燃爆!17行Python代碼做情感分析?你也可以的
作者:IT世界圈
17行代碼跑最新NLP模型?你也可以!一臺可以上網的電腦,基本的python代碼閱讀能力,用于修改幾個模型參數,對百度中文NLP最新成果的濃烈興趣。
17行代碼跑最新NLP模型?你也可以!
- 本次作者評測所需(防嚇退)
- 一臺可以上網的電腦
- 基本的python代碼閱讀能力,用于修改幾個模型參數
- 對百度中文NLP最新成果的濃烈興趣
- 訓練模型:Senta情感分析模型基本簡介
- Senta是百度NLP開放的中文情感分析模型,可以用于進行中文句子的情感分析,輸出結果為{正向/中性/負向}中的一個,關于模型的結構細節,請查看Senta----github.com/PaddlePaddle/Paddlehub/demo/senta
- 本示例代碼選擇的是Senta-BiLSTM模型。
- 模型來源:Paddlehub簡介
- PaddleHub是基于PaddlePaddle開發的預訓練模型管理工具,可以借助預訓練模型更便捷地開展遷移學習工作。
- 本次評測中只使用了預訓練模型,沒有進行fine-tune
- 代碼運行環境:百度 AI studio
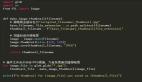
實驗代碼
- 來自paddlehub/senta_demo.py
github:https://github.com/PaddlePaddle/PaddleHub/blob/release/v0.5.0/demo/senta/senta_demo.py
- from __future__ import print_function
- import json
- import os
- import six
- import paddlehub as hub
- if __name__ == "__main__":
- # 加載senta模型
- senta = hub.Module(name="senta_bilstm")
- # 把要測試的短文本以str格式放到這個列表里
- test_text = [
- "這家餐廳不是很好吃",
- "這部電影差強人意",
- ]
- # 指定模型輸入
- input_dict = {"text": test_text}
- # 把數據喂給senta模型的文本分類函數
- results = senta.sentiment_classify(data=input_dict)
- # 遍歷分析每個短文本
- for index, text in enumerate(test_text):
- results[index]["text"] = text
- for index, result in enumerate(results):
- if six.PY2:
- print(
- json.dumps(results[index], encoding="utf8", ensure_ascii=False))
- else:
- print('text: {}, predict: {}'.format(results[index]['text'],results[index]['sentiment_key']))
詳細測評
成語情感分析
input
- test_text = [
- '滄海桑田', # 中型,世事變化很大
- '下里巴人', # 褒義,通俗的文學藝術
- '有口皆碑', # 褒義,對突出的好人好事一致頌揚
- '危言危行', # 褒義,說正直的話,做正直的事
- '鬼斧神工', # 褒義,指大自然美景
- '不贊一詞', # 褒義,不能再添一句話,表示寫的很好
- '文不加點', # 褒義,指寫作技巧高超
- '差強人意', # 褒義,大體還能使人滿意
- '無微不至', # 褒義,指細心周到
- '事倍功半', # 褒義,指不費力就有好的效果
- '事半功倍', # 貶義,指浪費了力氣卻沒有好效果
- '蠢蠢欲動', # 貶義,指要干壞事
- '面目全非', # 貶義,指大破壞
- '江河日下', # 貶義,指事物日漸衰落
- '評頭論足', # 貶義,指小節過分挑剔
- '生靈涂炭', # 貶義,指人民極端困苦
- '始作俑者', # 貶義,第一個做壞事的人
- '無所不為', # 貶義,什么壞事都干
- '無所不至', # 貶義,什么壞事都干
- '陽春白雪', # 貶義,高深不容易理解的藝術
- ]
output
- 運行耗時: 4秒480毫秒
- text: 滄海桑田, positive_prob: 0.3838, predict: negative # 錯誤
- text: 下里巴人, positive_prob: 0.7957, predict: positive
- text: 有口皆碑, positive_prob: 0.906, predict: positive
- text: 危言危行, positive_prob: 0.588, predict: positive
- text: 鬼斧神工, positive_prob: 0.657, predict: positive
- text: 不贊一詞, positive_prob: 0.9698, predict: positive
- text: 文不加點, positive_prob: 0.1284, predict: negative # 錯誤
- text: 差強人意, positive_prob: 0.0429, predict: negative # 錯誤
- text: 無微不至, positive_prob: 0.8997, predict: positive
