進擊的 Kafka:不止消息隊列,新一代流數據處理平臺
為數據而生,以 20 世紀***影響力的作家命名,一個很酷的開源項目——我們說的是Kafka。進入出生第九個年頭的 Kafka 已經算不上年輕,但依舊活力四射。這篇文章簡單梳理一下 Kafka 的發展脈絡,文末給出了本文的參考資料,以及一個快速實用 Kafka 的課程,參考資料和課程以供感興趣的讀者深入學習。
誕生背景
每一次科學家們發生分歧,都是因為掌握的數據不夠充分。所以我們可以先就獲取哪一類數據達成一致。只要獲取了數據,問題也就迎刃而解了。要么我是對的,要么你是對的,要么我們都是錯的。然后我們繼續研究。
——Neil deGrasse Tyson
2010 年前后, 跟不少互聯網公司一樣,Linkedin 每天采集的數據種類多(日志消息、度量指標、用戶活動記錄、響應消息,等等),規模大,其中很多數據由不同數據源實時生成。數據生產者和消費者之間點對點的數據傳輸方式和多個獨立發布與訂閱系統的維護成本越來越高,由此, 把不同來源數據整合到一起集中管理的需求越來越強,公司開始研究一套高效的數據管道。隨后,Kafka 從 Linkedin 內部作為一套基于發布與訂閱的消息系統誕生。
關鍵時間節點
2010 年 10 月,Kafka 在 Linkedin 誕生
2011 年 7 月,進入 Apache 孵化器,并發布***個開源版本 0.7.0
2012 年 10 月,從孵化器畢業,成為***開源項目,同時發布 0.8.0 版本
2014 年 11 月,Confluent 成立。同年,發布 0.8.2 和 0.9.0,在 0.9.0 版本加入了配額和安全性
2017 年 11 月,1.0.0 版本正式發布,Exactly-Once 與運維性能提升
2018 年 7 月,2.0.0 版本發布,注重流式數據平臺的在線可進化性
2018 年 12 月,Kafka 團隊修改 KSQL 等的開源許可
簡單介紹
Kafka 數據關鍵詞
消息與鍵
Kafka 的數據單元稱為消息,可以把消息看成數據庫里的一個“數據行”或一條“記錄”。消息由字節數組組成,對于 Kafka 來說,消息里的數據沒有特別的格式或含義。消息可以有一個可選的元數據——鍵。鍵也是一個字節數組,沒有特殊含義。為消息選取分區的時候會用到鍵。
消息與批次
為提高效率,消息分批次寫入 Kafka。批次就是一組消息,它們屬于同一個主題和分區。把消息分成批次傳輸可以減少網絡開銷。
主題與分區
Kafka 的消息通過主題進行分類。主題就好比數據庫的表。主題可以被分為若干個分區,一個分區就是一個提交日志。消息以追加的方式寫入分區,然后以先入先出的順序讀取。一個主題一般包含幾個分區。
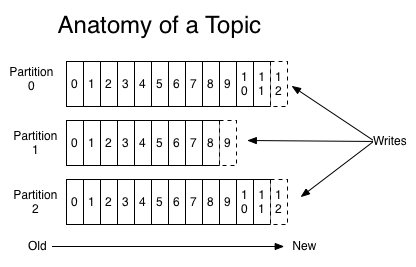
圖片來自 https://kafka.apache.org
流
我們通常會使用流這個詞來描述 Kafka 這類系統的數據。很多時候,人們把一個主題的數據看成一個流。流是一組從生產者移動到消費者的數據。
核心API
- Kafka Producer API:直接生成數據的應用程序(如日志、物聯網)
- Kafka Connect Source API:用于數據集成的 API(如 MongoDB、REST API)
- Kafka Streams API / KSQL:用于流處理的 API,如果能夠以 SQL 方式實現查詢邏輯就使用 KSQL,如果需要編寫復雜邏輯就用 Kafka Streams
- Kafka Consumer API:讀取數據流并執行實時操作(如發送電子郵件)
