帶你吃透幾種大廠分布式ID設計方案
作者:無聊
最近公司在擴招后端高級開發,有幸成為面試官之一,其中問的最多一個問題就是分布式ID的幾種解決方案,不客氣的說前身小公司的開發答得完整的很少。
本文轉載自微信公眾號「無聊學Java」,作者無聊。轉載本文請聯系無聊學Java公眾號。
前言
最近公司在擴招后端高級開發,有幸成為面試官之一,其中問的最多一個問題就是分布式ID的幾種解決方案,不客氣的說前身小公司的開發答得完整的很少。
于是就抽出了周末的時間整理了幾種主流的分布式ID生成方案,希望能夠幫助到你們。
開篇幾個問題
1. 為什么需要分布式全局唯一ID以及分布式ID的業務需求
在復雜分布式系統中,往往需要對大量的數據和消息進行唯一標識。
- 如在美團點評的金融、支付、餐飲、酒店等業務場景
- 貓眼電影等產品的系統中數據日漸增長,對數據分庫分表后需要有一個唯一ID來表示一條數據或者消息。
- 特別一點的如訂單、騎手、優惠劵也都需要一個唯一ID做為標識。
此時一個能生成唯一ID的系統是非常必要的。
2. ID生成規則部分硬性要求
- 全局唯一:既然是唯一標識,那么全局唯一是最基本的要求。
- 趨勢遞增:在MySQL的InnoDB引擎中使用的是聚集索引,由于多數RDBMS使用Btree的數據結構來存儲索引數據,在主鍵的選擇上面我們應該盡量使用有序的主鍵來保證寫入性能。
- 單調遞增:保證下一個ID一定大于上一個ID,例如事務版本號、IM增量消息、排序等特殊需求。
- 信息安全:如果ID是連續的,那么惡意用戶的扒取工作就非常容易做了,直接按照順序下載指定URL即可;如果是訂單號那么更加危險,競爭對手可以知道我們一天的單量;所以在一些應用場景下,需要ID無規則不規則,讓競爭對手不好猜。
- 含時間戳:這樣就能在開發中快速了解這個分布式ID的生成時間。
3. ID生成系統的可用性要求
- 高可用:發一個獲取分布式ID的請求,服務器就要保證99.999%的情況下給我創建一個唯一分布式ID
- 低延遲:發一個獲取分布式ID的請求,服務器就要快,極速
- 高QPS:假如并發一口氣10萬個創建分布式ID請求同時過來,服務器需要頂得住且成功創建10萬個分布式ID
通用的幾種方案
隨著系統架構以及業務的演變,分布式ID生成也是有N中解決方案,以下就簡單的列舉幾種。
1. UUID
這種方案估計大家都了解,最簡單的一種方案。
- public static void main(String[] args) {
- String uuid = UUID.randomUUID().toString();
- System.out.println(uuid);
- }
如果只是考慮唯一性,那么UUID基本可以滿足需求。
缺點
- 無序:無法預測他的生成順序,不能生成遞增有序的數字
- 主鍵:ID作為主鍵時在特定的環境下會存在一些問題,比如做DB主鍵的場景下,UUID非常不適用,MySQL官方有明確的建議主鍵要盡量越短越好,36位的UUID不合要求。
- 索引:會導致B+樹索引的分裂。
2. 數據庫自增主鍵
此種方案有一定的局限性,在高并發集群上此策略不可用。
3. 基于Redis生成全局ID策略
- 因為Redis是單線程,天生保證原子性,所以可以使用INCR和INCRBY來實現。
- 集群分布式
在Redis集群下,同樣和MySQL一樣需要設置不同的增長步數,同時key需要設置有效期;可以使用Redis集群來獲取更高的吞吐量;假如一個集群中有五個Redis,那么初始化每臺Redis步長分別是1,2,3,4,5,然后步長都是5。

4. snowflake(雪花算法)
- 推特的雪花算法生成ID能夠按照時間有序生成。
- 雪花算法生成ID的結果是一個64bit大小的整數,為一個Long型(轉換為字符串后長度最多19)
- 分布式系統內不會產生ID碰撞(由datecenter和workerId作區分),并且效率較高。
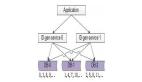
結構
雪花算法的幾個核心組成部分如下圖:

