一步一圖,帶你了解分布式架構的前世今生
目錄:
什么是分布式架構?
- 分布式架構的演進
- 分布式服務面臨的問題
- 什么是分布式架構?
分布式系統(tǒng)(distributed system)是建立在網(wǎng)絡之上的軟件系統(tǒng),它有兩個典型特點:
- 內(nèi)聚性:每個數(shù)據(jù)庫分布節(jié)點高度自治,有本地的數(shù)據(jù)庫管理系統(tǒng)
- 透明性:每個數(shù)據(jù)庫分布節(jié)點對用戶的應用來說都是透明的,看不出是本地還是遠程。
也就是說,在分布式系統(tǒng)中,用戶感覺不到數(shù)據(jù)是分布式的,不知道數(shù)據(jù)是否分割,有無副本,不知道數(shù)據(jù)存在于哪個節(jié)點上。
簡單來說:一個分布式系統(tǒng)中,一組獨立的計算機展現(xiàn)給用戶的是一個統(tǒng)一的整體,就好像是一個系統(tǒng)似的。
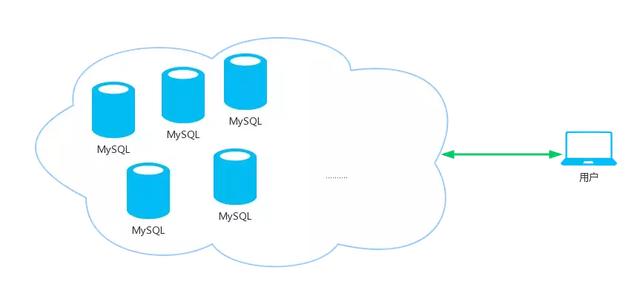
如上圖所示,分布式系統(tǒng)作為一個整體對用戶提供服務,而整個系統(tǒng)的內(nèi)部的協(xié)作對用戶來說是透明的,用戶就像是指使用一個mysql 一樣。
分布式架構的演進
(1)初始階段架構
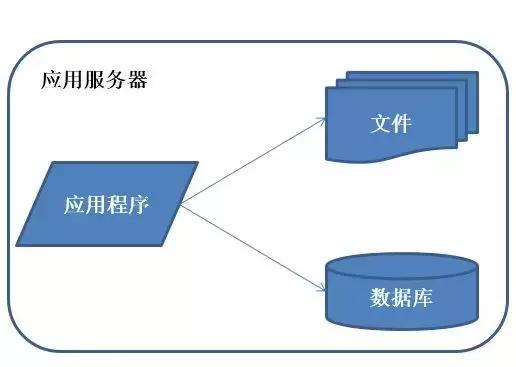
特征:應用程序,數(shù)據(jù)庫,文件等所有資源都放在一臺服務器上。
(2)應用服務、數(shù)據(jù)服務、文件服務分離
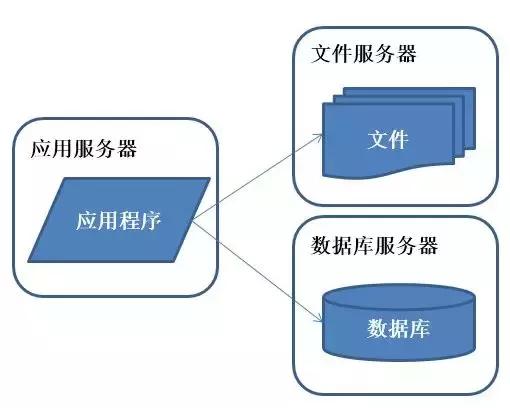
說明:好景不長,隨著系統(tǒng)訪問量的再度增加,webserver機器的壓力在高峰期會上升到比較高,這個時候開始考慮增加一臺webserver。
特征:應用程序、數(shù)據(jù)庫、文件分別部署在獨立的資源上。
