掌握這十大機器學習方法,你就是圈子里最靚的崽
不論是在科研中還是在工業領域,機器學習都是個熱門話題,新的機器學習方法也層出不窮。機器學習發展迅速又很復雜。對初學者而言,緊跟其發展無疑十分困難,即便是對專家們來說也非易事。
圖片來自Unsplash網站,chuttersnap攝
為揭開機器學習的神秘面紗,幫助新手學習該領域的核心概念,本文會介紹十種不同的機器學習方法,包括簡單描述和可視化等,并一一舉例說明。
機器學習算法(模型)是個表示某一問題(常為商業問題)所包含數據信息的數學表達式。設計算法是為了分析數據從而獲取有用信息。比如,在線零售商想要預測下一季度的銷售額時,就可能會用到機器學習算法,根據之前的銷售額和其他相關數據來進行預測。同樣,風車制造商可以監管重要的設備,他們給算法提供視頻數據使其在訓練之后能夠識別設備上的裂縫。
本文介紹的十種機器學習方法可以讓你對機器學習有一個整體的了解,幫助你打下相關的知識和技能基礎:
- 回歸
- 分類
- 聚類
- 降維
- 集成方法
- 神經網絡與深度學習
- 遷移學習
- 強化學習
- 自然語言處理
- 詞嵌入
最后,在介紹這些方法之前,還是先來區分一下監督學習和無監督學習這兩種機器學習類別吧。
監督學習用于在已有數據的情況下進行預測或解釋,即通過先前輸入和輸出的數據來預測基于新數據的輸出。比如,監督機器學習技術可用來幫助某服務企業預測未來一個月訂購該服務的新用戶量。
相比之下,無監督機器學習是在不使用目標變量進行預測的情況下,對數據點進行關聯和分組。換言之,它根據特征評估數據,并根據這些特征,將相似的數據聚集在一起。例如,無監督學習技術可用來幫助零售商對具有相似特征的產品進行分類,而且無需事先指定具體特征是什么。
1. 回歸
回歸是一種監督機器學習方法,在先前數據的基礎上預測或解釋特定數值。例如要想知道某房產的價值,可根據與之相似房產的定價來預測。
線性回歸是最簡單的回歸方法,用直線方程(y = m * x + b)來模擬數據集。通過計算直線的位置和斜率得到具有許多數據對(x,y)的線性回歸模型,在該直線上,所有數據點到它的距離之和最小。換言之,計算的是最接近數據中觀測值的那條線的斜率(m)和y截距(b)。
接著再來看一些具體的線性回歸例子。將建筑物的年齡、樓層數、面積(平方英尺)和墻上插入式設備的數量這些數據匯總在一起,用線性回歸方法來預測該建筑物的耗能情況(以千瓦時為單位)。由于有多種輸入值(年齡,面積等),可以選擇多變量線性回歸方法,原理和簡單的一元線性回歸一樣,但在這種情況下,由于有多個變量,最終創建出來的“線”是多維的。
下圖顯示了線性回歸模型與建筑物實際能耗的吻合程度。如果已知某建筑物的各項特征(年齡、面積等),但耗能情況未知,就可以用擬合線來對其進行估算。
注意,線性回歸還可以用來估計各個因素對于最終耗能情況的影響程度。例如,有了公式,就可以確定建筑物的年齡、面積或高度是否為最重要的影響因素。

用來估算建筑物能耗(以千瓦時為單位)的線性回歸模型
回歸技術有簡單的(線性回歸),也有復雜的(正則化線性回歸、多項式回歸、決策樹和隨機森林回歸、神經網絡等),你大可不必感到迷惑,可以先從簡單的線性回歸著手,掌握其中的技術,然后繼續學習較復雜的類型。
2. 分類
分類是另一種監督機器學習方法,這一方法對某個類別值進行預測或解釋。比如可以用分類的方法來預測線上顧客是否會購買某一產品。輸出可分為是或否,即購買者或非購買者。但分類并不限于兩個選擇。例如,可通過分類來看某一圖像中是否有汽車或卡車。在這種情況下,輸出就有3個不同值,分別為1)圖像包含汽車、2)圖像包含卡車或3)圖像既不包含汽車也不包含卡車。
邏輯回歸是分類算法中最簡單的一類,這聽起來很像一個回歸方法,其實不然。邏輯回歸是基于一個或多個輸入來估計某一事件發生概率的一種算法。
例如,邏輯回歸可基于學生的兩次考試分數來估計該生被某一大學錄取的概率。由于估計值是概率,輸出只能是介于0和1之間的數字,其中1表示完全確定。對該生而言,如果估計概率大于0.5,預測結果就是:他(她)能被錄取,如果估計概率小于0.5,預測結果則為:他(她)不會被錄取。
下圖顯示了先前學生的分數以及他們最終的錄取結果。用邏輯回歸可繪制出一條代表決策邊界的線。

邏輯回歸決策邊界線:他們能否被大學錄取?