- Kafka Connect Sink API :讀取數據流并將其存儲到目標存儲中(如 Kafka 到 HDFS、Kafka 到 MongoDB 等)
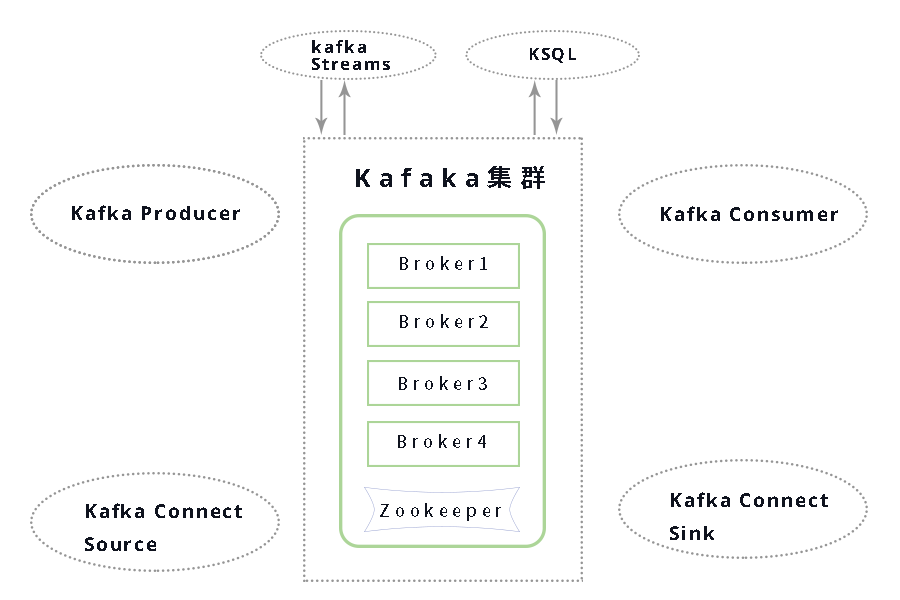
中間部分的 Kafka 集群,由多個 broker 組成。一個獨立的 Kafka 服務器被稱為 broker。broker 接收來自生產者的消息,為消息設置偏移量,并提交消息到磁盤保存。broker 為消費者提供服務,對讀取分區的請求作出響應,返回已經提交到磁盤上的消息。根據特定的硬件及其性能特征,單個 broker 可以輕松處理數千個分區以及每秒***的消息量。
應用場景
活動跟蹤
Kafka 最初的使用場景是跟蹤用戶的活動。網站用戶與前端應用程序發生交互,前端應用程序生成用戶活動相關的消息。這些消息可以是一些靜態的信息,比如頁面訪問次數和點擊量,也可以是一些復雜的操作,比如添加用戶資料。這些消息被發布到一個或多個主題上,由后端應用程序負責讀取。這樣,我們就可以生成報告,為機器學習系統提供數據,更新搜索結果,或者實現其他更多的功能。
傳遞消息
Kafka 的另一個基本用途是傳遞消息。應用程序向用戶發送通知(比如郵件)就是通過傳遞消息來實現的。這些應用程序組件可以生成消息,而不需要關心消息的格式,也不需要關心消息是如何被發送的。一個公共應用程序會讀取這些消息,對它們進行處理:
- 格式化消息(也就是所謂的裝飾);
- 將多個消息放在同一個通知里發送;
- 根據用戶配置的***項來發送數據。
使用公共組件的好處在于,不需要在多個應用程序上開發重復的功能,而且可以在公共組件上做一些有趣的轉換,比如把多個消息聚合成一個單獨的通知,而這些工作是無法在其他地方完成的。
度量指標和日志記錄
Kafka 也可以用于收集應用程序和系統度量指標以及日志。Kafka 支持多個生產者的特性在這個時候就可以派上用場。應用程序定期把度量指標發布到 Kafka 主題上,監控系統或告警系統讀取這些消息。Kafka 也可以用在像 Hadoop 這樣的離線系統上,進行較長時間片段的數據分析,比如年度增長走勢預測。日志消息也可以被發布到 Kafka 主題上,然后被路由到專門的日志搜索系統(比如 Elasticsearch)或安全分析應用程序。更改目標系統(比如日志存儲系統)不會影響到前端應用或聚合方法,這是 Kafka 的另一個優點。
提交日志
Kafka 的基本概念來源于提交日志,所以使用 Kafka 作為提交日志是件順理成章的事。我們可以把數據庫的更新發布到 Kafka 上,應用程序通過監控事件流來接收數據庫的實時更新。這種變更日志流也可以用于把數據庫的更新復制到遠程系統上,或者合并多個應用程序的更新到一個單獨的數據庫視圖上。數據持久化為變更日志提供了緩沖區,也就是說,如果消費者應用程序發生故障,可以通過重放這些日志來恢復系統狀態。另外,緊湊型日志主題只為每個鍵保留一個變更數據,所以可以長時間使用,不需要擔心消息過期問題。
流處理
流處理是又一個能提供多種類型應用程序的領域。可以說,它們提供的功能與 Hadoop 里的 map 和 reduce 有點類似,只不過它們操作的是實時數據流,而 Hadoop 則處理更長時間片段的數據,可能是幾個小時或者幾天,Hadoop 會對這些數據進行批處理。通過使用流式處理框架,用戶可以編寫小型應用程序來操作 Kafka 消息,比如計算度量指標,為其他應用程序有效地處理消息分區,或者對來自多個數據源的消息進行轉換。
為什么選擇 Kafka
基于發布與訂閱的消息系統那么多,為什么 Kafka 會是一個更好的選擇呢?