(3)使用緩存改善性能
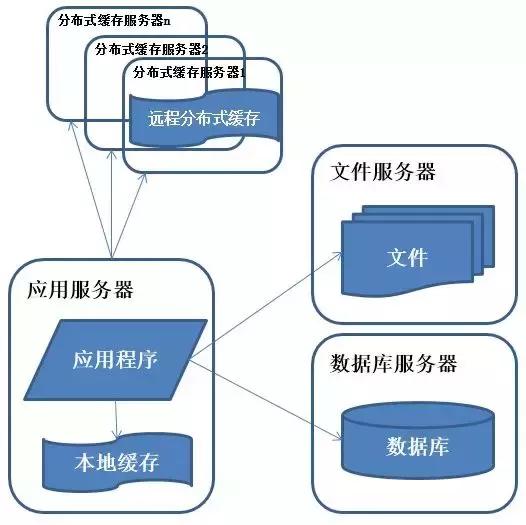
說明:系統(tǒng)訪問特點遵循二八定律,即80%的業(yè)務訪問集中在20%的數(shù)據(jù)上。
緩存分為本地緩存和遠程分布式緩存,本地緩存訪問速度更快但緩存數(shù)據(jù)量有限,同時存在與應用程序爭用內(nèi)存的情況。
特征:數(shù)據(jù)庫中訪問較集中的一小部分數(shù)據(jù)存儲在緩存服務器中,減少數(shù)據(jù)庫的訪問次數(shù),降低數(shù)據(jù)庫的訪問壓力。
(4)使用“應用服務器”集群
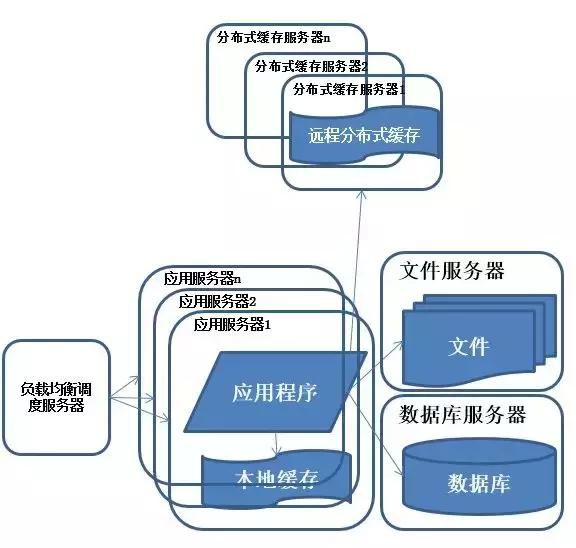
說明:在做完分庫分表這些工作后,數(shù)據(jù)庫上的壓力已經(jīng)降到比較低了,又開始過著每天看著訪問量暴增的幸福生活了。
突然有一天,發(fā)現(xiàn)系統(tǒng)的訪問又開始有變慢的趨勢了,這個時候首先查看數(shù)據(jù)庫,壓力一切正常,之后查看webserver,發(fā)現(xiàn)apache阻塞了很多的請求,
而應用服務器對每個請求也是比較快的,看來是請求數(shù)太高導致需要排隊等待,響應速度變慢。
特征:多臺服務器通過負載均衡同時向外部提供服務,解決單臺服務器處理能力和存儲空間上限的問題。
描述:使用集群是系統(tǒng)解決高并發(fā)、海量數(shù)據(jù)問題的常用手段。通過向集群中追加資源,提升系統(tǒng)的并發(fā)處理能力,使得服務器的負載壓力不再成為整個系統(tǒng)的瓶頸。
(5)數(shù)據(jù)庫讀寫分離
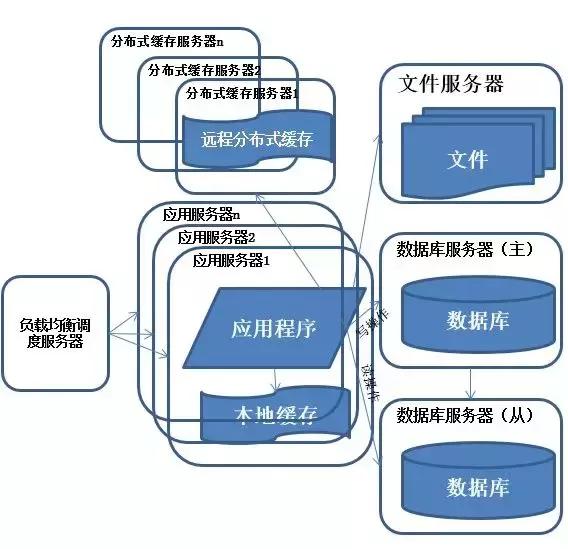
說明:享受了一段時間的系統(tǒng)訪問量高速增長的幸福后,發(fā)現(xiàn)系統(tǒng)又開始變慢了,這次又是什么狀況呢?