邏輯回歸是一個線性模型,因此是新手學習分類方法入門的不錯選擇。隨著不斷的進步,就可以深入研究像決策樹、隨機森林、支持向量機和神經網絡這些非線性分類了。
3. 聚類
聚類方法的目標是對具有相似特征的觀察值進行分組或聚類,是一種無監督機器學習方法。聚類方法不借助輸出信息進行訓練,而是讓算法定義輸出。在這一方法中,只能使用可視化來檢驗解決方案的質量。
最流行的聚類方法是K均值聚類,其中“K”表示用戶選擇創建的簇的數量。(注意,選取K值時有多種技術可供選擇,比如肘部法則。)
大體上,K均值聚類法對數據點的處理步驟包括:
- 隨機選擇數據中的K個中心。
- 將每個數據點分配給最接近的隨機創建的中心。
- 重新計算每個簇的中心。
- 如果中心沒有變化(或變化很小),就結束此過程。否則,返回至第2步。(如果中心持續更改,為防止最終形成無限循環,要提前設置最大迭代次數。)
下圖將K均值聚類法應用于建筑物的數據集。圖中的每一列都表明了每棟建筑的效率。這四項測量的量涉及空調、插入式設備(微波爐,冰箱等)、家用燃氣和可燃氣體。選擇K值為2進行聚類,這樣就很容易地將其中一個聚類解釋為高效建筑群,另一個則為低效建筑群。左圖中可以看到建筑物的位置,右圖可以看到兩個輸入值:插入式設備和可燃氣體。

將建筑聚類成高效建筑群(綠色)和低效建筑群(紅色)
聚類方法中會涉及到一些非常有用的算法,比如具有噪聲的基于密度的聚類方法(DBSCAN)、均值漂移聚類、聚合層次聚類、基于高斯混合模型的期望最大化聚類等。
4. 降維
顧名思義,降維可用來刪除數據集中最不重要的數據。實踐中常會遇到包含數百甚至數千列(也稱為特征)的數據集,因此減少總量至關重要。例如,圖像中數千個像素中并不是所有的都要分析;或是在制造過程中要測試微芯片時,如果對每個芯片都進行測試也許需要數千次測試,但其實其中很多芯片提供的信息是多余的。在這些情況下,就需要運用降維算法以便對數據集進行管理。
主成分分析(PCA)是最常用的降維方法,通過找出最大化數據線性變化的新向量來減小特征空間的維數。在數據的線性相關性很強時,主成分分析法可以顯著減小數據的維度,且不會丟失太多信息。(其實,還可以衡量信息丟失的實際程度并進行相應調整。)
t-分布鄰域嵌入(t-SNE)是另一種常用的方法,可用來減少非線性維數。t-分布鄰域嵌入通常用于數據可視化,但也可以用于減少特征空間和聚類等機器學習任務。
下圖顯示了手寫數字的MNIST數據庫分析。MNIST包含數千個從0到9的數字圖像,研究人員以此來測試聚類和分類算法。數據集的每一行是原始圖像的矢量化版本(大小為28×28 = 784)和每個圖像的標簽(0,1,2,3,......,9)。注意,因此將維度從784(像素)減至2(可視化維度)。投影到二維使得能夠對高維原始數據集進行可視化。
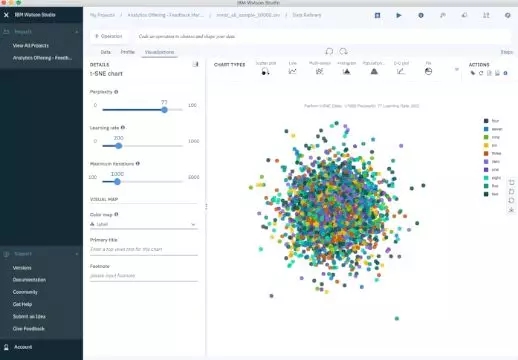
手寫數字MNIST數據庫的t-分布鄰域嵌入迭代
5. 集成方法
假設你對市面上的自行車都不滿意,打算自己制作一輛,也許會從尋找各個最好的零件開始,然后最終會組裝出一輛最好的自行車。
集成方法也是利用這一原理,將幾個預測模型(監督式機器學習方法)組合起來從而得到比單個模型能提供的更高質量的預測結果。隨機森林算法就是一種集合方法,結合了許多用不同數據集樣本訓練的決策樹。因此,隨機森林的預測質量會高于單個決策樹的預測質量。
集成方法可理解為一種減小單個機器學習模型的方差和偏差的方法。任何給定的模型在某些條件下可能是準確的,但在其他條件下有可能不準確,因此這種方法十分重要。如果換用另一個模型,相對精度可能會更低。而組合這兩個模型,就可以平衡預測的質量。