多個生產者
Kafka 可以無縫地支持多個生產者,不管客戶端在使用單個主題還是多個主題。所以它很適合用來從多個前端系統收集數據,并以統一的格式對外提供數據。例如,一個包含了多個微服務的網站,可以為頁面視圖創建一個單獨的主題,所有服務都以相同的消息格式向該主題寫入數據。消費者應用程序會獲得統一的頁面視圖,而無需協調來自不同生產者的數據流。
多個消費者
除了支持多個生產者外,Kafka 也支持多個消費者從一個單獨的消息流上讀取數據,而且消費者之間互不影響。這與其他隊列系統不同,其他隊列系統的消息一旦被一個客戶端讀取,其他客戶端就無法再讀取它。另外,多個消費者可以組成一個群組,它們共享一個消息流,并保證整個群組對每個給定的消息只處理一次。
基于磁盤的數據存儲
Kafka 不僅支持多個消費者,還允許消費者非實時地讀取消息,這要歸功于 Kafka 的數據保留特性。消息被提交到磁盤,根據設置的保留規則進行保存。每個主題可以設置單獨的保留規則,以便滿足不同消費者的需求,各個主題可以保留不同數量的消息。消費者可能會因為處理速度慢或突發的流量高峰導致無法及時讀取消息,而持久化數據可以保證數據不會丟失。消費者可以在進行應用程序維護時離線一小段時間,而無需擔心消息丟失或堵塞在生產者端。消費者可以被關閉,但消息會繼續保留在 Kafka 里。消費者可以從上次中斷的地方繼續處理消息。
伸縮性
為了能夠輕松處理大量數據,Kafka 從一開始就被設計成一個具有靈活伸縮性的系統。用戶在開發階段可以先使用單個 broker,再擴展到包含 3 個 broker 的小型開發集群,然后隨著數據量不斷增長,部署到生產環境的集群可能包含上百個 broker。對在線集群進行擴展絲毫不影響整體系統的可用性。也就是說,一個包含多個 broker 的集群,即使個別 broker 失效,仍然可以持續地為客戶提供服務。要提高集群的容錯能力,需要配置較高的復制系數。
高性能
上面提到的所有特性,讓 Kafka 成為了一個高性能的發布與訂閱消息系統。通過橫向擴展生產者、消費者和 broker,Kafka 可以輕松處理巨大的消息流。在處理大量數據的同時,它還能保證亞秒級的消息延遲。
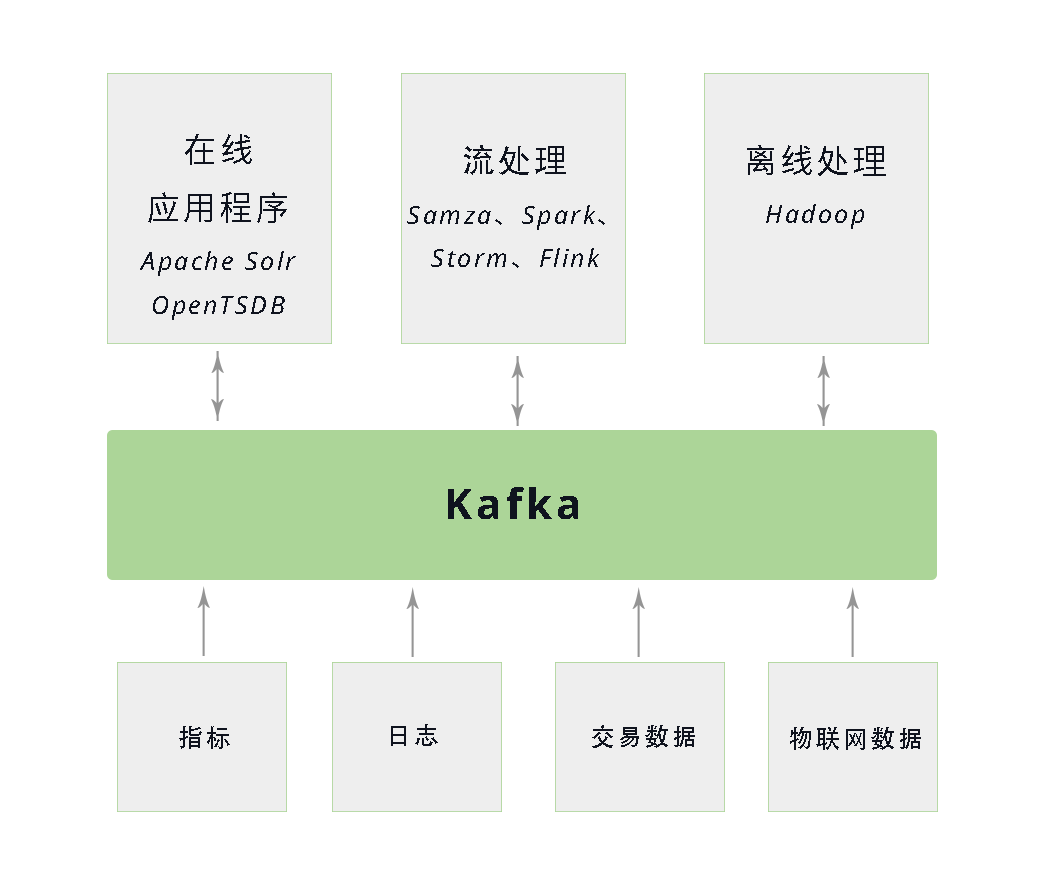
生態系統
Kafka 為數據生態系統帶來了循環系統,如圖所示。它在基礎設施的各個組件之間傳遞消息,為所有客戶端提供一致的接口。當與提供消息模式的系統集成時,生產者和消費者之間不再有緊密的耦合,也不需要在它們之間建立任何類型的直連。我們可以根據業務需要添加或移除組件,因為生產者不再關心誰在使用數據,也不關心有多少個消費者。
受歡迎程度
王國璋在 “Kafka從0.7到1.0:過去7年我們踩過哪些坑?” 這篇文章中提到如下數據:2018 年上半年,Confluent 做過一個統計,在福布斯 500 強公司里,大概有 35% 的公司都在使用 Kafka。具體到不同的行業,全世界前 10 大旅行公司中有 6 個在使用 Kafka,全世界***的 10 個銀行有 7 個在用 Kafka,***的 10 個保險公司有 8 個在用 Kafka,***的 10 個通訊公司中有 9 個在用 Kafka。在國外,Netflix、Uber、Airbnb、PayPal、The New York Times 等都是 Kafka 的重度用戶。