經(jīng)過查找,發(fā)現(xiàn)數(shù)據(jù)庫寫入、更新的這些操作的部分數(shù)據(jù)庫連接的資源競爭非常激烈,導致了系統(tǒng)變慢
特征:多臺服務器通過負載均衡同時向外部提供服務,解決單臺服務器處理能力和存儲空間上限的問題。
描述:使用集群是系統(tǒng)解決高并發(fā)、海量數(shù)據(jù)問題的常用手段。通過向集群中追加資源,使得服務器的負載壓力不在成為整個系統(tǒng)的瓶頸。
(6)反向代理和CDN加速
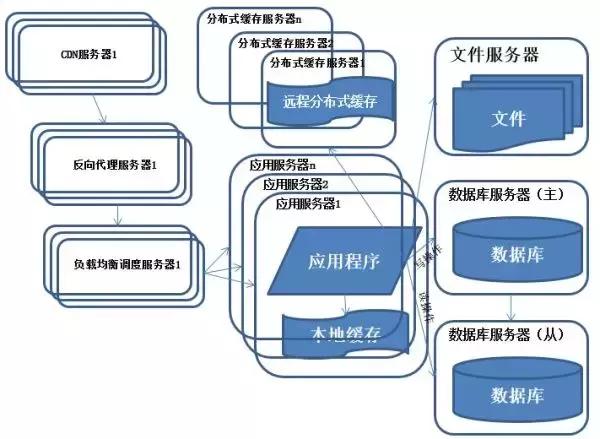
特征:采用CDN和反向代理加快系統(tǒng)的訪問速度。
描述:為了應付復雜的網(wǎng)絡環(huán)境和不同地區(qū)用戶的訪問,通過CDN和反向代理加快用戶訪問的速度,同時減輕后端服務器的負載壓力。CDN與反向代理的基本原理都是緩存。
(7)“分布式文件”系統(tǒng) 和 “分布式數(shù)據(jù)庫”
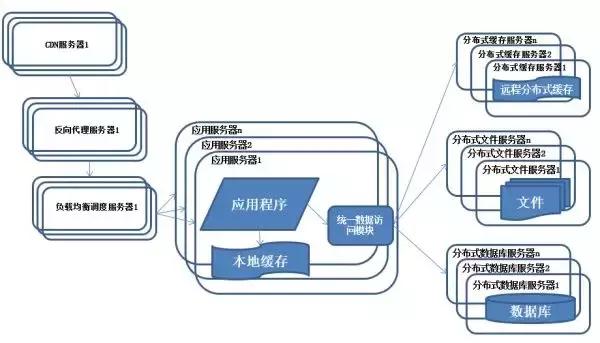
說明:隨著系統(tǒng)的不斷運行,數(shù)據(jù)量開始大幅度增長,這個時候發(fā)現(xiàn)分庫后查詢?nèi)匀粫行┞谑前凑辗謳斓乃枷腴_始做分表的工作
特征:數(shù)據(jù)庫采用分布式數(shù)據(jù)庫,文件系統(tǒng)采用分布式文件系統(tǒng)。
描述:任何強大的單一服務器都滿足不了大型系統(tǒng)持續(xù)增長的業(yè)務需求,數(shù)據(jù)庫讀寫分離隨著業(yè)務的發(fā)展最終也將無法滿足需求,需要使用分布式數(shù)據(jù)庫及分布式文件系統(tǒng)來支撐。
分布式數(shù)據(jù)庫是系統(tǒng)數(shù)據(jù)庫拆分的***方法,只有在單表數(shù)據(jù)規(guī)模非常龐大的時候才使用,更常用的數(shù)據(jù)庫拆分手段是業(yè)務分庫,將不同的業(yè)務數(shù)據(jù)庫部署在不同的物理服務器上。
(8)使用NoSQL和搜索引擎
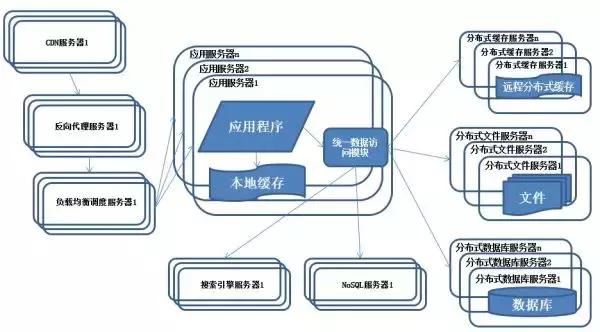
特征:系統(tǒng)引入NoSQL數(shù)據(jù)庫及搜索引擎。
描述:隨著業(yè)務越來越復雜,對數(shù)據(jù)存儲和檢索的需求也越來越復雜,系統(tǒng)需要采用一些非關系型數(shù)據(jù)庫如NoSQL和分數(shù)據(jù)庫查詢技術如搜索引擎。