絕大多數Kaggle競賽的獲勝者都會使用集成方法。最為流行的集成算法有隨機森林、XGBoost和LightGBM。
6. 神經網絡與深度學習
與線性模型的線性回歸和邏輯回歸相比,神經網絡的目標是通過向模型添加參數層來捕獲數據中的非線性模式。下圖中,簡單神經網絡有四個輸入,一個帶有五個參數的隱藏層和一個輸出層。
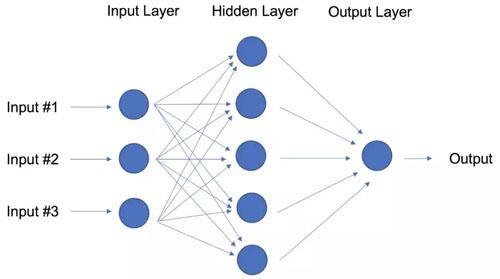
具有一個隱藏層的神經網絡
其實,神經網絡的結構十分靈活,可以構建出我們所熟知的的線性回歸和邏輯回歸。深度學習一詞來自具有多個隱藏層的神經網絡(見下圖),是對各種體系結構的一個概括。
跟上深度學習發展的步伐尤為困難,部分原因在于研究和工業方面投入了大量精力來研究深度學習,使得不斷有新方法涌現出來。

深度學習:具有多個隱藏層的神經網絡
為達到最佳效果,深度學習技術需要大量的數據,同時也需要強大的計算能力作為支撐,因為該方法是在大型體系架構中對許多參數進行自我調整。鑒于此,就不難理解為什么深度學習從業者要用配備強大圖形處理單元(GPU)功能的計算機了。
深度學習技術在視覺(圖像分類)、文本、音頻和視頻領域的應用最為成功。最常見的深度學習軟件包有Tensorflow和PyTorch。
7. 遷移學習
假設你是個零售業的數據科學家,已經花了幾個月的時間訓練高質量模型,用來將圖像分為襯衫、T恤和Polo衫這三類。新任務是建一個類似的模型,把服裝圖像分為牛仔褲、工裝褲、休閑褲和正裝褲這幾類。那么能不能把第一個模型中已建立的知識轉移到第二個模型中呢?當然可以,遷移學習可以做到。
遷移學習是指重復使用先前訓練的神經網絡的一部分,并使其適應類似的新任務。具體來說就是,使用先前任務中訓練過的神經網絡,可以傳輸一小部分訓練過的圖層,并將它們與用于新任務數據訓練的幾個圖層組合在一起。通過添加圖層,新的神經網絡就能快速學習并適應新的任務。
遷移學習的主要優點是訓練神經網絡所需的數據較少,這點尤為重要,因為深度學習算法的訓練既耗時,(計算資源上)花費又高。而且,通常也很難找到足夠的標記數據來供培訓使用。
還是回到上文的例子,假設襯衫模型中,你用了一個有20個隱藏層的神經網絡,幾次嘗試后,發現可以遷移其中的18個襯衫模型層,并能把它們與用來訓練褲子圖像的某個新的參數層相結合。此時,褲子模型將有19個隱藏層。這兩個任務的輸入和輸出不同,但一些概括與兩者都有關的信息如布料、衣服上扣件和形狀等方面的參數層可重復使用。
遷移學習正變得越來越流行,現在已經有很多固定的預訓練的模型,可以用來完成一些常見的像圖像和文本分類的深度學習任務。
8. 強化學習
試想,迷宮中有只老鼠,在試圖尋找藏在某處的奶酪。老鼠進迷宮的次數越多,它就越有可能找到奶酪。一開始,老鼠可能會隨機走動,但一段時間后,它就能意識到怎樣走可以找到奶酪。
老鼠找奶酪的過程反映了使用強化學習來訓練系統或游戲的方法。一般來說,強化學習是一種幫助代理從經驗中學習的機器學習方法。通過在設定環境中記錄操作并使用試錯法,強化學習可以最大化累積獎勵。在上述示例中,代理是老鼠,環境是迷宮。老鼠的可能操作是:前移、后移、左移或右移,奶酪則是獎勵。
如果一個問題幾乎沒有任何歷史數據,就可以選擇強化學習方法,因為它不需要事先提供信息(這一點不同于傳統的機器學習方法)。在強化學習框架中,你可以隨時了解數據。因此強化學習的應用在游戲方面的成功也就不足為奇了,特別是在國際象棋和圍棋這類“完美信息”型游戲上的應用。在游戲中,可以迅速根據代理和環境的反饋做出調整,從而使模型能夠快速學習。強化學習的缺點則是如果問題很復雜,訓練時間也許會很長。
