一文帶你了解分布式系統中的真真假假
我們知道分布式系統中各個服務器都是通過網路進行連接的,這樣導致的結果就是你很難知道各個服務器的真實狀況,比如你判斷另外一臺服務器是否有問題的唯一辦法就是發送一個請求給他,只有收到了回應,你就認為它是好的,假如沒有收到回應,你就很難判斷對面的服務器是否有問題,因為這個沒有回應很可能是發生了網絡故障,也可能是對端機器真的出問題了。 因此,在分布式系統中我們如何來準確判斷這些問題呢? 本文就來詳細介紹相關的方法。
基于多數的(Majority)事實
很多時候我們一個節點可能不是真的有問題,比如說它正在進行 GC ,那么在 GC 的這段時間內它就不能回應任何請求,這個時候從節點本身的來看,它自己是很 ok 的,沒有任何問題。 然而從 別的節點來看,這個 GC 的節點就和出問題的節點一模一樣,發請求它不回,重試也沒有反應。 所以別的節點就會認為它是有問題的。 從這個角度來看,節點本身其實也是很難知道自己是否問題的。
現在比較流行判斷節點是否有問題的算法都是基于多數的決策,比如說我有5個節點,那么大家一起來投票,假如有超過一定數量的節點(一般來說超過半數,這里就是有三個節點)認為它有問題,那么我們就認為這個節點是真的有問題。哪怕這個節點本身是沒有問題的,但是只要有多數認為有問題,我們就認為它有問題。這里使用多數來決定是因為多數就意味著不會有沖突,因為一個系統中不可能存在兩個多數,只可能有一個。
Leader和Lock
為什么我們要去判斷一個節點是否有問題呢?事實上,在分布式系統中,有很多場景會使用到一個只能一個的概念,比如:
-
一個數據庫partition中只能有一個節點是leader
-
為了防止同時寫,只能有一個transaction或者client允許hold 某個object的lock。
-
一個用戶名只能由用戶注冊,因為它必須唯一。
這些場景都需要我們在設計的時候小心一點,比如說即使一個節點認為它自己是這個選中的唯一(比如認為它自己的leader,認為它拿到這個object的lock等等),也可能大多數別的節點認為它有問題,這個時候假如設計不好的話,就會出問題,我們來看下面這個例子:
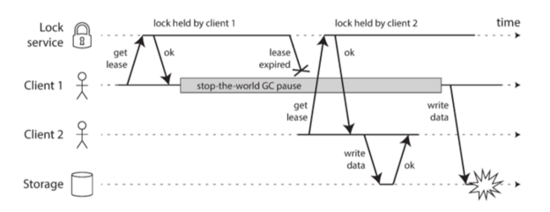
這個例子中,我們為了防止有多個client訪問同樣的數據,會要求每個client在寫之后要先抓一下鎖。這個鎖是一個lease的鎖,就是超時會釋放的。這里你可以看到Client1首先申請了這個鎖,但是很不幸,在拿到這個鎖之后,它立即發生了一個GC,而這個GC發生的時候超過了lease的timeout,這就導致這個鎖在lease超時之后被釋放了,而client2就拿到了這個鎖,做了一個更新。而client1在GC回來之后認為它是拿著這個鎖的,所以它直接也去寫了,這個時候就出現問題了。這里的問題就是GC回來之后,client1錯誤地認為它自己還是拿著鎖的。
Fencing Tokens
那么如何處理上面這種錯誤認知呢?一個常見的技術是fencing。如下圖所示:
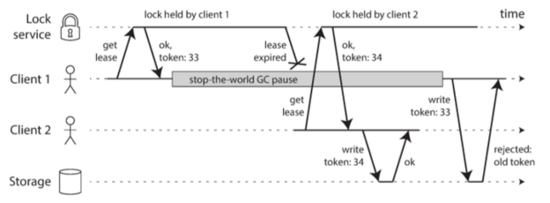
這里做的改變就是每次我們去拿鎖的時候會返回一個token值給client,這個token每次拿到鎖的時候都會遞增。這樣在client寫的時候必須同時把這個token也發送回來。這樣一來storage就可以可根據這個token來判斷是否reject舊的token的寫。
一個常見的實現方式就是使用ZooKeeper的TransactionID或者node version來作為fencingToken。
拜占庭問題(ByzantineFaults)