應用服務器通過統(tǒng)一數(shù)據(jù)訪問模塊訪問各種數(shù)據(jù),減輕應用程序管理諸多數(shù)據(jù)源的麻煩。
(9)業(yè)務拆分
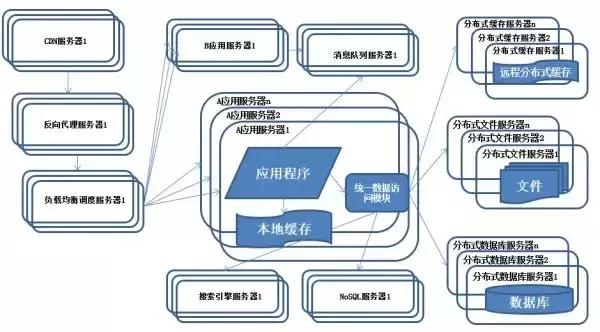
特征:系統(tǒng)上按照業(yè)務進行拆分改造,應用服務器按照業(yè)務區(qū)分進行分別部署。
描述:為了應對日益復雜的業(yè)務場景,通常使用分而治之的手段將整個系統(tǒng)業(yè)務分成不同的產(chǎn)品線,應用之間通過超鏈接建立關系,也可以通過消息隊列進行數(shù)據(jù)分發(fā),
當然更多的還是通過訪問同一個數(shù)據(jù)存儲系統(tǒng)來構成一個關聯(lián)的完整系統(tǒng)。
縱向拆分:將一個大應用拆分為多個小應用,如果新業(yè)務較為獨立,那么就直接將其設計部署為一個獨立的Web應用系統(tǒng)
縱向拆分相對較為簡單,通過梳理業(yè)務,將較少相關的業(yè)務剝離即可。
橫向拆分:將復用的業(yè)務拆分出來,獨立部署為分布式服務,新增業(yè)務只需要調(diào)用這些分布式服務
橫向拆分需要識別可復用的業(yè)務,設計服務接口,規(guī)范服務依賴關系。
(10)分布式服務
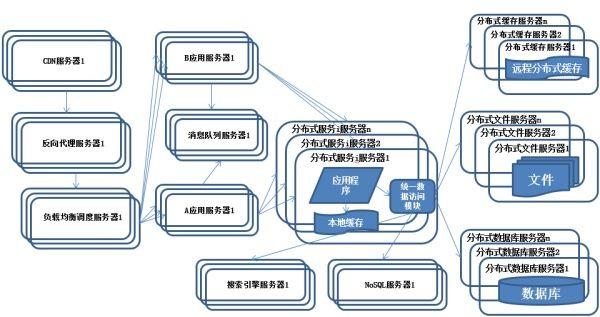
特征:公共的應用模塊被提取出來,部署在分布式服務器上供應用服務器調(diào)用。
描述:隨著業(yè)務越拆越小,應用系統(tǒng)整體復雜程度呈指數(shù)級上升,由于所有應用要和所有數(shù)據(jù)庫系統(tǒng)連接,最終導致數(shù)據(jù)庫連接資源不足,拒絕服務。
分布式服務面臨哪些問題?
- 當服務越來越多時,服務URL配置管理變得非常困難,F(xiàn)5硬件負載均衡器的單點壓力也越來越大。
- 當進一步發(fā)展,服務間依賴關系變得錯蹤復雜,甚至分不清哪個應用要在哪個應用之前啟動,架構師都不能完整的描述應用的架構關系。
- 接著,服務的調(diào)用量越來越大,服務的容量問題就暴露出來,這個服務需要多少機器支撐?什么時候該加機器?
- 服務多了,溝通成本也開始上升,調(diào)某個服務失敗該找誰?服務的參數(shù)都有什么約定?
- 一個服務有多個業(yè)務消費者,如何確保服務質(zhì)量?
- 隨著服務的不停升級,總有些意想不到的事發(fā)生,比如cache寫錯了導致內(nèi)存溢出,故障不可避免,每次核心服務一掛,影響一大片,人心慌慌,如何控制故障的影響面?服務是否可以功能降級?或者資源劣化?