號段解析
- 1bit符號位:不用,因為二進制最高位是符號位,1表示負數,0表示正數,生成的id一般都是用正數,所以最高位固定位0
- 41bit時間戳,用于記錄時間戳,毫秒級
- 41位可以表示2^41 - 1個數字
- 如果只用來表示正整數(計算機正數包含0),可以表示的數值范圍是0-2^41 - 1,減一是因為可表示的數值范圍是從0開始算的,而不是1
- 也就是說41位可以表示2^41 - 1個毫秒的值,轉換為單位年則是69年。
- 10bit工作進程位,用于記錄工作機器id
- 可以部署在2^10 = 1024個節點,包括五位datacenterId和五位workerId
- 五位可以表示的最大整數位2^5 - 1 = 31,即可以使用0,1,2…31這32個數字來表示不同的datacenterId和workerId
- 12bit序列號,序列號,用來記錄同毫秒內 產生的不同的ID
- 12bit可以表示的最大正整數位2^12 - 1 = 4095,即可以表示0,1….4094這4095個數字
- 表示同一機器同一時間戳(毫秒)中產生的4095個ID序號
優點
- 所有生成的id按時間趨勢遞增
- 整個分布式內不會產生重復id,因為有datacenterId和workerId來做區分。
- 毫秒數在高位,自增序列在低位,整個ID都是趨勢遞增的
- 不依賴數據庫、redis等第三方系統,以服務的方式部署,穩定性更高,生成ID的性能也是非常高的。
- 可以根據自身業務分配bit位,非常靈活。
缺點
- 依賴機器時鐘,如果機器時鐘回退,會導致重復ID生成
- 在單機上是遞增的,但是由于設計到分布式環境,每臺機器上的時鐘不可能完全同步,有時候會出現不是全局遞增的情況。(此缺點可以認為蕪鎖胃,一般分布式ID只要求趨勢遞增,并不會嚴格要求遞增,90%的需求都只需要趨勢遞增)
源碼
- /**
- * twitter的snowflake算法 -- java實現
- *
- * @author beyond
- * @date 2016/11/26
- */
- public class SnowFlake {
- /**
- * 起始的時間戳
- */
- private final static long START_STMP = 1480166465631L;
- /**
- * 每一部分占用的位數
- */
- private final static long SEQUENCE_BIT = 12; //序列號占用的位數
- private final static long MACHINE_BIT = 5; //機器標識占用的位數
- private final static long DATACENTER_BIT = 5;//數據中心占用的位數
- /**
- * 每一部分的最大值
- */
- private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
- private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
- private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
- /**
- * 每一部分向左的位移
- */
- private final static long MACHINE_LEFT = SEQUENCE_BIT;
- private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
- private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;
- private long datacenterId; //數據中心
- private long machineId; //機器標識
- private long sequence = 0L; //序列號
- private long lastStmp = -1L;//上一次時間戳
- public SnowFlake(long datacenterId, long machineId) {
- if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {
- throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");
- }
- if (machineId > MAX_MACHINE_NUM || machineId < 0) {
- throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
- }
- this.datacenterId = datacenterId;
- this.machineId = machineId;
- }
- /**
- * 產生下一個ID
- *
- * @return
- */
- public synchronized long nextId() {
- long currStmp = getNewstmp();
- if (currStmp < lastStmp) {
- throw new RuntimeException("Clock moved backwards. Refusing to generate id");
- }
- if (currStmp == lastStmp) {
- //相同毫秒內,序列號自增
- sequence = (sequence + 1) & MAX_SEQUENCE;
- //同一毫秒的序列數已經達到最大
- if (sequence == 0L) {
- currStmp = getNextMill();
- }
- } else {
- //不同毫秒內,序列號置為0
- sequence = 0L;
- }
- lastStmp = currStmp;
- return (currStmp - START_STMP) << TIMESTMP_LEFT //時間戳部分
- | datacenterId << DATACENTER_LEFT //數據中心部分
- | machineId << MACHINE_LEFT //機器標識部分
- | sequence; //序列號部分
- }
- private long getNextMill() {
- long mill = getNewstmp();
- while (mill <= lastStmp) {
- mill = getNewstmp();
- }
- return mill;
- }
- private long getNewstmp() {
- return System.currentTimeMillis();
- }
- public static void main(String[] args) {
- SnowFlake snowFlake = new SnowFlake(2, 3);
- for (int i = 0; i < (1 << 12); i++) {
- System.out.println(snowFlake.nextId());
- }
- }
- }
測試
- //測試使用雪花算法生成ID
- //構造函數中傳入datacenterId和workerId
- SnowFlake snowFlake = new SnowFlake(1,1);
- for (int i = 0; i < 10; i++) {
- long id = snowFlake.nextId();
- System.out.println("id:" + id + "\t" + String.valueOf(id).length() + "位");
- System.out.println("------------------------------------------");
- }

Spring Boot整合雪花算法
引入hutool-all,maven依賴引入如下:
- <dependencies>
- <dependency>
- <groupId>cn.hutool</groupId>
- <artifactId>hutool-all</artifactId>
- <version>5.4.2</version>
- </dependency>
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-web</artifactId>
- <version>2.2.1.RELEASE</version>
- </dependency>
- <dependency>
- <groupId>org.projectlombok</groupId>
- <artifactId>lombok</artifactId>
- <version>1.18.16</version>
- </dependency>
- </dependencies>
創建一個SnowFlake配置類
- @Configuration
- public class SnowFlakeConfig {
- @Value("${application.datacenterId}")
- private Long datacenterId;
- @Value("${application.workerId}")
- private Long workerId;
- /***
- * 注入一個生成雪花ID的對象
- * @return
- */
- @Bean
- public Snowflake snowflake() {
- return new Snowflake(workerId,datacenterId);
- }
- }
yml配置文件:
- application:
- datacenterId: 2
- workerId: 1
- server:
- port: 7777
service 層:
- @Service
- public class OrderService {
- @Autowired
- private Snowflake snowflake;
- public String getIdBySnowFlake() {
- return String.valueOf(snowflake.nextId());
- }
- }
其他開源的解決方案
很多大廠都對雪花算法做出了改進,開源了一些改進方案,如下:
- 百度開源的分布式唯一ID生成器UidGenerator
- Leaf–美團點評分布式ID生成系統
責任編輯:武曉燕
來源:
無聊學Java