上文中說的FencingToken有一個前提,就是client發過來的token是它真正收到,你可以想象假如client在寫的時候發送的token是一個假的token,那么顯然fencingToken就也會有問題了。所以對于分布式系統來說,假如有節點說謊,那么問題就會變得更加復雜,我們稱這種情況為拜占庭問題,也就是我們常說的拜占庭將軍問題。
我們可以簡單認為在一個有拜占庭問題的系統中,可能會有那么一兩個節點給出的消息是不可靠的。這種不可靠可能是因為:
-
機器的memory或者CPU registry中的數據因為一些原因出了問題。比如說我們讀registry的時候出錯了,就返回一個default值,或者任意的值等等。
-
比如說有一些cheat或者attack發生。這種情況下節點就是不可信的。
當然,在現實中,我們認為這種不可信的問題它發生在比較少的節點,而不是大多數或者所有。所以假如有任何不可信的事情發生在多數節點上(比如有個code的bug,總是把收到的token加一個隨機數),那么相應的算法也是沒有辦法解決這個問題的。
減少謊言的存在
雖然我們認為有謊言的節點是很少的。但是假如我們能夠有一些機制去探測或者保護節點,那顯然會更好,比如:
-
網絡的包,我們會加一些checksum來檢測它是否正確。
-
對用戶的輸入值加一些檢查,比如看是否在一個合理的范圍內。
-
NTP的客戶端連接多個地址,然后看majority的反饋來決定真實的時間等。
系統模型和現實
我們設計了很多算法來解決各種分布式系統中的問題。而這些算法都是基于一系列的軟件和硬件對的,也就是說有很多假設,而這些依賴就是我們俗稱的系統模型。
比如說我們談到時間假設,下面這三種就是常見的系統模型:
同步模型
所謂同步模型就是指你知道網絡延時,process的暫停和時鐘的漂移不會超過某一個限制值。當然不是說沒有網絡延時,只是說你知道它不會超過一個界限。當然這種模型其實在現實中是不現實的,因為總有意料之外的延時會發生。
部分同步模型
所謂部分同步模型就是我們認為大多數時候是同步模型,就是不會超過一定的限制,但那是有時還是會超過這些限制。這個就是一個比較現實的模型。
異步模型
這種模型就是不做任何假設,甚至連時鐘多不信任,比如不是用超時。限制這種模型的限制就非常大。
除了上面的關于時間的假設,還有一個比較常見的問題就是節點失敗的假設,通常有下面這三種模型:
Crash-stop錯誤
這種模型下,算法認為一個節點出問題了,比如不響應了,就再也不會回來了。
Crash-Recovery錯誤
這種模型下,算法認為一個節點出問題了,它一會還會回來。當然什么回來不知道。這就要求節點可能需要一些能夠常見保存的介質,比如很多東西寫到磁盤中去,這樣即使crash了之后還能恢復。
拜占庭錯誤
節點有可能發生任何事情,就像我們上面說的那樣。
我們在現實中最常見的模型就是部分同步的crash-recovery錯誤。那么分布式系統的算法如何使用這些模型呢?
算法的正確性
我們判斷算法的正確性的時候,需要使用一些屬性來判斷。比如一個從小到大的排序算法,輸出中的兩個不同的元素就需要滿足前面的比后面的小。這就是一個最簡單的判斷方法。
同樣的,那么我們如何判斷分布式系統中的算法是否正確呢?我們還是以上面那個拿鎖為例,我們可以有下面這些屬性來進行判斷:
唯一性
沒有任何兩個請求得到的token是一樣的。
單調遞增
假如請求x的token是tx,請求y的token是ty,x在y前面,那么tx<ty。
可靠性
假如有節點發送了請求,那么只要不crash它最終都能收到response。
安全和活力
這里我們需要區分兩個概念,一個是安全一個是活力(Liveness)。比如上面的例子中的唯一性和單調遞增就是安全,可靠性就是活力。簡單區分這兩者就是安全一般指壞的不能發生,活力指好的最終會發生。區分這兩者有助于我們處理比較復雜的系統模型。
總結
本文詳細介紹了分布式系統中對真實的判斷和處理,希望大家能有一個大概的了解。