- text: 事倍功半, positive_prob: 0.6181, predict: positive
- text: 事半功倍, positive_prob: 0.8558, predict: positive # 錯誤
- text: 蠢蠢欲動, positive_prob: 0.7353, predict: positive # 錯誤
- text: 面目全非, positive_prob: 0.2186, predict: negative
- text: 江河日下, positive_prob: 0.2753, predict: negative
- text: 評頭論足, positive_prob: 0.6737, predict: positive # 錯誤
- text: 生靈涂炭, positive_prob: 0.4661, predict: neutral # 錯誤
- text: 始作俑者, positive_prob: 0.247, predict: negative
- text: 無所不為, positive_prob: 0.5948, predict: positive # 錯誤
- text: 無所不至, positive_prob: 0.553, predict: positive # 錯誤
- text: 陽春白雪, positive_prob: 0.7552, predict: positive # 錯誤
正確率:10/20 = 50%
轉折復句情緒分析
input
- test_text = [
- '小明雖然考了第一,但是他一點也不驕傲', # 積極
- '你不是不聰明,而是不認真', # 消極
- '雖然小明很努力,但是他還是沒有考100分', # 消極
- '雖然小明有時很頑皮,但是他很懂事', # 積極
- '雖然這座橋已經建了很多年,但是她依然很堅固', # 積極
- '他雖然很頑皮,但是學習很好', # 積極
- '學習不是枯燥無味,而是趣味橫生', # 積極
- '雖然很困難,但是我還是不會退縮', # 積極
- '雖然小妹妹只有5歲,但是她能把乘法口訣倒背如流', # 積極
- '雖然我很過分,但是都是為了你好', # 積極
- '小明成績不好,不是因為不聰明,而是因為不努力', # 消極
- '雖然這樣做不妥當,但已經是最好的選擇', # 積極
- '這次雖然失敗,但卻是成功的開始', # 積極
- '雖然這道題很難,但是我相信我會把它做出來', # 積極
- '雖然爺爺已經很老了,但是他還是堅持每天做運動', # 積極
- '不是沒有美,而是我們缺少發現美的眼光', # 消極
- '雖然他們有良好的生活條件,但是浪費資源遲早會帶來惡果', # 消極
- '他不是我們的敵人,而是我們的朋友', # 積極
- '他不是不會做,而是不想做', # 消極
- '雖然那個夢想看起來離我遙不可及,但是我相信經過我的努力它一定會實現', # 積極
- ]
output
- 運行耗時: 2秒667毫秒
- text: 小明雖然考了第一,但是他一點也不驕傲, positive_prob: 0.9598,
- predict: positive
- text: 你不是不聰明,而是不認真, positive_prob: 0.0275,
- predict: negative
- text: 雖然小明很努力,但是他還是沒有考100分, positive_prob: 0.7188,
- predict: positive # 錯誤
- text: 雖然小明有時很頑皮,但是他很懂事, positive_prob: 0.8776,
- predict: positive
- text: 雖然這座橋已經建了很多年,但是她依然很堅固, positive_prob: 0.9782,
- predict: positive
- text: 他雖然很頑皮,但是學習很好, positive_prob: 0.9181,
- predict: positive
- text: 學習不是枯燥無味,而是趣味橫生, positive_prob: 0.3279,
- predict: negative # 錯誤
- text: 雖然很困難,但是我還是不會退縮, positive_prob: 0.3974,
- predict: negative # 錯誤
- text: 雖然小妹妹只有5歲,但是她能把乘法口訣倒背如流, positive_prob: 0.5124,
- predict: neutral
- text: 雖然我很過分,但是都是為了你好, positive_prob: 0.399,
- predict: negative # 錯誤
- text: 小明成績不好,不是因為不聰明,而是因為不努力, positive_prob: 0.1881,
- predict: negative
- text: 雖然這樣做不妥當,但已經是最好的選擇, positive_prob: 0.806,
- predict: positive
- text: 這次雖然失敗,但卻是成功的開始, positive_prob: 0.4862,
- predict: neutral # 錯誤
- text: 雖然這道題很難,但是我相信我會把它做出來, positive_prob: 0.3959,
- predict: negative # 錯誤
- text: 雖然爺爺已經很老了,但是他還是堅持每天做運動, positive_prob: 0.9178,
- predict: positive
