













Python大神都是這樣處理XML文件的!
最近有同學(xué)詢問如何利用Python處理xml文件,特此整理一個(gè)比較簡潔的操作手冊,供大家參閱。
首先準(zhǔn)備一個(gè)xml文件,xml中的內(nèi)容如下所示。存儲為:student.xml
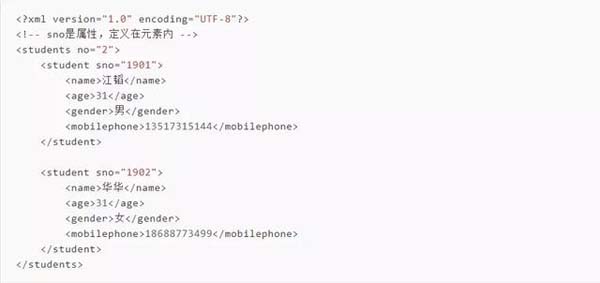
如果要獲取這個(gè)xml里面的數(shù)據(jù),我們需要利用Python里面ElementTree來進(jìn)行處理。
具體操作如下所示:
1、導(dǎo)入包(包是Python內(nèi)置自帶)

2、打開文件,并獲取根節(jié)點(diǎn)的屬性和節(jié)點(diǎn)名稱
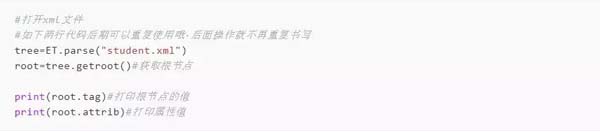
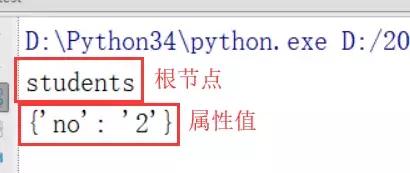
運(yùn)行代碼后,結(jié)果如下所示:
3、利用find方法獲取子節(jié)點(diǎn)(缺點(diǎn):只能根據(jù)提供的名稱獲取***個(gè)子節(jié)點(diǎn))

運(yùn)行結(jié)果如下所示:

4、利用findall方法獲取所有子節(jié)點(diǎn),返回的節(jié)點(diǎn)會存在一個(gè)列表里面

運(yùn)行的結(jié)果如下所示:運(yùn)行的結(jié)果如下所示:

5、利用findall方法獲取所有三級子節(jié)點(diǎn),返回的節(jié)點(diǎn)會存在一個(gè)列表里面

運(yùn)行結(jié)果如下所示:

6、利用遍歷的方法去直接遍歷子節(jié)點(diǎn)里面的所有元素

運(yùn)行結(jié)果如下所示:

至此我們的xml的處理已經(jīng)完全結(jié)束啦!
給大家留下一個(gè)練習(xí)題: 有一個(gè)xml的文件。內(nèi)容如下,保存為:UILibrary.xml


針對上述xml文件,要求如下:
◆ 寫一XmlUtil類
里面寫一個(gè)函數(shù):get_page
傳遞一個(gè)參數(shù)file_path
實(shí)現(xiàn)元素的讀取,返回列表形式的數(shù)據(jù),并且列表里面存儲每個(gè)page節(jié)點(diǎn)的信息;
◆ 寫一個(gè)page類
有2個(gè)屬性:page_key_word,
存儲頁面信息;uiElement存儲列表數(shù)據(jù)
◆ 寫一個(gè)UiElement類
有1個(gè)屬性:存儲列表類型的數(shù)據(jù),把每一個(gè)信息作為列表里面的一個(gè)數(shù)據(jù)。
后面也會結(jié)合WEB自動化來給大家做進(jìn)一步的分享,記得持續(xù)關(guān)注檸檬班的動態(tài)呦~