道且長
Kafka 一直是***的消息隊列解決方案。近年,Kafka 努力轉型為一個流數據平臺。隨著基礎設施的云化和容器化,跟容器化架構的整合,與既有框架的結合等是 Kafka 面臨的主要挑戰。在計算與存儲分離、更好地適應容器化架構方面,Pulsar 的呼聲漸高。Jesse Anderson 詳細比較了使用 Kafka 和 Pulsar 創建工作隊列的優缺點,你可以訪問jesse-anderson的網站參考這篇文章《Creating Work Queues with Apache Kafka and Apache Pulsar》。未來,不管哪個架構都需要不斷進化。
深入了解與使用
如果你想深入細致了解使用 Kafka 快速高效地構建生產者和消費者實例,使用 Kafka Streams、Kafka Connect 和 KSQL 在流處理和運維上提升 Kafka 的平臺性能,以及整個生態系統的發展趨勢,那么——
資深大數據工程師、培訓師 Jesse Anderson 在O’Reilly主辦的 AI Conference 2019北京站上主講的「Kafka 專業開發」課程值得學習。
即使你并不會編寫復雜的代碼, KSQL 也會讓你快速上手流處理。
導師:Jesse Anderson (Big Data Institute)
Topic: Professional Kafka Development
下面是一個為期兩天的培訓大綱。
周三(6月18日)
Data at scale
- Data movement concepts
- Moving data at scale
Kafka concepts
- Kafka system
- Basic concepts
- Advanced concepts
Developing with Kafka
- Using Apache Maven
- Kafka APIs
- Kafka API caveats
Advanced Kafka development
- Advanced consumers and producers
- Advanced offset handling
- Transactions
- Multithreading consumers
周四(6月19日)
Kafka and Avro
- Why serialize
- Avro and serialization formats
Kafka Connect
- Using Kafka Connect
- Importing from JDBC
- Exporting to HDFS
Kafka Streams
- Kafka Streams
- The Kafka Streams API
KSQL
- Using KSQL
Wrap-up and Q&A

參會指南
AI Conference 2019北京站正在火熱報名中,請搜索AI大會或人工智能大會,進入官網查看講師和議題詳情。