- text: 不是沒有美,而是我們缺少發現美的眼光, positive_prob: 0.5614,
- predict: positive
- text: 雖然他們有良好的生活條件,但是浪費資源遲早帶來惡果, positive_prob: 0.1086,
- predict: negative
- text: 他不是我們的敵人,而是我們的朋友, positive_prob: 0.3749,
- predict: negative # 錯誤
- text: 他不是不會做,而是不想做, positive_prob: 0.1247,
- predict: negative
- text: 雖然那個夢想看起來離我遙不可及,但是我相信經過我的努力它一定會實現, positive_prob: 0.957,
- predict: positive
正確率:13/20 = 65%
具體場景情緒分析
input
- test_text = [
- '這車耗油很快',
- '這車開的很快',
- '這房間有一股死老鼠味道',
- '這房間有煙味',
- '他的發型像殺馬特',
- '這衣服機洗掉色',
- '這衣服穿多了起球',
- '這軟件容易閃退',
- '他打球的樣子像蔡徐坤',
- '這把20了',
- '這把可以打',
- '他射球的樣子像科比',
- '這房間的布置很有情調',
- '這酒讓人回味',
- '這衣服很酷',
- '他的側臉好像林峰',
- '五星好評',
- '以后會回購的',
- '性價比很高',
- '物美價廉',
- '這女生讓我心動'
- ]
output
- 運行耗時: 2秒676毫秒
- text: 這車耗油很快, positive_prob: 0.2926, predict: negative
- text: 這車開的很快, positive_prob: 0.8478, predict: positive
- text: 這房間有一股死老鼠味道, positive_prob: 0.0071, predict: negative
- text: 這房間有煙味, positive_prob: 0.2071, predict: negative
- text: 他的發型像殺馬特, positive_prob: 0.3445, predict: negative
- text: 這衣服機洗掉色, positive_prob: 0.3912, predict: negative
- text: 這衣服穿多了起球, positive_prob: 0.679, predict: positive # 錯誤
- text: 這軟件容易閃退, positive_prob: 0.0051, predict: negative
- text: 他打球的樣子像蔡徐坤, positive_prob: 0.8684, predict: positive # 錯誤
- text: 這把20了, positive_prob: 0.1695, predict: negative
- text: 這把可以打, positive_prob: 0.3503, predict: negative # 錯誤
- text: 他射球的樣子像科比, positive_prob: 0.7263, predict: positive
- text: 這房間的布置很有情調, positive_prob: 0.9519, predict: positive
- text: 這酒讓人回味, positive_prob: 0.7431, predict: positive
- text: 這衣服很酷, positive_prob: 0.9817, predict: positive
- text: 他的側臉好像林峰, positive_prob: 0.5621, predict: positive
- text: 五星好評, positive_prob: 0.9971, predict: positive
- text: 以后會回購的, positive_prob: 0.6903, predict: positive
- text: 性價比很高, positive_prob: 0.9799, predict: positive
- text: 物美價廉, positive_prob: 0.9542, predict: positive
- text: 這女生讓我心動, positive_prob: 0.956, predict: positive
正確率:17/20 = 85%
總結,三個不同類別的測評如下所示:
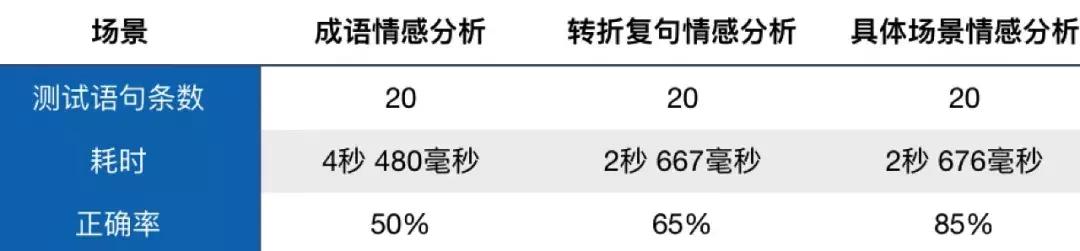
總結
1.模型計算耗時較小,使用體驗不錯。
2.成語情感分析方面,我專門挑選的是一些比較難從字面理解的,容易混淆情感的成語(比如差強人意被判定為消極),這些也是高考常考的內容。雖然最后模型正確率只有一般,但是我認為是可以接受的,適當增加成語語句作為訓練語料會使模型"更懂"中文。
大家有興趣的可以試一試一些比較容易從字面理解情感的成語,我覺得得分會比本次評測的結果要好。
3.轉折語句情感分析本身也是對模型的一種挑戰,實測效果為65分,個人覺得模型對于像“但是”,“雖然”這樣的詞語沒有足夠的attention,因為這些轉折詞背后的語義往往才是最影響整個句子的情感的,最終評分65分,個人認為模型在這方面表現一般。
4.評分最好看的是具體場景情感分析,大概預訓練語料中有大量的淘寶評價?像殺馬特 20 科比 這些小字眼是判定情感的關鍵,而模型也確實捕捉到并判斷出來了,這點比較讓我驚喜。
責任編輯:未麗燕
來源:
今日頭條