理解的。binlog用來傳輸具體的數據,因為數據都放在一起。
3計算和存儲分離的優點
在于分布式存儲的存儲空間會相對大一些;另外一點,如果說要增加一個新的slave,以前在MySQL的主從復制中增加一個新的slave,通常怎么做?
要么就新建一個空白的slave,慢慢從組合開始同步數據,總而言之就是利用binlog同步數據;但如果整個數據量比較大的話,建立一個新的從時間會非常長,或者說根據備份去重建一個新的從,進而拷貝數據庫備份。在這個基礎上再去追新日志,無論如何增加一個節點,時間應該還是要以分鐘計,至少以10分鐘為單位。
但在計算與存儲分離之后,新建一個slave時間就非常快了,而且備份數據的時候會快很多。因為針對傳統主從系統做備份,其實都要去做一個文件系統的備份。做文件系統快照也行,用mysql dump也行,需要把本地文件傳到云端存儲;在分布式存儲系統中,可以把這個任務轉移給底層系統去做,當然數據的強一致還要靠底層存儲去保證。
如果把計算、存儲分離之后,整個高可用切換會是什么樣子的?對于以前的MySQL而言,一個主從切換其實比較簡單,因為主跟從是兩個獨立的存儲和計算,之間沒有關聯關系,主切換到從,最多就是binlog還沒有回放完;但對于整個計算存儲分離之后,它的變化還是有一些的。
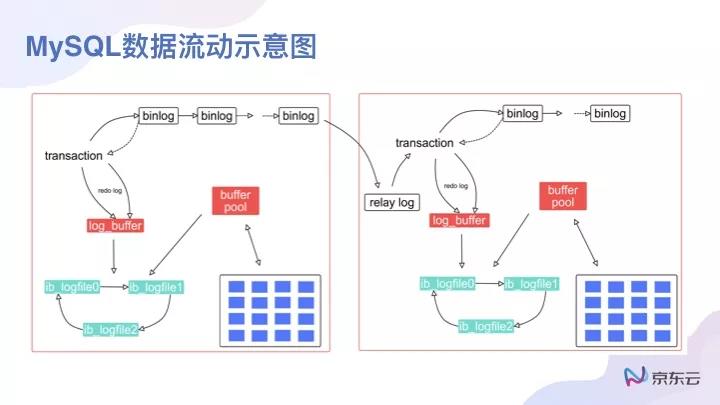
例如***個變化,我們可以看到對于傳統數據庫而言,它的Redo日志是一個循環的文件系統,可以是三個Redo日志循環使用;如果在一個存儲分離,計算分離的環境,它的Redo日志基本會設計成按編號去排序的情況。
等主從切換之后,log buffer和buffer pool,也許需要一點時間去重建它的兩個buffer pool。因為在傳統意義上,傳統的MySQL主從切換都需要去根據日志稍微重建一下buffer pool。
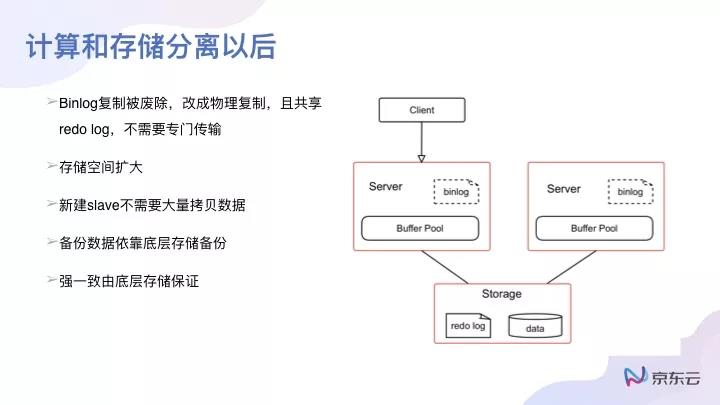
對于備份而言,基本上變化也比較大,整個備份會基于底層的塊存儲:一部分可以去備份整個page頁的數據;另外一部分,需要去做Redo日志的增量備份,這樣很快能完成一個數據庫的備份。
其實在云端去做一個數據庫的備份會比自己搭建兩臺物理機去做備份更快,為什么?