IBM的Deep Blue曾在1997年擊敗了人類最佳國際象棋選手,同樣,基于深度學習的算法AlphaGo也于2016年擊敗了人類最佳圍棋選手。目前英國的DeepMind科技公司是深度學習研究的翹楚。
2019年4月,OpenAI Five團隊擊敗了電子競技Dota 2世界冠軍隊伍,成為了首個取得此項成就的人工智能團隊。Dota 2是一個非常復雜的視頻游戲,OpenAI Five團隊之所以選擇它,是因為當時沒有一種強化學習算法能夠在游戲中獲勝。 這個擊敗Dota 2人類冠軍隊伍的AI團隊還開發出了一個可重新定位一個塊(可以抓東西)的機器手。
強化學習可以說是一非常強大的人工智能,今后一定會取得更多更大的進步,但同時也應記住這些方法也有局限性。
9. 自然語言處理
世界上很大一部分數據和知識都以人類語言的形式存在著。你能想象在幾秒內閱讀、理解成千上萬的書、文章和博客嗎?顯然,計算機還不能完全理解人類語言,但經訓練可以完成某些任務。比如可以訓練手機自動回復短信或糾正拼寫錯的單詞,甚至可以教一臺機器與人進行簡單交談。
自然語言處理(NLP)本身不是一種機器學習方法,而是一種用于為機器學習準備文本的技術,其應用十分廣泛。想像一下:有大量各種格式的文本文檔(詞語、在線博客…等),充滿了拼寫錯誤、缺少字符和字詞多余的問題。目前,由斯坦福大學的研究人員創建的NLTK(自然語言工具包)是使用最為廣泛的一種文本處理包。
將文本映射到數字表示,最簡單的方法是計算每個文本文檔中各個單詞的頻率。在一個整數矩陣中,每行代表一個文本文檔,每列代表一個單詞。這種單詞頻率矩陣通常稱為術語頻率矩陣(TFM)。在這個基礎上,可以用矩陣上的每個條目除以每個詞在整個文檔集中重要程度的權重,從而得到文本文檔的另一種流行矩陣表示。這種方法稱為術語頻率反向文檔頻率(TFIDF),通常更適用于機器學習任務。
10. 詞嵌入
TFM和TFIDF是文本文檔的數字表示,只根據頻率和加權頻率來表示文本文檔。相比之下,詞嵌入可以捕獲文檔中某個詞的上下文。根據語境,嵌入可以量化單詞之間的相似性,反過來這又方便了對詞的算術運算。
Word2Vec是一種基于神經網絡的方法,將語料庫中的單詞映射到了數字向量。然后,這些向量可用來查找同義詞、使用單詞執行算術運算,或用來表示文本文檔(通過獲取文檔中所有詞向量的均值)。比如,假設用一個很大的文本文檔來估計單詞嵌入,并且“king”、“queen”、“man”和“woman”這四個詞也是語料庫的一部分,向量(‘word’)是表示單詞“word”的數字向量。為了估計向量(‘woman’),可以用向量執行算術運算:
向量(‘king’)+向量(‘woman’)-向量(‘man’)~向量(‘queen’)
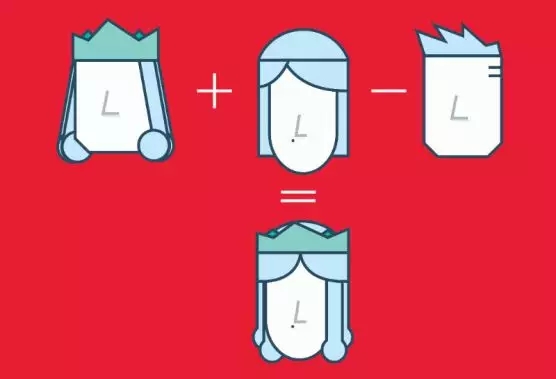
詞(向量)嵌入的數字運算
有了單詞表示,可以計算兩個單詞的向量表示之間的余弦相似性,以此發現單詞之間的相似性。余弦相似性測量的是兩個矢量的夾角。
機器學習方法可用來計算單詞嵌入,但這往往是在頂部應用機器學習算法的前提步驟。例如,假設我們能訪問數千名推特用戶的推文,并知道這些用戶中哪些人買了房子。為預測新用戶買房的概率,可以將Word2Vec與邏輯回歸結合起來。
你可以訓練單詞嵌入或使用預訓練(遷移學習)單詞向量集。若需下載157種不同語言的預訓練單詞向量,可查看FastText。