因為在云端分布式系統中,做備份的時候不是一臺機器在備份,因為存儲在不同的機器上。 對于一個新建的slave而言,如果我們在云端計算、存儲分離的情況下去新建一個slave的話,新建slave的速度也會比傳統的方式快非常多,因為整個數據塊是已經存在了,直接去讀就行,不需要重新再復制一份。
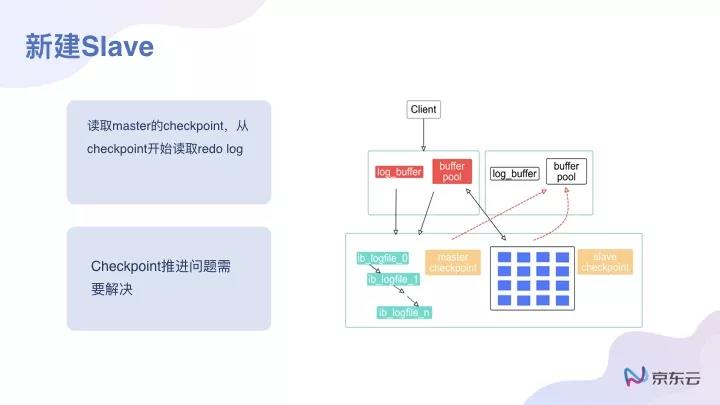
但是這種情況也帶來不少問題。因為底層的文件系統其備份數是有限的,副本數也是有限的,深層次的原因是因為底層的分布式文件系統的IOPS是有限的,對于一個主從關系,像傳統模式下的MySQL,其實并沒有這種限制。
4總結
***總結一下這幾個方案的優缺點:
比如客戶端方案,它的優點是可以接多種數據源,只要數據庫是兼容JDBC的,都可以去對接,而且性能上比較好。但提高性能的同時也帶來另外一個問題,連接數可能會比較多,因為客戶端非常多,每個客戶端都與MySQL進行連接的話,MySQL連接會特別多。
缺點也非常明顯,如果公司中只以Java為主,那沒問題,開發一個jar包,大家用起來會非常熟悉;如果說一個公司用Python、C++,還用Go,每個語言都要寫一個客戶端,其實是非常痛苦的。另外客戶端發布了,SDK發布之后升級起來也非常麻煩。
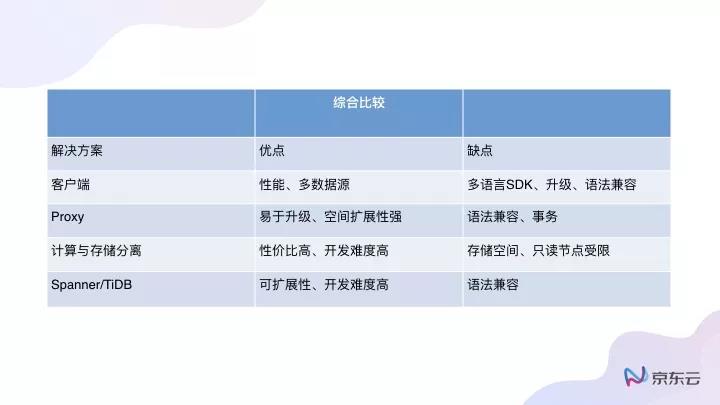
所以絕大部分的廠商會采用Proxy的方案,因為Proxy的方案容易管理,升級也比較容易,而且語法基本兼容,不存在多語言SDK的問題。兼容了MySQL的一些語法之后,傳統的MySQL客戶端,各種語言的SDK都能用,所有MySQL第三方開發的SDK也都能用,缺點在于不支持事務,或者對事務的支持是有限的。
對于計算與存理分離方案而言,它的優點非常明顯且性價比特別高,為什么?
云端購買云數據庫的時候,很多時候性能與購買有關系。例如買個1C2G10GB的小型數據庫,OPS可能只有幾百上千;但對于真正的計算與存儲分離的方案而言,開始購買的類型可能是比較小的,購買的規格可能也比較小,但是可以達到很高的IOPS性能,數據庫性能并不會受限于你購買的規格。
關于缺點,還是整體的存儲空間有限,可能***只能支持64T或者128T,因為每個數據庫的分布式存儲中其副本數是有限的,只讀節點可能受限于,只能有15個或者14個,但這個都不要緊。我相信對于絕大多數的用戶而言,這個還是足夠用的。另外一個缺點是開發難度,但這個缺點只是開發廠商的痛點,與用戶沒有關系。
對于另起爐灶,像Spanner/TiDB這種數據庫方案,它的可擴展性就比較高。因為對于像Aurora這種計算與存儲分離的數據庫而言存儲空間畢竟是有限的,但對這種數據庫,它的存儲空間可以被認為是***擴展的,可以支持一個上P的數據庫也沒問題。
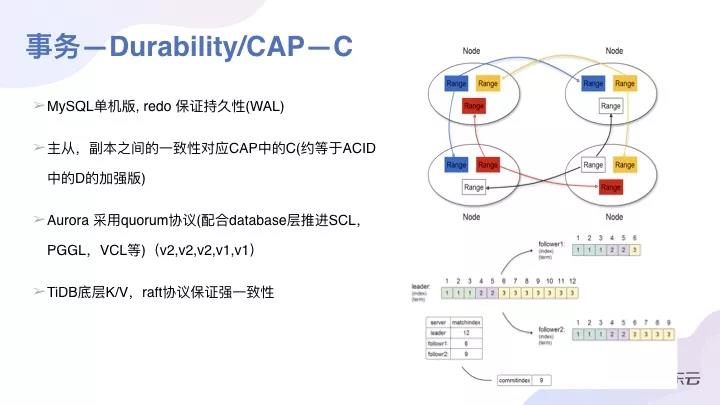
依舊談談缺點。就是很難去兼容現有的一些SQL語法,是一個比較大的挑戰。例如TiDB是國產比較優秀的數據庫了,也號稱對MySQL的語法兼容是比較***的,但事實上還是很多語句是沒法做到兼容的,不是不想,是因為做起來特別難!因為底層的數據結構決定了一些功能,也決定了要去兼容一些SQL語句其代價是非常大的。
【本文為51CTO專欄作者“京東云”的原創稿件,轉載請通過作者微信公眾號JD-jcloud獲取授權】